TestStand中混合并行测试系统的设计 - Part II
主要软件: TestStand
主要软件版本: 2012
主要软件修正版本: N/A
次要软件: LabVIEW Development Systems>>LabVIEW Professional Development System
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||
问题:
NI TestStand做为测试管理软件,提供现成即用的、完全可自定义的测试执行管理环境,用于管理、控制并运行您的测试序列。通过TestStand可以管理几乎所有编程环境开发的程序代码,包括NI LabVIEW、NI LabWindows/CVI、VB和VC++。另外它还可以运行编译成DLL (动态连接库) 的测试代码、ActiveX服务器或EXE。
TestStand的一大特点是它可以实现并行测试。使用TestStand自带的并行测试模型Parallel Process Model和Batch Process Model很容易就可以实现多个待测件(UUT)的并行执行,缩短测试时间,大大提高产线的测试效率和产能。为了完成多个UUT的测量,需要给UUT配置相应的测试硬件设备。硬件设备的配置有三种情况:
1)所有UUT拥有各自独立的测试设备:在条件允许的情况下,可以给每个UUT都配置独立的测试设备,这样每个UUT都可以单独进行测试,它们是完全并行的;
2)所有UUT都共享同一套测试设备:有些测试设备非常昂贵,一般会采取多个UUT共享同一套设备的方式,而通过开关进行切换。采用并行测试架构,尽量使昂贵的测试设备处于运转状态,减少设备闲置时间,提高测试效率;
3)在实现应用中,很多情况是这样子的:在整套系统中,共享其中昂贵的设备,而其它测试项用到的测试设备,是可以给每个UUT独立配置的。这样一种混合的模式,该如何来执行并行测试,实现效率的最优化呢?
解答:
这是混合并行测试系统的设计文档的第二部分:
在第一部分我们做了一系列的铺垫,清楚并行测试该如何在软件中来设置。接下来就来分析我们一开始抛出的案例:在整套系统中,共享其中昂贵的设备,而其它测试项用到的测试设备,是可以给每个UUT独立配置的。这样一种混合的模式,该如何来执行并行测试,实现效率的最优化呢?
还有一些问题是我们需要考虑的:如果UUT的配置参数是不一样的,如何解决不同UUT加载不同参数;UUT结果的收集如何完成,如何将不同UUT的结果对号入座;共享的硬件资源在使用时如何避免资源冲突;独立的硬件资源和共享的硬件资源,它们之间如何调配,实现测试性能的最优化。
当执行并行测试时,TestStand自动给每个UUT分配一个索引号,该索引号存储在RunState.TestSockets.MyIndex变量中。通过这个变量,我们可以将UUT的参数设置(参数导入)、结果收集等都进行一一对应。先来看简单的例程:RunState_TestState_Myindex.seq。它采用的是Batch Process Model,我们用了一条Select语句,Select语句的判断条件即为RunState.TestSockets.MyIndex。对于UUT0,我们只执行Action 0,而UUT1则只执行Action 1。
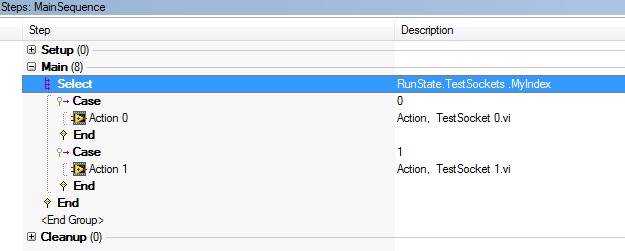
图8. RunState_TestState_MyIndex.seq
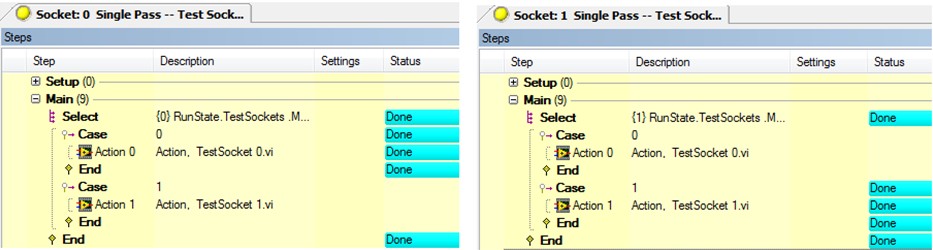
图9. RunState_TestState_MyIndex.seq执行结果
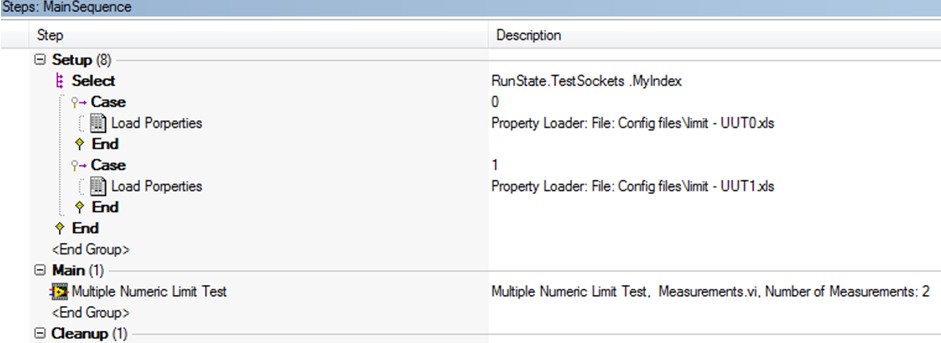
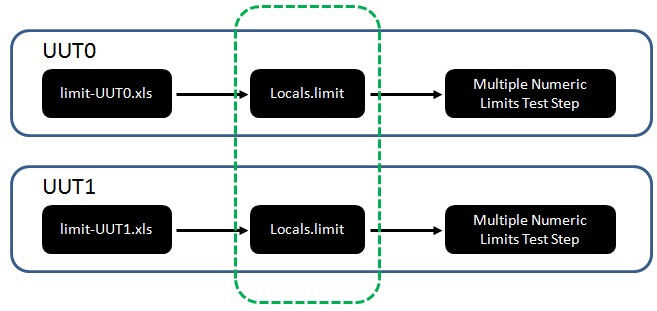
对于多UUT的测试,如果UUT都是相同的,配置参数也是一样的,那对于开发人员而言,当然会简化一些工作量。但是如果UUT的配置参数是不一样的,如何解决不同UUT加载不同参数?我们把不同的UUT的参数设置各自保存在不同的文件中,然后借鉴上面的处理方法,使用RunState.TestSockets.MyIndex变量,选择性的加载文件。参考例程:Parallel Multi Limit Loading.seq。Parallel Multi Limit Loading.seq文件使用Batch Process Model。以UUT0为例,其加载limit-UUT0.xls文件,将读取的值赋给TestStand中的局部变量locals.limit。在Main Group中,locals.limit做为Multiple Numeric Limit Test Step的limit参数。这里要理解的一点是,虽然UUT0和UUT1从文件中读取数据后都写入locals.limit变量中,但是在Batch Process Model中,每个UUT都是在新的执行中(Run in New Execution)运行,所以是有自己独立的数据空间的。因此相当于每个UUT都有一份locals.limit的独立拷贝。明白了这一点,对于参数的加载或者说是输入,我们只要创建相应的变量即可导入,对于测试结果的导出或存储,道理就是一样的了。(对于参数的加载,还有一种方式是使用二维数组,数组的每一行或每一列对应于一个UUT的参数)
采用并行测试一个潜在的问题是:当多个线程同时对一个硬件资源进行访问时,必然会导致硬件资源冲突。解决冲突的办法就是采用Lock & Unlock。只要保证Lock了之后及时Unlock,就不会有Deadlock的潜在危险。或者也可以使用AutoSchedule,关于AutoSchedule的介绍,可以参考链接Benefits of Parallel Testing中的Sample Parallel Test Results章节。
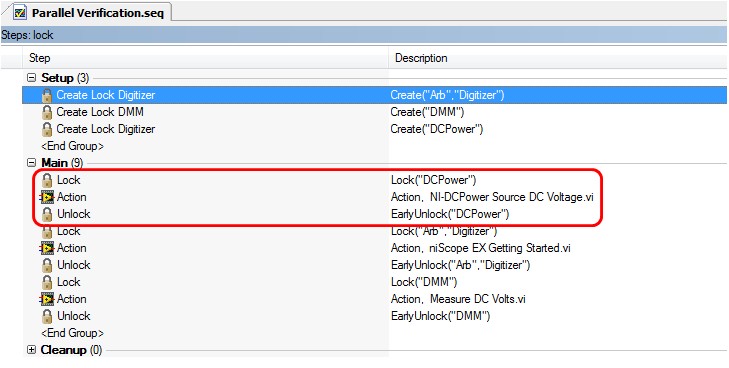
图12. Lock & Unlock
我们再来看一个简单的例程:Parallel Verification.seq。这里我们模拟4个UUT的并行测试,每个UUT共有2个测试项。其中测试项1用的是独立的硬件设备,而测试项2用的是共享的硬件设备。Parallel Verification.seq文件采用的是Batch Process Model,当然如果现实情况中4个UUT可以完全独立,我们可以选择Parallel Process Model。
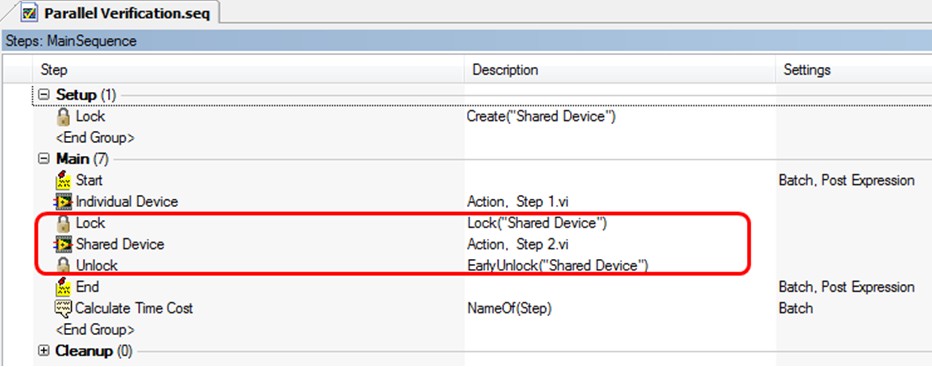
图13. Parallel Verification.seq
由于采用的是Batch Process Model,它会限制所有的UUT同时开始测试和同时结束测试,但具体的测试项之间是没有同步要求的,如前面图5所示。除非采用Synchronization Section,如前面图6所示,或者强制Lock,否则UUT在完成测试项的过程中其实是完全独立的,并行的。
在这个例子中,“Individual Device” Step没有使用Synchronization Section,因此所有UUT执行该Step是完全独立的,这也符合拥有独立硬件时的配置情况,任意一个UUT结束完该测试后,就可以紧接着进行“Shared Device”的测试。在这里我们采用的都是仿真,模拟实际的测试场合,“Individual Device”Step的测试完成的进度会有先有后,因此会看到,当UUT1还在执行“Individual Device”时,UUT0率先完成该测试并且不需要等待,直接进入“Shared Device”Step测试。
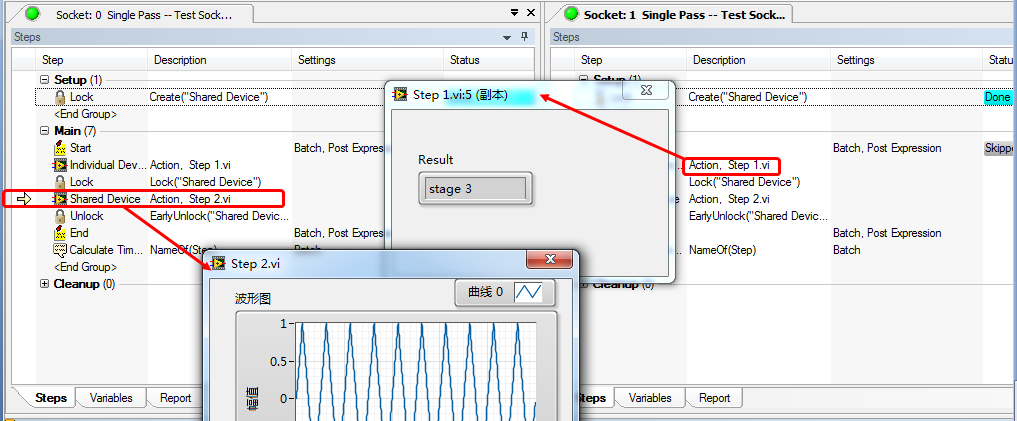
图14. Parallel Verification.seq执行效果
到这里的时候,我们所思考的问题还没有给确切的答案:既有共享设备,又有独立设备,该如何设计实现测试效率的最优化。但这个问题,具体一些,就是如何合理的配置并实施并行测试,在前面介绍了这么多,有理由相信,其实我们已经知道怎么做了。在图15 Main Group中,我们把拥有独立设备的测试项放在前面,并且所有的Step都不做额外的Synchronization Section同步,这样先运行完的UUT就可以不用等待,紧接着进行共享设备相关的测试。额外的优化可能包括:将Lock & Unlock替换为AutoSchedule;将某个Individual Device Step改为Sequence Call Step;将某个Shared Device Step改为Sequence Call Step,这样可以是Top-level Sequence变得更简洁;如果UUT可以彼此独立,那么选择Parallel Process Model;如果任意的Step有同步要求,请添加Synchronization Section。
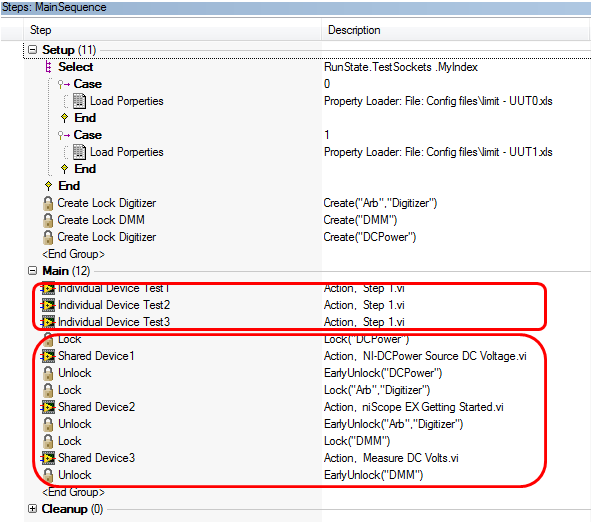
图15. 混合并行测试系统
相关链接:
1. Benefits of Parallel Testing:
2. When to Run a Sequence in a New Execution versus in a New Thread:
3. Parallel Testing With TestStand:
4. Importing and Exporting Arrays
5. How Do I Specify a Particular Process Model for a Specific Sequence File?
6. What is a Process Model?
附件:
|
|
||||||||||||||||||||||||||||||||||||||||||||||||||
报告日期: 11/30/2012
最近更新: 11/30/2012
文档编号: 63T877K