What Is RASM?
Overview
The acronym “RASM” encompasses four separate but related characteristics of a data processing, mechanical, or other physical system : reliability, availability, serviceability, and manageability. IBM is commonly noted1 as one of the first users of the acronym “RAS” (reliability, availability, and serviceability) in the early data processing machinery industry to describe the robustness of its products. The “M” was recently added to RASM to highlight the key role “manageability” plays in supporting system robustness by facilitating many dimensions of reliability, availability, and serviceability. RASM features can contribute significantly to the mission of systems for test, measurement, control, and experimentation as well as their associated business goals.
Mission Continuity
In general, RASM expresses the robustness of a system related to how well it performs its intended function. Therefore the RASM characteristics of a system are crucial to the quality of the mission for which the system is deployed. This has a great impact on both technical and business outcomes. For example, RASM functions can aid in establishing when preventive maintenance or replacement should take place. This, in turn, can effectively convert a surprise or unplanned outage into a manageable, planned outage, and thus maintain smoother service delivery and increase business continuity.
Mission Efficiency
As the number of systems increases for a given mission, the ability to simply know what assets exist, their locations, and their conditions directly affects the efficiency of a company or an organization. In addition, with many systems, it becomes increasingly more difficult to perform updates and maintenance in an orderly and error-free manner. If systems are in remote locations, such as in a tunnel or up high on a structure, the effort and cost to access them can negatively impact business operations. Strong RASM characteristics afford great efficiency in these scenarios and hence lower the cost of ownership and operation of a system.
As illustrated in Figure 1, the four components of RASM are interrelated and many times supportive and overlapping.
Contents
Reliability
In the context of instrumentation and computing systems, reliability is the probability that a system will function as expected without failure for a given duration of time in a specified environment. That is, reliability is a function of time, and it expresses the probability at a time in the future (t+1) that a system is still working, given that it was working at an earlier time (t). Less formally, “Reliability is when stuff doesn’t break.”
Availability
Availability is the probability that a system is able to perform its intended function when called upon, even in the midst of some failures. It can also mean the extent to which the system is simply operating even though some of its functions may not be. Thus a system can be available but not necessarily reliable. If a specific function of a system is failing but is corrected during operation to regain the desired function, then the system is said to be fully available though not fully reliable.
Mean time between failure (MTBF) is a common measurement parameter for managing risk, predicting reliability, predicting availability, and planning for a system’s spare parts.
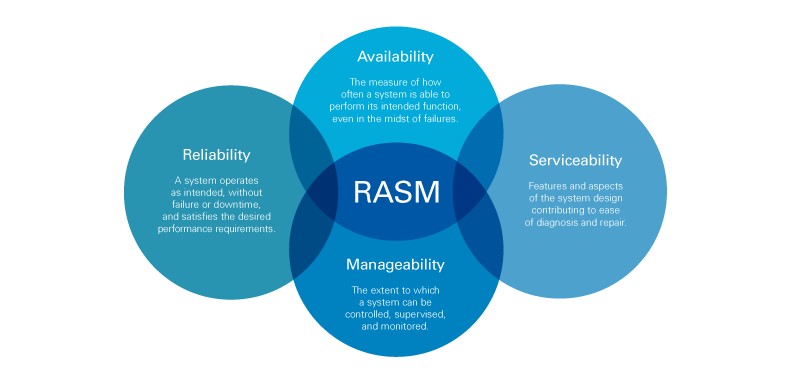
Figure 1: The Interrelated Components of RASM
Serviceability
Serviceability is the measure of, and the set of features that support, the ease and speed at which a failed system can be diagnosed and repaired. A key parameter associated with measuring serviceability is the mean time to repair (MTTR). MTTR also directly affects availability because a quick repair (low MTTR) to get the system operational again means the system is more available.
Manageability
Manageability is the measure of, and set of features that support, the ease and competence to which a system can be configured, controlled, and supervised. “Systems management,” as it is commonly called in the information technology (IT) industry, encompasses several tasks. Systems management features two fundamentally different modes: in-band and out-of-band.
In-band management occurs in the system’s main OS. It uses the system’s main production processor to implement management tasks as well as its intended application. It typically exposes a rich set of management capabilities while operating exclusively in the “fully on” system state.
Out-of-band management occurs in a separate dedicated “management processor” that is independent of the system’s main processor and OS. This typically exposes a subset of in-band management capabilities but frees up the system to focus fully on its application. Out-of-band management can operate in a variety of system states, including low power and even failure states.
Manageability: Asset discovery and monitoring, calibration, deploying and provisioning software, diagnoistics and troubleshooting, error logging, configuring system settings, updating software and firmware, security, performance monitoring, workload balancing, health alerts, etc.
RASM Examples
To illustrate RASM in the context of both IT and telecommunications systems as well as test, measurement, and control systems, consider the following scenarios summarized in Table 1.
| RASM | General Examples | Test, Measurement, and Control Examples |
|---|---|---|
| Reliability | A mainframe computer is highly reliable because it very seldom fails in a given period of time. Cell phone service is many times unreliable because dropped calls are frequent. | High-quality components in an automatic test system on a manufacturing line contribute to no unintended downtime for a year and a half. |
| Availability | An Internet router is highly available even though it experiences significant data loss because it can easily recover from the data losses. | The PCI Express interface of a DAQ board in a PXI Express system is experiencing corrupt data but has the ability to correct it, so the measurement task is uninterrupted. |
| Serviceability | A telecommunications system is serviceable because its I/O modules are blade form factors, which are quickly and easily replaceable (slide out the failed one, slide in the replacement). | The embedded controller in a test system has failed and the out-of-band diagnostics function has identified the failure. The controller is then replaced quickly and the system is back up and running. |
| Manageability | The server farm of an Internet company may be manageable becuase each server can be accessed and its software updated from a distant, remote location (with no need for local physical presence with the servers). | Software is remotely updated to the same level on all 15 test/measurement systems. This event is automatically logged in the event log of each system along with the current software version information. |
Table 1: Example Scenarios for RASM
Additional Resources
Redundant System Basics - What is System Redundancy?
[1] Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems: Design and Evaluation, 3rd ed. (A K Peters/CRC Press, 1998), 508.