What Is Manageability?
Overview
The acronym “RASM” encompasses four separate but related characteristics of a functioning system: reliability, availability, serviceability, and manageability. IBM is commonly noted [1] as one of the first users of the acronym “RAS” (reliability, availability, and serviceability) in the early data processing machinery industry to describe the robustness of its products. The “M” was recently added to RASM to highlight the key role “manageability” plays in supporting system robustness by facilitating many dimensions of reliability, availability, and serviceability [7]. For example, manageability functions can aid in establishing when preventive maintenance or service should take place. This, in turn, can effectively convert a surprise or “unplanned” outage to a manageable “planned” outage, and thus maintain smoother service delivery and increase business continuity and availability. In general, manageability is the measure of and set of features that support the ease, speed, and competence with which a system can be discovered, configured, modified, deployed, controlled, and supervised.
As the number of systems increases for a given mission, the ability to simply know what assets exist, where they are, and their condition directly affects the efficiency of a company or organization. This is especially true with the proliferation of Big Analog DataTM [5] solutions, for which many networked systems make it increasingly difficult to perform updates and maintenance in a timely and error-free manner. In addition, if systems are in remote locations, such as in a tunnel or up high on a structure, the effort and cost to access them can negatively impact business operations. Strong manageability characteristics afford great efficiency in these scenarios and lower the cost of ownership and system operation.
Contents
- Manageability Functions
- Operating Modes of Manageability
- Manageability for Each Phase of Life
- Phase 1: Pre-Life
- Phase 2: Early Life
- Phase 3: Useful Life
- Phase 4: Wear Out
- Summary
- Additional Resources
Manageability Functions
The main functions of systems manageability can be portioned into four broad categories, as depicted in Figure 1. Controlled with management consoles, these functions interface to the managed systems logically via APIs and physically via management networks.
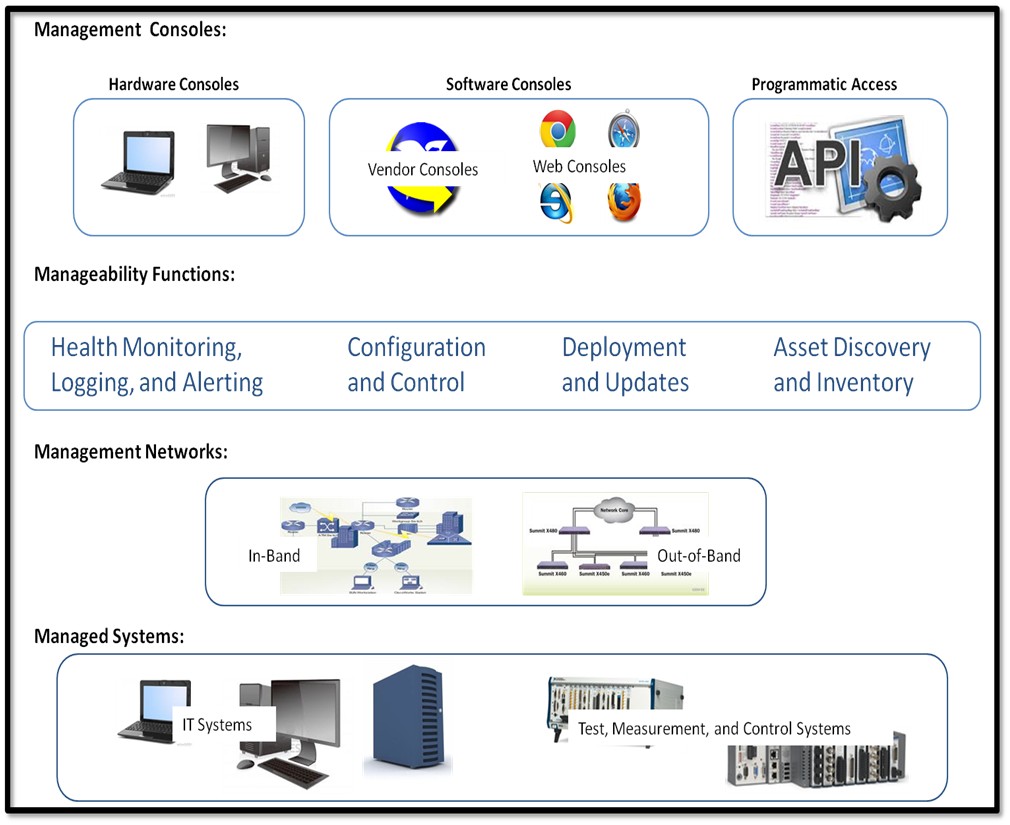
Figure 1. Systems Manageability Infrastructure
Manageability functions fall into four broad categories:
- Health Monitoring, Logging, and Alerting—These functions keep track of the system’s ability to perform its function. Logging generates a history of activity, which can provide valuable information associated with a failure. Alerting schemes vary from predictive warnings, based on diagnostics or hardwired interrupts, to alarms sounding when a failure has occurred or a monitored parameter (such as voltage or temperature) has exceeded a threshold. In addition, alerts can be employed when a system has been compromised or attacked by hackers or via malware, viruses, etc.
- Configuration and Control—Setting up and configuring the system correctly is key for optimal performance and availability. Some systems need regular or real-time control, so access to the right “nobs” and actuators is a fundamental requirement. A key set up and control activity is configuring a system for security, ensuring authorized access and protection against hostile activity.
- Deployment and Updates—Efficient and sometimes automatic deployment of system resources such as a software stack is especially valuable when there are many systems to manage. This is executed during the first-time installation of systems as well as during the patches, performance, and feature updates of the system’s useful life.
- Asset Discovery and Inventory—When many systems are networked together or systems are remote, their accurate and timely discovery (usually upon initial installation or after a software or firmware reimage) becomes even more important. And, an accurate and automated inventory system is essential to asset management, cost control, and replacement of systems.
In the test, measurement, and control industry, a PXI system [8] can be deployed to accomplish high-speed, high-quality measurements and analysis. Thus manageability features can help maximize the uptime, test speed, and ease of maintenance. Similarly, while embedded systems [9] serve data acquisition and embedded control applications, manageability features ensure that the health and status of these systems can be remotely monitored and controlled.
Operating Modes of Manageability
Manageability functions operate in two modes: in-band and out-of-band. In-band manageability is a scope of operation in the context of, with awareness by, and with dependence on the main OS used for the system’s primary mission. That is, manageability operates in the “fully on” system state. Out-of-band manageability is a scope of operation independent of the main OS and other components used for the system’s primary mission. Out-of-band manageability can therefore operate in a variety of system states, including low-power states. Rigorous out-of-band management involves a dedicated management network, as depicted in Figure 1.
In-band management encompasses a main system controller or CPU complex and its operating system (OS) to manage a system. The main OS provides the run-time environment for the underlying management infrastructure, management software, device drivers, configuration frameworks, and so on. Since a full OS is available, in-band management can generally support a rich set of manageability features at a lower cost. Although in-band management facilitates a variety of functions at many times, it cannot manage a system if the main power is off or if the main OS or CPU complex is not operational. In cases like these, out-of-band management is required, which provides a more rigorous manageability environment for a system.
Out-of-band management encompasses a separate dedicated management or service processor that runs independently of the system’s main system CPU complex and OS. Generally with out-of-band management, an external management console (workstation) manages the system remotely via a network interface attached to a management processor or /service processor. The management/service processor is available in all system power states, including low-power (“off”) system states, and is capable of managing the system independently of the main system controller and OS state. Rather than depending on the main system CPU complex as required for in-band management, out-of-band management can consider the main CPU complex as just another entity in the system in which to manage. This avoids the “fox watching the henhouse” effect associated with in-band management. In addition, out-of-band management keeps manageability functions off the main CPU complex so it can be fully dedicated to the system’s mission, unencumbered by management tasks. This is particularly effective in real-time and high-speed sensitive measurement and control applications.
Manageability for Each Phase of Life
Consider the “bathtub curve” in Figure 2. This curve, named for its shape, depicts the failure rate over time of a system or a product. A product’s life can be divided into four phases: Pre-Life, Early Life, Useful Life, and Wear Out. During each phase, different considerations must be made to manage the system, avoid or service failures, and replace systems as needed.
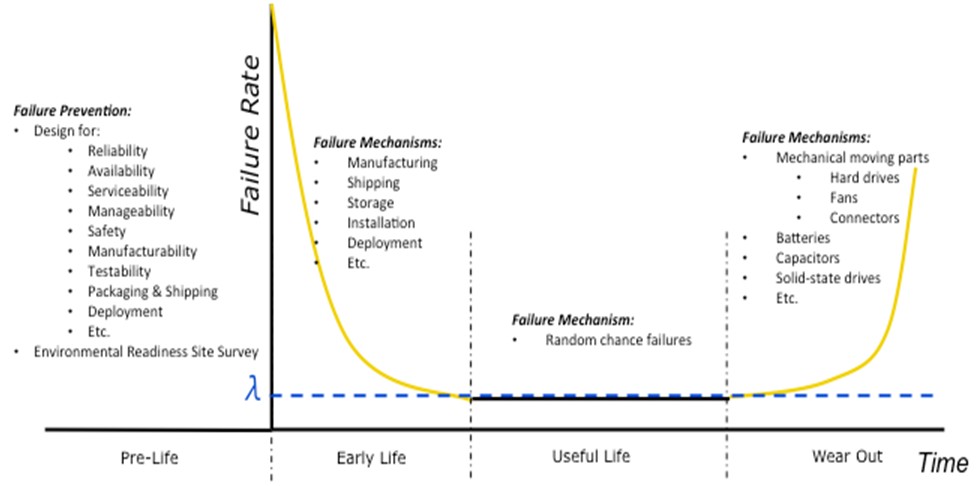
Figure 2. Bathtub Curve
Phase 1: Pre-Life
“A goal without a plan is just a wish.”
–Antoine de Saint-Exupery
The focus during Pre-Life is planning and design. System design and accessibility have a great impact on the ease and cost of owning and managing the system. To design appropriately, you must understand key aspects of the system’s usage models such as those in the following list. This list is not comprehensive but contains some of the more prevalent considerations.
- Most likely failure modes and the required system availability
- Amount of manageability task interference with the system’s mission vis-à-vis in-band versus out-of-band management
- Level of real-time system control and automated operation needed for system’s mission
- Number of systems networked together and the network topology
- Amount and type of software and upgrade frequency
- System refresh or replacement strategy
- Management console and user interface requirements
- Physical location of the system and the surrounding environmental factors
The environment in which the system operates can have a great impact on its manageability. For example, if the system performs in an environment hostile to electronic equipment, it may be difficult to accurately capture and monitor all the needed environmental parameters such as temperature, humidity, or power measurements. Or, diagnostics and monitoring may be inordinately burdensome, which negatively affects the system’s mission or personnel costs. Conducting an Environmental Readiness Site Survey (ERSS) before system installation and deployment is an effective way to evaluate many of these factors and help you understand the impact of the environment on the required manageability.
Phase 2: Early Life
Early Life manageability typically involves system installation, deployment, and migration to steady-state operation as soon as possible. After systems are physically installed and connected, management tasks such as discovery, configuration, software deployment, calibration, and setting up asset inventory and monitoring take place.
Since the failure rate in Early Life is generally higher than that seen in the Useful Life phase, a focus on testing and monitoring the system’s functions and environmental factors is needed. Prior to going live in production, it is essential to conduct thorough end-to-end testing of both the system’s mission-related functions and its fundamental ability to be monitored and managed. Good planning and management tools, such as remote access and error logs, ensure such testing is both thorough and efficient. This reduces the “integration risk” of the solution and the system’s “time to value.” Both these benefits can greatly add to customer satisfaction.
Phase 3: Useful Life
Once steady-state or normal operation in Useful Life has begun, key manageability functions such as health monitoring, error logging, and inventory and status management become routine. In addition, inevitable software and hardware upgrades need to be managed and then executed via serviceability functions.
Learn more about serviceability
Since failures in Useful Life are considered to be “random chance failures,” and they typically yield a constant failure rate, manageability functions can be tailored for them. That is, diagnostics and preventive maintenance schedules are developed in consideration of failure rates, failure modes, and the replacement strategy.
Robust manageability tools also include failure alerts tied to health monitoring via “watchdog” functions, vigorous self-tests, and prognostics tools.
Your management solution should also provide a mechanism to perform periodic software updates while the targets are in the field to address issues found after the early life and/or to provide ongoing security updates. In addition, minor updates can be applied to improve the functionality or effectiveness of the system over its useful life. The software update mechanism should consider the state of the target and severity of the update before applying it to the target. Critical updates may need to stop the current operation and be immediately applied, while minor updates should only occur during planned downtime or maintenance periods to maximize availability. In addition, the update mechanism should be able to maintain the existing configuration of the target to limit the need for anyone to reprovision the system.
The system may require ongoing control functions or hardware calibration during its mission. For example, a test system may need to adjust the timing of a measurement or repeat or cease a particular test. Such control routines executed during Useful Life can be manual, automated, or a combination of both. These control actions themselves must also be monitored to ensure they are functioning correctly and achieve their intended results.
Phase 4: Wear Out
The Wear Out phase begins when the system’s failure rate starts to rise above the “norm” seen in the Useful Life phase. This increasing failure rate is due primarily to expected part wear out. Usually mechanical moving parts such as fans, hard drives, switches, relays, and frequently used connectors are the first to fail. However, electrical components such as batteries, capacitors, and solid-state drives can be the first to fail as well. Most integrated circuits (ICs) and electronic components last about 20 years [6] under normal use within their specifications.
During the Wear Out phase, manageability and serviceability functions can be a great burden. Hence this phase is typically characterized by a time of increased service and repair, followed by formal replacement of the system. As systems require replacement, key management functions include preserving the retiring system’s state for migration, removing the system from asset inventory, and adding the new systems (assets) to the inventory. In addition, preserving the systems error, failure, and service history, captured by good management tools in Early and Useful Life, can be valuable in preparing a management strategy for the next generation of systems.
Summary
Manageability is an important supplement to the traditional elements of reliability, availability, and serviceability. Incorporating manageability features into your test, measurement, or control system provides a number of benefits throughout the system’s life. Consider the following when implementing manageability.
- Planning and design in Pre-Life is an opportunity to focus on manageability issues and ensure internal system sensors, diagnostics, and network connectivity for management consoles.
- Understanding system and subsystem deployment location and level of access is critical.
- Out-of-band management keeps manageability functions off the main OS and CPU complex, so the system can be fully dedicated to its mission, unencumbered by management tasks.
- Manageability can improve the isolation of faulty components, which greatly affects the mean time to repair (MTTR) and, therefore, the serviceability and ultimate availability of the system.
- Maintaining error logs, asset inventories, and service histories is valuable for creating the manageability strategy for replacement systems.
Additional Resources
View the entire RASM white paper series
[1] “Design and Evaluation,” 3rd ed., by Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems (A K Peters/CRC Press, 1998).
[2] “The Certified Reliability Engineer Handbook,” 2nd ed., by Donald W. Benbow and Hugh W. Broome, ASQ Quality Press, Milwaukee Wisconsin, 2013, ISBN 978-0-87389-837-9, Chapter 13, page 227.
[3] “Reliability Theory And Practice,” by Igor Bazovsky, Prentice-Hall, Inc. 1961, Library of Congress Catalog Card Number: 61-15632, Chapter 5, page 33.
[4] “Practical Reliability Engineering,” 5th ed., by Patrick D. O’Conner and Andre Kleyner, Wiley, ISBN 978-0-470-97981-5, Chapter 16, page 410.
[5] “The Moore’s Law of Big Data”, http://zone.ni.com/devzone/cda/pub/p/id/1649
[6] “Telcordia Technologies Special Report, SR-332,” Issue 1, May 2001, Section 2.4, pages 2-3.
[7] "What is RASM?", http://www.ni.com/white-paper/14410/en
[8] "What is PXI?", http://www.ni.com/pxi/whatis/
[9] "What is CompactRIO?", http://www.ni.com/compactrio/whatis/ and "What is NI CompactDAQ?", http://www.ni.com/compactrio/whatis/