VI-Speicherbedarf
- Aktualisiert2025-08-27
- 43 Minute(n) Lesezeit
LabVIEW übernimmt viele Detailaufgaben, die Sie in einer befehlsorientierten Programmiersprache selbst ausführen müssten. Eine der größten Herausforderungen befehlsorientierter Programmiersprachen stellt die Arbeit mit Speicher dar. Bei befehlsorientierten Programmiersprachen ist der Programmierer für die Zuweisung von Speicher (vor der Nutzung) und der anschließenden Freigabe zuständig. Der Programmierer muss auch aufpassen, dass der zugewiesene Speicher nicht überschritten wird. Die fehlende oder mangelnde Zuweisung von Speicher ist eines der größten Probleme bei der Arbeit mit befehlsorientierten Sprachen. Die Fehlersuche ist in solchen Fällen besonders schwierig.
Bei der LabVIEW-Datenflussprogrammierung entfallen viele der Schwierigkeiten bezüglich des Speichermanagements. In LabVIEW wird weder Speicher für Variablen reserviert noch werden diesem Werte zugewiesen. Stattdessen erstellen Sie ein Blockdiagramm mit Verbindungen, die das Weiterleiten der Daten symbolisieren.
Funktionen, mit denen Daten generiert werden, übernehmen die Zuweisung von Speicher für die Daten. Werden Daten nicht länger benötigt, so wird der entsprechende Speicher wieder freigegeben. Wenn Sie neue Daten in ein Array oder einen String einfügen, wird automatisch mehr Speicher reserviert.
Dieses automatische Speichermanagement ist einer der größten Vorteile von LabVIEW. Die Automatisierung dieser Vorgänge heißt aber auch, dass Sie weniger Kontrolle darüber haben. Arbeitet Ihr Programm mit großen Datensätzen, so ist es wichtig zu wissen, wann Speicherzuweisungen stattfinden. Wenn Sie die Prinzipien der Speicherzuweisung verstehen, können Sie den Speicherbedarf Ihrer VIs erheblich reduzieren. Wenn Sie verstehen, wie sich der Speicherbedarf eines VIs verringern lässt, können Sie auch die Ausführungsgeschwindigkeit Ihrer VIs erhöhen, da das Belegen von Speicher und damit verbundene Kopieren der Daten sehr viel Zeit beansprucht.
Virtueller Speicher
Durch die Arbeit mit virtuellem Speicher können Betriebssysteme Programmen mehr Speicher zur Verfügung stellen, als im physischen RAM vorhanden ist. Das Betriebssystem partitioniert den physischen RAM in Blöcke, sogenannte Seiten. Wenn ein Programm oder Prozess einem Speicherblock eine Adresse zuweist, verweist die Adresse nicht auf eine Stelle im RAM, sondern auf Speicher auf einer Seite. Das Betriebssystem kann diese Seiten zwischen dem RAM und der Festplatte austauschen.
Wenn eine Anwendung oder ein Prozess auf einen bestimmten Block oder eine Seite des Speichers zugreifen muss, die sich nicht im RAM befindet, kann das Betriebssystem eine Seite des RAM, die nicht verwendet wird, in die Festplatte verschieben und durch die angeforderte Seite ersetzen. Das Betriebssystem speichert die Seiten des Speichers und wandelt virtuelle Adressen für Seiten in Adressen im physischen RAM um, wenn eine Anwendung oder ein Prozess auf diesen Speicherabschnitt zugreifen muss.
In der folgenden Abbildung wird dargestellt, wie zwei Prozesse die Seiten im und außerhalb des physischen RAMs tauschen können. In diesem Beispiel werden Prozess A und Prozess B gleichzeitig ausgeführt.
| | ||
| 1 Prozess A | 3 Prozess B | 5 Seite des Speichers für Prozess B |
| 2 physischer RAM | 4 Seite des virtuellen Speichers | 6 Seite des Speichers für Prozess A |

Da sich die Anzahl der Seiten, die von einer Anwendung oder einem Prozess verwendet werden, nach dem verfügbaren Platz auf der Festplatte und nicht nach dem verfügbaren physischen RAM richtet, kann eine Anwendung mehr Speicher verwenden als tatsächlich im RAM zur Verfügung steht. Die Größe der Speicheradressen, die von einer Anwendung verwendet werden, beschränkt den virtuellen Speicher, auf den die Anwendung zugreifen kann.
LabVIEW - Belegung virtuellen Speichers
LabVIEW (32 Bit) arbeitet mit 32-Bit-Adressen und ist ist auf umfangreiche Adressen ausgelegt .
LabVIEW (64 Bit) kann je nach Windows-Version auf bis zu 8 TB oder 128 TB virtuellen Speicher zugreifen. Die tatsächliche Größe des virtuellen Speichers, auf die LabVIEW (64 Bit) zugreifen kan, hängt außerdem von der Größe des physischen RAM und der maximalen Paging-Dateigröße ab.
Speichermanagement von VI-KomponentenEin VI besteht aus folgenden vier Hauptkomponenten:
- Frontpanel
- Blockdiagramm
- Code (in Maschinencode kompiliertes Diagramm)
- Daten (Bedien- und Anzeigeelementwerte, Standarddaten, Diagrammkonstantenwerte usw.)
Beim Laden eines VIs werden das Frontpanel, der Code (sofern er zur Plattform passt) und die Daten des VIs in den Speicher geladen. Wenn das VI aufgrund eines Plattformwechsels oder einer Änderung in der Benutzeroberfläche eines SubVIs neu kompiliert werden muss, wird auch das Blockdiagramm in den Speicher geladen.
Das VI lädt auch den Code und die Daten des SubVIs in den Speicher. Unter bestimmten Voraussetzungen wird auch das Frontpanel einiger SubVIs in den Speicher geladen. Dies ist beispielsweise bei VIs mit Eigenschaftsknoten der Fall, da diese Knoten den Zustand von Frontpanel-Elementen ändern.
Wichtig bei der Organisation von VI-Komponenten ist, dass Sie bei der Umwandlung eines VI-Abschnitts in ein SubVI nicht sehr viel mehr Speicher verwenden. Beim Erstellen eines einzelnen riesigen VIs ohne SubVIs werden Frontpanel, Code und Daten dieses Haupt-VIs in den Speicher geladen. Wenn Sie das VI allerdings in SubVIs aufteilen, wird der Code für das Haupt-VI kleiner und Code und Daten der SubVIs bleiben im Speicher. In manchen Fällen wird die Speicherauslastung während der Ausführung verringert.
Große VIs erfordern einen größeren Bearbeitungsaufwand. Das Problem lässt sich folgendermaßen vermeiden:
- (Empfohlen) Unterteilen Sie das VI in SubVIs. Der Editor kann kleinere VIs effizienter bearbeiten. Eine hierarchische VI-Organisation ist normalerweise einfacher zu handhaben und übersichtlicher.
- Konfigurieren Sie LabVIEW zum Abwägen der Reaktionszeit des Editors gegenüber der Ausführungsgeschwindigkeit basierend auf der Komplexität des kompilierten Codes des großen VIs.
Bei der Datenflussprogrammierung werden in der Regel keine Variablen verwendet. Datenflussmodelle beschreiben Knoten normalerweise als Datenquellen (Erzeuger) und Datensenken (Verbraucher). Die originalgetreue Implementierung dieses Modells führt zu Anwendungen, die extrem viel Speicher beanspruchen und eine wenig zufriedenstellende Leistung aufweisen. Jede Funktion erzeugt pro Empfänger ihrer Daten eine Kopie der Daten. Dieses Modell kann durch die sogenannte "Inplaceness" verbessert werden.
Inplaceness verhindert in LabVIEW, dass unnötige Speicherkopien von Daten angelegt werden. Wenn Daten nicht von einem Eingang in einen Ausgang kopiert werden, verbleiben die Daten an Ort und Stelle. Es wird also keine zusätzliche Kopie davon angelegt.
Mit Hilfe des Fensters Pufferzuweisungen anzeigen können Sie feststellen, wo Kopien von Daten erstellt werden können.
Bei dem etwas traditionelleren Ansatz des Compilers verwendet das folgende Blockdiagramm beispielsweise zwei Datenspeicherblöcke: einen für die Eingabe und einen für die Ausgabe.

Eingabe- und Ausgangs-Array enthalten dieselbe Anzahl an Elementen. Auch der Datentyp der beiden Arrays ist identisch. Das Eingangs-Array fungiert als Datenpuffer. Anstatt einen neuen Puffer für die Ausgabe zu erstellen, verwendet der Compiler den Speicher des Eingangspuffer für den Ausgangspuffer. Dadurch wird nicht nur Speicherplatz gespart, sondern auch die Ausführung beschleunigt, weil während der Ausführung kein Speicher belegt werden muss.
Der Compiler kann aber Speicherpuffer nicht immer wiederverwenden – siehe das folgende Blockdiagramm.
Ein Signal wird über eine Datenquelle an mehrere Datensenken geleitet. Die Funktion Teil-Array ersetzen modifiziert dabei ein Eingangs-Array und erzeugt daraus das Ausgangs-Array. In diesem Fall werden am Ausgang einer der Funktionen die Daten des Eingangs-Arrays wiederverwendet. Der Compiler erstellt daher neue Datenpuffer für zwei der Funktionen und kopiert die Array-Daten in die Puffer. Das Blockdiagramm beansprucht ca. 12 KB Speicher (4 KB für das Original-Array und jeweils 4 KB für die beiden extra erzeugten Datenpuffer).
Sehen Sie sich jetzt das folgende Blockdiagramm an.

Wie auch in der vorherigen Abbildung hat die Eingabe eine Verzweigung mit drei Funktionen. In diesem Blockdiagramm verändert die Funktion Array indizieren aber nicht das Eingangs-Array. Wenn Daten an mehrere Stellen übertragen werden, aber dort nur gelesen und nicht verändert werden, erstellt LabVIEW keine Kopie der Daten. Alle Daten sind also "in-place". Somit benötigt dieses Blockdiagramm nur einen Speicherplatz von 4 KB.
Sehen Sie sich abschließend folgendes Blockdiagramm an.

Hier hat die Eingabe eine Verzweigung mit zwei Funktionen, von denen eine die Daten verändert. Die beiden Funktionen sind nicht voneinander abhängig. Daher vermuten Sie wahrscheinlich, dass mindestens eine Kopie erstellt werden muss, um Daten problemlos mit der Funktion "Teil-Array ersetzen" modifizieren zu können. In diesem Fall plant der Compiler die Ausführung der Funktionen aber so, dass die Funktion, mit der die Daten gelesen werden, zuerst ausgeführt wird. Die Funktion zur Bearbeitung der Daten folgt zum Schluss. Auf diese Weise verwendet die Funktion "Teil-Array ersetzen" den Eingangs-Array-Puffer wieder, ohne ein weiteres Array zu erzeugen. Wenn die Reihenfolge der Knoten wichtig ist, sorgen Sie dafür, dass die Knoten nur in dieser Reihenfolge ausgeführt werden können, indem Sie eine Sequenz nutzen oder den Ausgangswert eines Knotens mit dem Eingang des Folgeknotens verbinden.
In der Praxis ist die Analyse von Blockdiagrammen durch den Compiler nicht perfekt. In manchen Fällen ist der Compiler nicht in der Lage, die optimale Methode für die Wiederverwendung von Blockdiagrammspeicher zu bestimmen.
Bedingte Anzeigeelemente und DatenpufferDer Aufbau eines Blockdiagramms kann LabVIEW daran hindern, Datenpuffer wiederzuverwenden. Beispielsweise kann die optimierte Belegung von Datenpuffer durch ein bedingtes Anzeigeelement in einem SubVI verhindert werden. Ein bedingtes Anzeigeelement ist ein Anzeigeelement in Case-Strukturen oder For-Schleifen. Beim Einfügen eines Anzeigeelements in einen bedingt ausgeführten Codeabschnitt wird der Datenfluss unterbrochen. LabVIEW kann den Datenpuffer des Eingangs nicht wiederverwenden, sondern muss zwangsweise eine Kopie der Daten für das Anzeigeelement erzeugen. Wenn Sie Anzeigeelemente außerhalb von Case-Strukturen und For-Schleifen einfügen, bearbeitet LabVIEW die Daten direkt in der Schleife bzw. der Struktur und übergibt sie dann an das Anzeigeelement, anstatt eine Kopie davon zu erstellen. Statt Anzeigeelemente in die Case-Struktur einzufügen, können Sie auch Konstanten für wechselnde Cases erstellen.
Überwachen des SpeicherverbrauchsEs gibt verschiedene Möglichkeiten zum Ermitteln des Speicherverbrauchs.
Der Speicherverbrauch des aktuellen VIs wird angezeigt, wenn Sie auf Datei»VI-Einstellungen klicken und anschließend aus dem Pulldown-Menü Speicherauslastung auswählen. Beachten Sie, dass keine Angaben zum Speicherverbrauch von SubVIs angezeigt werden. Der Speicherverbrauch aller im Speicher befindlichen VIs wird im Fenster Profil - Leistung und Speicher aufgeführt. Dort können Sie ermitteln, welche SubVIs besonders ineffizient funktionieren. Das Fenster Profil - Leistung und Speicher enthält Statistiken dazu, wie viele Bytes und Blöcke jedes VI pro Durchlauf benötigt (Minimum, Maximum und Durchschnitt).
 | Hinweis Um beobachten zu können, ob ein VI effizient ausgeführt wird, speichern Sie alle VIs in der aktuellen LabVIEW-Version, ohne den kompilierten Code getrennt zu speichern. Dafür gibt es folgende Gründe:
|
Mit Hilfe des Fensters Pufferzuweisungen anzeigen lassen sich bestimmte Bereiche im Blockdiagramm identifizieren, in denen Speicherplatz in Form eines Puffers zugewiesen wird.
| Hinweis Das Fenster Pufferzuweisungen anzeigen kann jedoch nur im LabVIEW Full bzw. Professional Development System angezeigt werden. |
Wählen Sie Werkzeuge»Profil»Pufferzuweisungen anzeigen, um zum Fenster Pufferzuweisungen anzeigen zu gelangen. Aktivieren Sie die Datentypen, deren Puffer Sie beobachten möchten, und klicken Sie auf die Schaltfläche Aktualisieren. Die schwarzen Quadrate im Blockdiagramm zeigen an, an welcher Stelle Puffer erzeugt werden, um Speicher für Daten zu belegen.
Der jedem Puffer zugewiesene Speicherplatz entspricht der Größe des größten Datentyps. Bei der Ausführung eines VIs kann LabVIEW diese Puffer bei Bedarf zum Speichern von Daten verwenden. Sie wissen nicht, ob eine Kopie der Daten erstellt wird, da diese Entscheidung während der Ausführung gefällt wird oder das VI möglicherweise von dynamischen Daten abhängt.
Wenn das VI Speicher benötigt, um Speicherplatz für den Pufferinhalt zu belegen, wird eine Kopie der Daten für den Puffer erstellt. Wenn nicht klar ist, ob der Puffer eine Kopie der Daten benötigt, wird manchmal trotzdem eine Kopie für den Puffer erstellt.
| Hinweis Mit Hilfe des Fensters Pufferzuweisungen anzeigen werden nur Ausführungspuffer im Blockdiagramm mit einem schwarzen Viereck gekennzeichnet. Betriebspuffer auf dem Frontpanel werden mit Hilfe dieses Fensters nicht gekennzeichnet. |
Wenn Sie wissen, wo LabVIEW Puffer erzeugt, können Sie eventuell durch entsprechende Bearbeitung die Ausführungsgeschwindigkeit des VIs steigern. LabVIEW muss zur Ausführung von VIs Speicherzuweisungen vornehmen, d. h., Sie können nicht alle Puffer entfernen.
Bei Änderungen an einem VI, die eine Neukompilierung erforderlich machen, werden die schwarzen Quadrate ausgeblendet, da die Angaben zum Puffer unter Umständen nicht mehr stimmen. Mit Hilfe der Schaltfläche Aktualisieren im Dialogfeld Pufferzuweisungen anzeigen wird das VI neu kompiliert und die Symbole werden wieder angezeigt. Nach dem Schließen des Fensters Pufferzuweisungen anzeigen sollten die Quadrate nicht mehr angezeigt werden.
| Hinweis Mit Hilfe des LabVIEW Desktop Execution Trace Toolkits lassen sich Thread-Verwendung, Speicherlecks und andere Aspekte der LabVIEW-Programmierung überwachen. |
Wählen Sie Hilfe»Über LabVIEW zur Anzeige einer Statistik, in der der von Ihrer Anwendung insgesamt benötigte Speicherplatz zusammengefasst wird. Dazu gehört der Speicherbedarf aller VIs und der Speicherbedarf der Anwendung. Sie können den Bedarf vor und nach der Ausführung der VIs prüfen. So sehen Sie, wie viel Speicher ungefähr von den VIs in Anspruch genommen wird.
Regeln zum Verringern des SpeicherbedarfsDer vorherige Abschnitt konzentrierte sich auf die Tatsache, dass der Compiler versucht, Speicher intelligent wiederzuverwenden. Die Regeln für die Wiederverwendung von Speicher durch den Compiler sind recht komplex. In der Praxis helfen nachfolgende Regeln bei der Erstellung von VIs, die Speicher effizient nutzen:
- Die Aufteilung eines VIs in SubVIs schadet in der Regel nie. In vielen Fällen verbessert sich die Speicherauslastung, da das Ausführungssystem SubVI-Datenspeicher zurückfordern kann, wenn das SubVI nicht ausgeführt wird.
- Machen Sie sich nicht zu viele Gedanken über Kopien von Skalarwerten. Damit sich der Speicherbedarf merklich erhöht, sind eine Menge Skalarwerte notwendig.
- Vermeiden Sie die übermäßige Verwendung globaler und lokaler Variablen bei der Arbeit mit Arrays und Strings. Beim Auslesen einer Variable wird immer eine Kopie der Daten angelegt.
- Vermeiden Sie nach Möglichkeit das Anzeigen großer Arrays und Strings auf einem geöffneten Frontpanel. Bei Bedien- und Anzeigeelementen auf einem geöffneten Frontpanel wird immer eine Kopie der angezeigten Daten gespeichert.
 | Tipp Bei Verwendung von Diagrammen sollten Sie beachten, dass die Diagrammhistorie eine Kopie der angezeigten Daten speichert. Dies trifft so lange zu, bis die Diagrammhistorie voll ist. Dann wird kein Speicher mehr in Anspruch genommen. LabVIEW löscht bei einem Neustart des VIs die Diagrammhistorie nicht automatisch. Daher wird empfohlen, die Historie während der Ausführung des Programms zu löschen. Verbinden Sie hierfür ein leeres Array mit dem Attribut "Historiendaten". |
- Verwenden Sie die Einstellung Panel-Aktualisierungen verzögern. Wenn Sie für diese Einstellung TRUE wählen, ändern sich die Anzeigewerte auf dem Frontpanel nicht, selbst wenn Sie den Wert eines Elements ändern. Ihr Betriebssystem muss keinerlei Speicher nutzen, um die Anzeigeelemente mit neuen Werten zu füllen.
| Hinweis LabVIEW öffnet in der Regel bei Aufruf eines SubVIs nicht das dazugehörige Frontpanel. |
- Wenn das Frontpanel eines SubVIs nicht angezeigt wird, entfernen Sie ungenutzte Eigenschaftsknoten aus dem SubVI. Eigenschaftsknoten führen dazu, dass das Frontpanel eines SubVIs im Speicher bleibt, was wiederum zu unnötigem Speicherverbrauch führt.
- Achten Sie beim Erstellen von Blockdiagrammen auf Stellen, an denen sich die Größe von Eingabe und Ausgabe unterscheidet. So werden beispielsweise an Stellen, an denen die Größe eines Arrays oder Strings durch die Funktion Array erstellen oder Strings verknüpfen ständig steigt, Kopien von Daten erzeugt.
- Verwenden Sie einheitliche Datentypen für Arrays und achten Sie auf Typumwandlungspunkte, wenn Daten an SubVIs und Funktionen weitergeleitet werden. Bei der Änderung von Datentypen erstellt das Ausführungssystem eine Kopie der Daten.
- Verwenden Sie keine komplizierten, hierarchischen Datentypen wie Cluster oder Arrays von Clustern mit großen Arrays oder Strings. Dafür wird möglicherweise sogar mehr Speicher benötigt. Nach Möglichkeit sollten Sie effizientere Datentypen verwenden.
- Vermeiden Sie transparente und einander überlappende Frontpanel-Objekte. Solche Objekte benötigen unter Umständen mehr Speicher.
Weitere nützliche Hinweise zum Optimieren der Effizienz eines VIs finden Sie in der LabVIEW Style Checklist.
Speicherprobleme auf dem FrontpanelBei geöffnetem Frontpanel behalten Bedien- und Anzeigeelemente ihre eigene private Kopie der Daten, die sie anzeigen.
Im folgenden Blockdiagramm sehen Sie die Inkrement-Funktion mit zusätzlichen Frontpanel-Elementen.

Wenn Sie das VI ausführen, werden die Daten des Frontpanel-Bedienelements an das Blockdiagramm weitergeleitet. Die Inkrement-Funktion verwendet den Eingabe-Puffer wieder. Das Anzeigeelement erstellt dann eine Kopie der Daten für deren Anzeige. Somit gibt es drei Kopien im Puffer.
Dieser Datenschutz des Frontpanel-Elements verhindert, dass Sie Daten in ein Bedienelement eingeben, das dazugehörige VI ausführen und die Datenänderung im Bedienelement während der Weiterleitung an nachfolgende Knoten sehen. Ähnlich werden Daten von Anzeigeelementen geschützt, so dass diese bis zum Empfang neuer Daten zuverlässig vorherige Inhalte anzeigen können.
Bei SubVIs können Bedien- und Anzeigeelemente als Eingaben und Ausgaben verwendet werden. Das Ausführungssystem erstellt eine Kopie der Elementdaten des SubVIs unter folgenden Bedingungen:
- Das Frontpanel befindet sich im Speicher. Dies kann aus folgenden Gründen der Fall sein:
- Das Frontpanel ist geöffnet.
- Das VI wurde geändert, aber nicht gespeichert (alle Komponenten des VIs bleiben im Speicher, bis das VI gesichert wurde).
- Das Panel verwendet Daten zum Drucken.
- Das Blockdiagramm verwendet Eigenschaftsknoten.
- Das VI verwendet lokale Variablen.
- Das Panel verwendet Daten zur Protokollierung.
Ein Eigenschaftsknoten kann die Diagrammhistorie in SubVIs bei geschlossenem Frontpanel nur dann lesen, wenn des Bedien- bzw. Anzeigeelement die empfangenen Daten anzeigt. Das Frontpanel von SubVIs, die Eigenschaftsknoten enthalten, wird daher vorsorglich für Fälle wie diese im Speicher behalten.
Wenn die Daten eines Frontpanels protokolliert oder ausgedruckt werden sollen, bewahren Bedien- und Anzeigeelemente Kopien ihrer Daten auf. Das Frontpanel wird außerdem im Speicher behalten, so dass es gedruckt werden kann.
Wenn Sie ein SubVI mit Hilfe der Dialogfelder Eigenschaften für VI oder SubVI-Einstellungen so einrichten, dass sein Frontpanel angezeigt wird, wenn es aufgerufen wird, dann wird das Frontpanel beim Aufruf des SubVIs in den Speicher geladen. Wenn Sie die Option Nach Abarbeitung schließen, falls ursprünglich geschlossen auswählen, wird das Frontpanel nach abgeschlossener Ausführung des SubVIs aus dem Speicher entfernt.
SubVIs können Datenspeicher wiederverwendenSubVIs können in der Regel so einfach auf die Datenpuffer aufrufender VIs zugreifen, als würde beispielsweise das Blockdiagramm des SubVIs in das Haupt-VI kopiert. In den meisten Fällen wird nicht mehr Speicher benötigt, wenn Sie einen Abschnitt Ihres Blockdiagramms in ein SubVI umwandeln. Bei VIs mit besonderen Anzeigeanforderungen (siehe Beschreibung im vorherigen Abschnitt) können Frontpanel und Elemente unter Umständen zusätzlichen Speicher beanspruchen.
Das Prinzip der SpeicherfreigabeSehen Sie sich folgendes Blockdiagramm an.

Nach Ausführung des VIs Mittelwert wird das Daten-Array nicht mehr benötigt. Da sich in umfangreicheren Blockdiagrammen nicht ohne Weiteres bestimmen lässt, wann Daten nicht mehr benötigt werden, findet während der Ausführung keine Freigabe der Datenpuffer eines bestimmten VIs statt.
Bei macOS-Computern wird Speicherplatz von Datenpuffern nicht ausgeführter VIs freigegeben, wenn das Ausführungssystem einen Speicherplatzmangel erkennt. Das Ausführungssystem gibt jedoch keinen von Frontpanel-Elementen, globalen Variablen oder nicht initialisierten Schieberegistern verwendeten Speicher frei.
Stellen Sie sich jetzt vor, dasselbe VI ist das SubVI eines größeren VIs. Das Daten-Array wird nur im SubVI erstellt und genutzt. Bei einem macOS könnten die Daten des SubVIs freigegeben werden, wenn das SubVI nicht ausgeführt wird und das System fehlende Speicherressourcen erkennt. In einem solchen Fall kann die Verwendung von SubVIs Speicherplatz sparen.
Bei Windows- und Linux-Plattformen werden Datenpuffer in der Regel nicht freigegeben, es sei denn, ein VI wird geschlossen und aus dem Speicher entfernt. Speicher wird vom System je nach Bedarf zugewiesen und der virtuelle Speicher funktioniert gut auf diesen Plattformen. Aufgrund der Fragmentierung kann es aber erscheinen, als würde eine Anwendung mehr Speicher in Anspruch nehmen, als es tatsächlich der Fall ist. Während Speicher zugewiesen und freigegeben wird, versucht die Anwendung Speicher zusammenzuführen, so dass ungenutzte Blöcke an das Betriebssystem zurückgegeben werden können.
Mit der Funktion Speicherfreigabe anfordern kann ungenutzter Speicher nach Ausführung des VIs, für welches diese Option aktiviert wurde, freigegeben werden. Diese Funktion wird nur zur fortgeschrittenen Leistungsoptimierung eingesetzt. So kann z. B. die Ausführungsgeschwindigkeit in manchen Fällen durch die Freigabe ungenutzten Speichers erhöht werden. Wenn aber zu schnell zu viel Speicher freigegeben wird, kann es passieren, dass LabVIEW den freien Speicherplatz erneut belegt, anstatt den belegten Speicherplatz wiederzuverwenden. Verwenden Sie diese Funktion, wenn Ihr VI große Speicherbereiche reserviert, aber den Speicherplatz nie wiederverwendet. Jedem SubVI in einem VI wird beim Aufruf ein gewisser Speicherbereich zugewiesen. Nach Ausführung des SubVIs bleibt dieser Speicherplatz normalerweise bis zum Ausführungsende des Haupt-VIs belegt. Dadurch kann es zu Speicherplatzmangel oder Verlangsamung des VIs kommen. Fügen Sie die Funktion "Speicherfreigabe anfordern" in das SubVI ein, dessen Sie Speicherplatz freigeben möchten. Damit das VI aktiv ist, muss der Eingang Flag auf TRUE gesetzt werden.
Festlegen der Wiederverwendung von Eingangspuffern durch AusgängeWenn ein Ein- und ein Ausgangswert in Größe und Datentyp übereinstimmen und der Eingangswert an keiner anderen Stelle benötigt wird, kann der Eingangspuffer für den Ausgangswert wiederverwendet werden. Wie bereits erwähnt, können Compiler und Betriebssystem die Ausführung von Code manchmal so festlegen, dass die Eingabe für einen Ausgangspuffer wiederverwendet wird, auch wenn die Eingabe an anderer Stelle genutzt wird. Die Regeln für einen solchen Fall sind allerdings sehr komplex. Verlassen Sie sich nicht darauf.
Sie können über das Fenster Pufferzuweisungen anzeigen feststellen, ob ein Ausgangspuffer den Eingangspuffer wiederverwendet. Im folgenden Blockdiagramm wird der Datenfluss durch das Einfügen eines Anzeigeelements in jeden Case einer Case-Struktur unterbrochen, da LabVIEW für jedes Anzeigeelement eine Kopie der Daten erstellt. Der erstellte Puffer wird nicht für das Eingangs-Array verwendet, sondern die Daten werden für das Ausgangs-Array kopiert.

Wenn Sie das Anzeigeelement aus der Case-Struktur herausziehen, wird der Eingangspuffer für den Ausgangswert wiederverwendet, da für die Anzeigedaten des Elements keine Kopie erstellt werden muss. Die Inkrement-Funktion kann das Eingangs-Array direkt bearbeiten und an das Ausgabe-Array weiterleiten, da LabVIEW den Wert des Eingangs-Arrays später im VI nicht mehr benötigt. In einem solchen Fall muss LabVIEW die Daten nicht kopieren und es erscheint kein Puffer am Ausgangs-Array (vgl. Blockdiagrammabbildung).

Bei der Verwendung einheitlicher Datentypen kann LabVIEW beim Erzeugen eines Ausgangswerts den Puffer des Eingangswerts wiederverwenden. Dadurch können sich Speicherbedarf und Ausführungsdauer eines VIs verringern. Wenn jedoch ein Eingangswert einen anderen Datentyp als ein Ausgangswert hat, kann der Speicher, den LabVIEW für den Eingangswert belegt hat, nicht für den Ausgangswert genutzt werden.
Wenn Sie beispielsweise einem 16-Bit-Integer einen 32-Bit-Integer hinzufügen, dann wird der 16-Bit-Integer dem 32-Bit-Integer angepasst. Der Compiler erstellt einen neuen Puffer für die angepassten Daten und LabVIEW zeigt an der Funktion Addieren einen Typumwandlungspunkt an. In diesem Beispiel kann LabVIEW den 32-Bit-Integer-Eingangswert für den Ausgangspuffer verwenden, sofern der Eingangswert alle anderen Anforderungen erfüllt. Wenn LabVIEW jedoch den 16-Bit-Integer anpasst, kann der für diesen Eingangswert belegte Speicher nicht wiederverwendet werden.
Zum Minimieren der Speicherbedarfs sollten Sie soweit wie möglich einheitliche Datentypen verwenden. Bei einheitlichen Datentypen entfallen die Datenkopien, die bei jeder Umwandlung in eine größere Datengröße angelegt werden müssen. In manchen Anwendungen kann der Speicherbedarf evtl. durch kleinere Datentypen verringert werden. So wären beispielsweise 4-Byte-Werte mit einfacher Genauigkeit besser geeignet als 8-Byte-Werte mit doppelter Genauigkeit. Um jedoch unnötige Typumwandlungen zu vermeiden, können Datentypen von mit einem SubVI verbundenen Objekten an den vom SubVI erwarteten Datentyp angepasst werden.
Optimierung der Speicherauslastung beim Erzeugen eines bestimmten DatentypsBeim Erzeugen von Daten eines bestimmten Typs kann es sein, dass Sie Datentypen in Ihrem Blockdiagramm konvertieren müssen. Sie können jedoch die Speicherauslastung optimieren, indem Sie mit Hilfe der Funktionen und VIs zur Konvertierung Datentypen umwandeln, bevor LabVIEW große Arrays erstellt.
Im folgenden Beispiel müssen die Ausgangsdaten Fließkommawerte einfacher Genauigkeit sein, um mit dem Datentyp des Eingangs eines anderen VIs übereinzustimmen. LabVIEW erstellt ein Array mit 1.000 zufälligen Werten und fügt das Array einem skalaren Wert hinzu. An der Funktion "Addieren" wird ein Typumwandlungspunkt angezeigt, da LabVIEW den skalaren Datentyp "Fließkommawert einfacher Genauigkeit" an die zufällige Fließkommazahl mit doppelter Genauigkeit anpasst.

Das folgende Blockdiagramm zeigt einen Versuch, dieses Problem durch Konvertierung des Arrays aus Fließkommazahl mit doppelter Genauigkeit mit Hilfe der Funktion Nach Fließkomma (einfache Genauigkeit) zu beheben.

Da diese Funktion immer noch den Datentyp des großen Arrays nach dem Erstellen des Arrays konvertiert, benötigt das VI genauso viel Speicher wie im Beispiel mit den Typumwandlungspunkten.
Das folgende Blockdiagramm illustriert, wie durch Konvertierung der Zufallszahl die Speichernutzung und Ausführungsgeschwindigkeit optimiert werden, bevor LabVIEW das Array erstellt.

Wenn sich Umwandlungen nicht vermeiden lassen, können Sie vor dem Erstellen großer Arrays eine Konvertierungsfunktion auf die Array-Daten anwenden. Auf diese Weise können Sie die großen Datenpuffer umgehen, die beim Umwandeln des Arrays in einen anderen Datentyp anfallen. Der Speicherbedarf eines VIs kann also beispielsweise dadurch reduziert werden, indem Daten vor dem Erzeugen großer Arrays umgewandelt werden.
Ständiges Ändern der Datengröße vermeidenUnterscheidet sich die Größe von Ein- und Ausgabe, so wird der Datenpuffer des Eingangswert für den Ausgangswert nicht wiederverwendet. Dies gilt für Funktionen wie Array erstellen, Strings verknüpfen und Teil-Array, mit denen die Größe eines Arrays oder Strings geändert wird. Vermeiden Sie bei der Arbeit mit Arrays und Strings die ständige Verwendung dieser Funktionen, da Ihr Programm aufgrund des dauerhaften Kopierens von Daten mehr Datenspeicher nutzt und die Ausführung langsamer wird.
Beispiel 1: Erstellen von ArraysNehmen Sie als Beispiel das folgende Blockdiagramm, mit dem ein Daten-Array erzeugt wird. Dieses Blockdiagramm erstellt durch wiederholtes Aufrufen der Funktion "Array erstellen" in einer Schleife ein Array, indem es bei jedem Aufruf ein Element hinzufügt. Das Eingangs-Array wird von der Funktion "Array erstellen" wiederverwendet. Das VI vergrößert bei jedem Durchlauf den Puffer, um Platz für das neue Array zu schaffen und das neue Element anhängen zu können. Die Ausführungsgeschwindigkeit wird dadurch langsamer, besonders wenn die Schleife oft ausgeführt wird.
| Hinweis Bei der Bearbeitung von Arrays, Clustern, Signalverläufen und Variantelementen können Sie die Inplace-Elementstruktur nutzen, um den Speicherbedarf von VIs zu verringern. |

Möchten Sie mit jedem Schleifendurchlauf dem Array einen Wert hinzufügen, so erreichen Sie eine optimale Leistung durch die Verwendung der Auto-Indizierung am Rand einer Schleife. Bei For-Schleifen kann das VI die Größe des VIs vorher festlegen (basierend auf dem mit N verbundenen Wert). Der Puffer wird dann nur einmal vergrößert.

Bei While-Schleifen ist die Auto-Indizierung nicht ganz so effizient, da die endgültige Größe des Arrays nicht bekannt ist. Die Auto-Indizierung bei While-Schleifen verhindert aber die Vergrößerung des Ausgangs-Arrays bei jeder Iteration, indem das Ausgangs-Array in großen Inkrementen vergrößert wird. Wenn die Schleife vollständig ausgeführt wurde, wird das Ausgangs-Array an die korrekte Größe angepasst. Die Effizienz der Auto-Indizierung ist bei While- und For-Schleifen fast identisch.

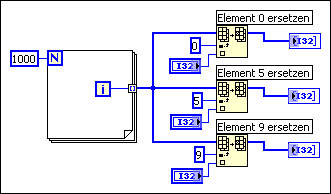
Bei der Auto-Indizierung wird angenommen, dass dem Array bei jedem Durchlauf der Schleife ein Wert hinzugefügt wird. Wenn Sie einem Array bedingt Werte hinzufügen müssen, aber eine Obergrenze für die Array-Größe festlegen können, wäre eine Vorbelegung von Speicher für das Array und die Verwendung der Funktion Teil-Array ersetzen zum Füllen des Arrays ratsam.
Wenn das Array alle Werte enthält, können Sie das Array an die korrekte Größe anpassen. Das Array wird nur einmal erstellt und die Funktion "Teil-Array ersetzen" kann den Eingangspuffer für den Ausgangspuffer wiederverwenden. Die Ausführungseffizienz ähnelt dabei der von Schleifen mit Auto-Indizierung. Achten Sie bei Anwendung dieser Methode darauf, dass das Array, in welchem die Werte ersetzt werden, groß genug für die resultierenden Daten ist, da die Funktion "Teil-Array ersetzen" Arrays nicht automatisch vergrößert.
Im folgenden Blockdiagramm ist dieser Prozess dargestellt.

Mit der Funktion Muster suchen können Sie einen String für ein Muster suchen. Je nach Verwendung kann das die Ausführungsgeschwindigkeit beeinträchtigen, wenn unnötig String-Datenpuffer erstellt werden.
Wenn Sie beispielsweise einen Integer-Wert in einem String vergleichen möchten, können Sie [0–9]+ als regulären Ausdruck für die Eingabe dieser Funktion verwenden. Um ein Array aller Integer-Werte in einem String zu erstellen, verwenden Sie eine Schleife und rufen Sie die Funktion "Regulären Ausdruck suchen" mehrmals auf, bis der ausgegebene Offset-Wert –1 lautet.
Das folgende Blockdiagramm zeigt eine Möglichkeit, nach allen Vorkommnissen von Integer-Werten in einem String zu suchen. Es erstellt ein leeres Array und sucht dann bei jedem Schleifendurchlauf im verbleibenden String nach dem numerischen Muster. Wird das Muster gefunden (Offset ist nicht –1), so addiert das Blockdiagramm mit Hilfe der Funktion "Array erstellen" die Zahl zu einem resultierenden Zahlen-Array. Wenn der String durchsucht wurde, gibt die Funktion "Regulären Ausdruck suchen" –1 aus und das Blockdiagramm schließt die Ausführung ab.

Ein Problem mit diesen Blockdiagramm ist die Verwendung der Funktion "Array erstellen", um den neuen Wert mit dem vorherigen Wert zu verknüpfen. Stattdessen können Sie die Auto-Indizierung verwenden, um die Werte am Rand der Schleife zu sammeln. Beachten Sie, dass ein zusätzlicher unerwünschter Wert im Array angezeigt wird. Dieser stammt vom letzten Schleifendurchlauf, bei dem die Funktion "Regulären Ausdruck suchen" keinen Treffer mehr erzielen konnte. Dieser unerwünschte Wert kann mit der Funktion "Teil-Array" entfernt werden. Dies ist im im folgenden Blockdiagramm zu sehen.
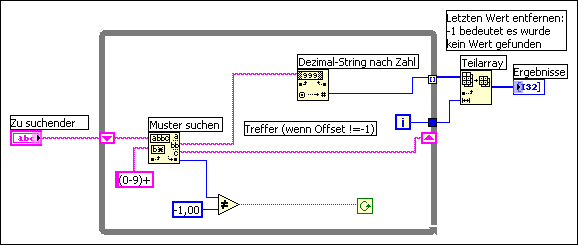
Ein weiteres Problem mit dem Blockdiagramm ist die Erzeugung einer überflüssigen Kopie des verbleibenden Strings bei jedem Schleifendurchlauf. Regulären Ausdruck suchen
Speichermanagement von VI-Komponenten
Ein VI besteht aus folgenden vier Hauptkomponenten:
- Frontpanel
- Blockdiagramm
- Code (in Maschinencode kompiliertes Diagramm)
- Daten (Bedien- und Anzeigeelementwerte, Standarddaten, Diagrammkonstantenwerte usw.)
Beim Laden eines VIs werden das Frontpanel, der Code (sofern er zur Plattform passt) und die Daten des VIs in den Speicher geladen. Wenn das VI aufgrund eines Plattformwechsels oder einer Änderung in der Benutzeroberfläche eines SubVIs neu kompiliert werden muss, wird auch das Blockdiagramm in den Speicher geladen.
Das VI lädt auch den Code und die Daten des SubVIs in den Speicher. Unter bestimmten Voraussetzungen wird auch das Frontpanel einiger SubVIs in den Speicher geladen. Dies ist beispielsweise bei VIs mit Eigenschaftsknoten der Fall, da diese Knoten den Zustand von Frontpanel-Elementen ändern.
Wichtig bei der Organisation von VI-Komponenten ist, dass Sie bei der Umwandlung eines VI-Abschnitts in ein SubVI nicht sehr viel mehr Speicher verwenden. Beim Erstellen eines einzelnen riesigen VIs ohne SubVIs werden Frontpanel, Code und Daten dieses Haupt-VIs in den Speicher geladen. Wenn Sie das VI allerdings in SubVIs aufteilen, wird der Code für das Haupt-VI kleiner und Code und Daten der SubVIs bleiben im Speicher. In manchen Fällen wird die Speicherauslastung während der Ausführung verringert.
Große VIs erfordern einen größeren Bearbeitungsaufwand. Das Problem lässt sich folgendermaßen vermeiden:
- (Empfohlen) Unterteilen Sie das VI in SubVIs. Der Editor kann kleinere VIs effizienter bearbeiten. Eine hierarchische VI-Organisation ist normalerweise einfacher zu handhaben und übersichtlicher.
- Konfigurieren Sie LabVIEW zum Abwägen der Reaktionszeit des Editors gegenüber der Ausführungsgeschwindigkeit basierend auf der Komplexität des kompilierten Codes des großen VIs.
| | Hinweis Sind Frontpanel und Blockdiagramm eines VIs sehr viel größer als der Bildschirm, sollten Sie für besseren Zugriff das VI in SubVIs unterteilen. |
Datenflussprogrammierung und Datenpuffer
Bei der Datenflussprogrammierung werden in der Regel keine Variablen verwendet. Datenflussmodelle beschreiben Knoten normalerweise als Datenquellen (Erzeuger) und Datensenken (Verbraucher). Die originalgetreue Implementierung dieses Modells führt zu Anwendungen, die extrem viel Speicher beanspruchen und eine wenig zufriedenstellende Leistung aufweisen. Jede Funktion erzeugt pro Empfänger ihrer Daten eine Kopie der Daten. Dieses Modell kann durch die sogenannte "Inplaceness" verbessert werden.
Inplaceness verhindert in LabVIEW, dass unnötige Speicherkopien von Daten angelegt werden. Wenn Daten nicht von einem Eingang in einen Ausgang kopiert werden, verbleiben die Daten an Ort und Stelle. Es wird also keine zusätzliche Kopie davon angelegt.
Mit Hilfe des Fensters Pufferzuweisungen anzeigen können Sie feststellen, wo Kopien von Daten erstellt werden können.
Bei dem etwas traditionelleren Ansatz des Compilers verwendet das folgende Blockdiagramm beispielsweise zwei Datenspeicherblöcke: einen für die Eingabe und einen für die Ausgabe.
Eingabe- und Ausgangs-Array enthalten dieselbe Anzahl an Elementen. Auch der Datentyp der beiden Arrays ist identisch. Das Eingangs-Array fungiert als Datenpuffer. Anstatt einen neuen Puffer für die Ausgabe zu erstellen, verwendet der Compiler den Speicher des Eingangspuffer für den Ausgangspuffer. Dadurch wird nicht nur Speicherplatz gespart, sondern auch die Ausführung beschleunigt, weil während der Ausführung kein Speicher belegt werden muss.
Der Compiler kann aber Speicherpuffer nicht immer wiederverwenden – siehe das folgende Blockdiagramm.
Ein Signal wird über eine Datenquelle an mehrere Datensenken geleitet. Die Funktion Teil-Array ersetzen modifiziert dabei ein Eingangs-Array und erzeugt daraus das Ausgangs-Array. In diesem Fall werden am Ausgang einer der Funktionen die Daten des Eingangs-Arrays wiederverwendet. Der Compiler erstellt daher neue Datenpuffer für zwei der Funktionen und kopiert die Array-Daten in die Puffer. Das Blockdiagramm beansprucht ca. 12 KB Speicher (4 KB für das Original-Array und jeweils 4 KB für die beiden extra erzeugten Datenpuffer).
Sehen Sie sich jetzt das folgende Blockdiagramm an.
Wie auch in der vorherigen Abbildung hat die Eingabe eine Verzweigung mit drei Funktionen. In diesem Blockdiagramm verändert die Funktion Array indizieren aber nicht das Eingangs-Array. Wenn Daten an mehrere Stellen übertragen werden, aber dort nur gelesen und nicht verändert werden, erstellt LabVIEW keine Kopie der Daten. Alle Daten sind also "in-place". Somit benötigt dieses Blockdiagramm nur einen Speicherplatz von 4 KB.
Sehen Sie sich abschließend folgendes Blockdiagramm an.
Hier hat die Eingabe eine Verzweigung mit zwei Funktionen, von denen eine die Daten verändert. Die beiden Funktionen sind nicht voneinander abhängig. Daher vermuten Sie wahrscheinlich, dass mindestens eine Kopie erstellt werden muss, um Daten problemlos mit der Funktion "Teil-Array ersetzen" modifizieren zu können. In diesem Fall plant der Compiler die Ausführung der Funktionen aber so, dass die Funktion, mit der die Daten gelesen werden, zuerst ausgeführt wird. Die Funktion zur Bearbeitung der Daten folgt zum Schluss. Auf diese Weise verwendet die Funktion "Teil-Array ersetzen" den Eingangs-Array-Puffer wieder, ohne ein weiteres Array zu erzeugen. Wenn die Reihenfolge der Knoten wichtig ist, sorgen Sie dafür, dass die Knoten nur in dieser Reihenfolge ausgeführt werden können, indem Sie eine Sequenz nutzen oder den Ausgangswert eines Knotens mit dem Eingang des Folgeknotens verbinden.
In der Praxis ist die Analyse von Blockdiagrammen durch den Compiler nicht perfekt. In manchen Fällen ist der Compiler nicht in der Lage, die optimale Methode für die Wiederverwendung von Blockdiagrammspeicher zu bestimmen.
Bedingte Anzeigeelemente und Datenpuffer
Der Aufbau eines Blockdiagramms kann LabVIEW daran hindern, Datenpuffer wiederzuverwenden. Beispielsweise kann die optimierte Belegung von Datenpuffer durch ein bedingtes Anzeigeelement in einem SubVI verhindert werden. Ein bedingtes Anzeigeelement ist ein Anzeigeelement in Case-Strukturen oder For-Schleifen. Beim Einfügen eines Anzeigeelements in einen bedingt ausgeführten Codeabschnitt wird der Datenfluss unterbrochen. LabVIEW kann den Datenpuffer des Eingangs nicht wiederverwenden, sondern muss zwangsweise eine Kopie der Daten für das Anzeigeelement erzeugen. Wenn Sie Anzeigeelemente außerhalb von Case-Strukturen und For-Schleifen einfügen, bearbeitet LabVIEW die Daten direkt in der Schleife bzw. der Struktur und übergibt sie dann an das Anzeigeelement, anstatt eine Kopie davon zu erstellen. Statt Anzeigeelemente in die Case-Struktur einzufügen, können Sie auch Konstanten für wechselnde Cases erstellen.
Überwachen des Speicherverbrauchs
Es gibt verschiedene Möglichkeiten zum Ermitteln des Speicherverbrauchs.
Der Speicherverbrauch des aktuellen VIs wird angezeigt, wenn Sie auf Datei»VI-Einstellungen klicken und anschließend aus dem Pulldown-Menü Speicherauslastung auswählen. Beachten Sie, dass keine Angaben zum Speicherverbrauch von SubVIs angezeigt werden. Der Speicherverbrauch aller im Speicher befindlichen VIs wird im Fenster Profil - Leistung und Speicher aufgeführt. Dort können Sie ermitteln, welche SubVIs besonders ineffizient funktionieren. Das Fenster Profil - Leistung und Speicher enthält Statistiken dazu, wie viele Bytes und Blöcke jedes VI pro Durchlauf benötigt (Minimum, Maximum und Durchschnitt).
| | Hinweis Um beobachten zu können, ob ein VI effizient ausgeführt wird, speichern Sie alle VIs in der aktuellen LabVIEW-Version, ohne den kompilierten Code getrennt zu speichern. Dafür gibt es folgende Gründe:
|
Mit Hilfe des Fensters Pufferzuweisungen anzeigen lassen sich bestimmte Bereiche im Blockdiagramm identifizieren, in denen Speicherplatz in Form eines Puffers zugewiesen wird.
| | Hinweis Das Fenster Pufferzuweisungen anzeigen kann jedoch nur im LabVIEW Full bzw. Professional Development System angezeigt werden. |
Wählen Sie Werkzeuge»Profil»Pufferzuweisungen anzeigen, um zum Fenster Pufferzuweisungen anzeigen zu gelangen. Aktivieren Sie die Datentypen, deren Puffer Sie beobachten möchten, und klicken Sie auf die Schaltfläche Aktualisieren. Die schwarzen Quadrate im Blockdiagramm zeigen an, an welcher Stelle Puffer erzeugt werden, um Speicher für Daten zu belegen.
Der jedem Puffer zugewiesene Speicherplatz entspricht der Größe des größten Datentyps. Bei der Ausführung eines VIs kann LabVIEW diese Puffer bei Bedarf zum Speichern von Daten verwenden. Sie wissen nicht, ob eine Kopie der Daten erstellt wird, da diese Entscheidung während der Ausführung gefällt wird oder das VI möglicherweise von dynamischen Daten abhängt.
Wenn das VI Speicher benötigt, um Speicherplatz für den Pufferinhalt zu belegen, wird eine Kopie der Daten für den Puffer erstellt. Wenn nicht klar ist, ob der Puffer eine Kopie der Daten benötigt, wird manchmal trotzdem eine Kopie für den Puffer erstellt.
| | Hinweis Mit Hilfe des Fensters Pufferzuweisungen anzeigen werden nur Ausführungspuffer im Blockdiagramm mit einem schwarzen Viereck gekennzeichnet. Betriebspuffer auf dem Frontpanel werden mit Hilfe dieses Fensters nicht gekennzeichnet. |
Wenn Sie wissen, wo LabVIEW Puffer erzeugt, können Sie eventuell durch entsprechende Bearbeitung die Ausführungsgeschwindigkeit des VIs steigern. LabVIEW muss zur Ausführung von VIs Speicherzuweisungen vornehmen, d. h., Sie können nicht alle Puffer entfernen.
Bei Änderungen an einem VI, die eine Neukompilierung erforderlich machen, werden die schwarzen Quadrate ausgeblendet, da die Angaben zum Puffer unter Umständen nicht mehr stimmen. Mit Hilfe der Schaltfläche Aktualisieren im Dialogfeld Pufferzuweisungen anzeigen wird das VI neu kompiliert und die Symbole werden wieder angezeigt. Nach dem Schließen des Fensters Pufferzuweisungen anzeigen sollten die Quadrate nicht mehr angezeigt werden.
| | Hinweis Mit Hilfe des LabVIEW Desktop Execution Trace Toolkits lassen sich Thread-Verwendung, Speicherlecks und andere Aspekte der LabVIEW-Programmierung überwachen. |
Wählen Sie Hilfe»Über LabVIEW zur Anzeige einer Statistik, in der der von Ihrer Anwendung insgesamt benötigte Speicherplatz zusammengefasst wird. Dazu gehört der Speicherbedarf aller VIs und der Speicherbedarf der Anwendung. Sie können den Bedarf vor und nach der Ausführung der VIs prüfen. So sehen Sie, wie viel Speicher ungefähr von den VIs in Anspruch genommen wird.
Regeln zum Verringern des Speicherbedarfs
Der vorherige Abschnitt konzentrierte sich auf die Tatsache, dass der Compiler versucht, Speicher intelligent wiederzuverwenden. Die Regeln für die Wiederverwendung von Speicher durch den Compiler sind recht komplex. In der Praxis helfen nachfolgende Regeln bei der Erstellung von VIs, die Speicher effizient nutzen:
- Die Aufteilung eines VIs in SubVIs schadet in der Regel nie. In vielen Fällen verbessert sich die Speicherauslastung, da das Ausführungssystem SubVI-Datenspeicher zurückfordern kann, wenn das SubVI nicht ausgeführt wird.
- Machen Sie sich nicht zu viele Gedanken über Kopien von Skalarwerten. Damit sich der Speicherbedarf merklich erhöht, sind eine Menge Skalarwerte notwendig.
- Vermeiden Sie die übermäßige Verwendung globaler und lokaler Variablen bei der Arbeit mit Arrays und Strings. Beim Auslesen einer Variable wird immer eine Kopie der Daten angelegt.
- Vermeiden Sie nach Möglichkeit das Anzeigen großer Arrays und Strings auf einem geöffneten Frontpanel. Bei Bedien- und Anzeigeelementen auf einem geöffneten Frontpanel wird immer eine Kopie der angezeigten Daten gespeichert.
| | Tipp Bei Verwendung von Diagrammen sollten Sie beachten, dass die Diagrammhistorie eine Kopie der angezeigten Daten speichert. Dies trifft so lange zu, bis die Diagrammhistorie voll ist. Dann wird kein Speicher mehr in Anspruch genommen. LabVIEW löscht bei einem Neustart des VIs die Diagrammhistorie nicht automatisch. Daher wird empfohlen, die Historie während der Ausführung des Programms zu löschen. Verbinden Sie hierfür ein leeres Array mit dem Attribut "Historiendaten". |
- Verwenden Sie die Einstellung Panel-Aktualisierungen verzögern. Wenn Sie für diese Einstellung TRUE wählen, ändern sich die Anzeigewerte auf dem Frontpanel nicht, selbst wenn Sie den Wert eines Elements ändern. Ihr Betriebssystem muss keinerlei Speicher nutzen, um die Anzeigeelemente mit neuen Werten zu füllen.
| | Hinweis LabVIEW öffnet in der Regel bei Aufruf eines SubVIs nicht das dazugehörige Frontpanel. |
- Wenn das Frontpanel eines SubVIs nicht angezeigt wird, entfernen Sie ungenutzte Eigenschaftsknoten aus dem SubVI. Eigenschaftsknoten führen dazu, dass das Frontpanel eines SubVIs im Speicher bleibt, was wiederum zu unnötigem Speicherverbrauch führt.
- Achten Sie beim Erstellen von Blockdiagrammen auf Stellen, an denen sich die Größe von Eingabe und Ausgabe unterscheidet. So werden beispielsweise an Stellen, an denen die Größe eines Arrays oder Strings durch die Funktion Array erstellen oder Strings verknüpfen ständig steigt, Kopien von Daten erzeugt.
- Verwenden Sie einheitliche Datentypen für Arrays und achten Sie auf Typumwandlungspunkte, wenn Daten an SubVIs und Funktionen weitergeleitet werden. Bei der Änderung von Datentypen erstellt das Ausführungssystem eine Kopie der Daten.
- Verwenden Sie keine komplizierten, hierarchischen Datentypen wie Cluster oder Arrays von Clustern mit großen Arrays oder Strings. Dafür wird möglicherweise sogar mehr Speicher benötigt. Nach Möglichkeit sollten Sie effizientere Datentypen verwenden.
- Vermeiden Sie transparente und einander überlappende Frontpanel-Objekte. Solche Objekte benötigen unter Umständen mehr Speicher.
Weitere nützliche Hinweise zum Optimieren der Effizienz eines VIs finden Sie in der LabVIEW Style Checklist.
Speicherprobleme auf dem Frontpanel
Bei geöffnetem Frontpanel behalten Bedien- und Anzeigeelemente ihre eigene private Kopie der Daten, die sie anzeigen.
Im folgenden Blockdiagramm sehen Sie die Inkrement-Funktion mit zusätzlichen Frontpanel-Elementen.
Wenn Sie das VI ausführen, werden die Daten des Frontpanel-Bedienelements an das Blockdiagramm weitergeleitet. Die Inkrement-Funktion verwendet den Eingabe-Puffer wieder. Das Anzeigeelement erstellt dann eine Kopie der Daten für deren Anzeige. Somit gibt es drei Kopien im Puffer.
Dieser Datenschutz des Frontpanel-Elements verhindert, dass Sie Daten in ein Bedienelement eingeben, das dazugehörige VI ausführen und die Datenänderung im Bedienelement während der Weiterleitung an nachfolgende Knoten sehen. Ähnlich werden Daten von Anzeigeelementen geschützt, so dass diese bis zum Empfang neuer Daten zuverlässig vorherige Inhalte anzeigen können.
Bei SubVIs können Bedien- und Anzeigeelemente als Eingaben und Ausgaben verwendet werden. Das Ausführungssystem erstellt eine Kopie der Elementdaten des SubVIs unter folgenden Bedingungen:
- Das Frontpanel befindet sich im Speicher. Dies kann aus folgenden Gründen der Fall sein:
- Das Frontpanel ist geöffnet.
- Das VI wurde geändert, aber nicht gespeichert (alle Komponenten des VIs bleiben im Speicher, bis das VI gesichert wurde).
- Das Panel verwendet Daten zum Drucken.
- Das Blockdiagramm verwendet Eigenschaftsknoten.
- Das VI verwendet lokale Variablen.
- Das Panel verwendet Daten zur Protokollierung.
Ein Eigenschaftsknoten kann die Diagrammhistorie in SubVIs bei geschlossenem Frontpanel nur dann lesen, wenn des Bedien- bzw. Anzeigeelement die empfangenen Daten anzeigt. Das Frontpanel von SubVIs, die Eigenschaftsknoten enthalten, wird daher vorsorglich für Fälle wie diese im Speicher behalten.
Wenn die Daten eines Frontpanels protokolliert oder ausgedruckt werden sollen, bewahren Bedien- und Anzeigeelemente Kopien ihrer Daten auf. Das Frontpanel wird außerdem im Speicher behalten, so dass es gedruckt werden kann.
Wenn Sie ein SubVI mit Hilfe der Dialogfelder Eigenschaften für VI oder SubVI-Einstellungen so einrichten, dass sein Frontpanel angezeigt wird, wenn es aufgerufen wird, dann wird das Frontpanel beim Aufruf des SubVIs in den Speicher geladen. Wenn Sie die Option Nach Abarbeitung schließen, falls ursprünglich geschlossen auswählen, wird das Frontpanel nach abgeschlossener Ausführung des SubVIs aus dem Speicher entfernt.
SubVIs können Datenspeicher wiederverwenden
SubVIs können in der Regel so einfach auf die Datenpuffer aufrufender VIs zugreifen, als würde beispielsweise das Blockdiagramm des SubVIs in das Haupt-VI kopiert. In den meisten Fällen wird nicht mehr Speicher benötigt, wenn Sie einen Abschnitt Ihres Blockdiagramms in ein SubVI umwandeln. Bei VIs mit besonderen Anzeigeanforderungen (siehe Beschreibung im vorherigen Abschnitt) können Frontpanel und Elemente unter Umständen zusätzlichen Speicher beanspruchen.
Das Prinzip der Speicherfreigabe
Sehen Sie sich folgendes Blockdiagramm an.
Nach Ausführung des VIs Mittelwert wird das Daten-Array nicht mehr benötigt. Da sich in umfangreicheren Blockdiagrammen nicht ohne Weiteres bestimmen lässt, wann Daten nicht mehr benötigt werden, findet während der Ausführung keine Freigabe der Datenpuffer eines bestimmten VIs statt.
Bei macOS-Computern wird Speicherplatz von Datenpuffern nicht ausgeführter VIs freigegeben, wenn das Ausführungssystem einen Speicherplatzmangel erkennt. Das Ausführungssystem gibt jedoch keinen von Frontpanel-Elementen, globalen Variablen oder nicht initialisierten Schieberegistern verwendeten Speicher frei.
Stellen Sie sich jetzt vor, dasselbe VI ist das SubVI eines größeren VIs. Das Daten-Array wird nur im SubVI erstellt und genutzt. Bei einem macOS könnten die Daten des SubVIs freigegeben werden, wenn das SubVI nicht ausgeführt wird und das System fehlende Speicherressourcen erkennt. In einem solchen Fall kann die Verwendung von SubVIs Speicherplatz sparen.
Bei Windows- und Linux-Plattformen werden Datenpuffer in der Regel nicht freigegeben, es sei denn, ein VI wird geschlossen und aus dem Speicher entfernt. Speicher wird vom System je nach Bedarf zugewiesen und der virtuelle Speicher funktioniert gut auf diesen Plattformen. Aufgrund der Fragmentierung kann es aber erscheinen, als würde eine Anwendung mehr Speicher in Anspruch nehmen, als es tatsächlich der Fall ist. Während Speicher zugewiesen und freigegeben wird, versucht die Anwendung Speicher zusammenzuführen, so dass ungenutzte Blöcke an das Betriebssystem zurückgegeben werden können.
Mit der Funktion Speicherfreigabe anfordern kann ungenutzter Speicher nach Ausführung des VIs, für welches diese Option aktiviert wurde, freigegeben werden. Diese Funktion wird nur zur fortgeschrittenen Leistungsoptimierung eingesetzt. So kann z. B. die Ausführungsgeschwindigkeit in manchen Fällen durch die Freigabe ungenutzten Speichers erhöht werden. Wenn aber zu schnell zu viel Speicher freigegeben wird, kann es passieren, dass LabVIEW den freien Speicherplatz erneut belegt, anstatt den belegten Speicherplatz wiederzuverwenden. Verwenden Sie diese Funktion, wenn Ihr VI große Speicherbereiche reserviert, aber den Speicherplatz nie wiederverwendet. Jedem SubVI in einem VI wird beim Aufruf ein gewisser Speicherbereich zugewiesen. Nach Ausführung des SubVIs bleibt dieser Speicherplatz normalerweise bis zum Ausführungsende des Haupt-VIs belegt. Dadurch kann es zu Speicherplatzmangel oder Verlangsamung des VIs kommen. Fügen Sie die Funktion "Speicherfreigabe anfordern" in das SubVI ein, dessen Sie Speicherplatz freigeben möchten. Damit das VI aktiv ist, muss der Eingang Flag auf TRUE gesetzt werden.
Festlegen der Wiederverwendung von Eingangspuffern durch Ausgänge
Wenn ein Ein- und ein Ausgangswert in Größe und Datentyp übereinstimmen und der Eingangswert an keiner anderen Stelle benötigt wird, kann der Eingangspuffer für den Ausgangswert wiederverwendet werden. Wie bereits erwähnt, können Compiler und Betriebssystem die Ausführung von Code manchmal so festlegen, dass die Eingabe für einen Ausgangspuffer wiederverwendet wird, auch wenn die Eingabe an anderer Stelle genutzt wird. Die Regeln für einen solchen Fall sind allerdings sehr komplex. Verlassen Sie sich nicht darauf.
Sie können über das Fenster Pufferzuweisungen anzeigen feststellen, ob ein Ausgangspuffer den Eingangspuffer wiederverwendet. Im folgenden Blockdiagramm wird der Datenfluss durch das Einfügen eines Anzeigeelements in jeden Case einer Case-Struktur unterbrochen, da LabVIEW für jedes Anzeigeelement eine Kopie der Daten erstellt. Der erstellte Puffer wird nicht für das Eingangs-Array verwendet, sondern die Daten werden für das Ausgangs-Array kopiert.
Wenn Sie das Anzeigeelement aus der Case-Struktur herausziehen, wird der Eingangspuffer für den Ausgangswert wiederverwendet, da für die Anzeigedaten des Elements keine Kopie erstellt werden muss. Die Inkrement-Funktion kann das Eingangs-Array direkt bearbeiten und an das Ausgabe-Array weiterleiten, da LabVIEW den Wert des Eingangs-Arrays später im VI nicht mehr benötigt. In einem solchen Fall muss LabVIEW die Daten nicht kopieren und es erscheint kein Puffer am Ausgangs-Array (vgl. Blockdiagrammabbildung).
Abgleich von Datentypen zur Optimierung der Speicherauslastung
Bei der Verwendung einheitlicher Datentypen kann LabVIEW beim Erzeugen eines Ausgangswerts den Puffer des Eingangswerts wiederverwenden. Dadurch können sich Speicherbedarf und Ausführungsdauer eines VIs verringern. Wenn jedoch ein Eingangswert einen anderen Datentyp als ein Ausgangswert hat, kann der Speicher, den LabVIEW für den Eingangswert belegt hat, nicht für den Ausgangswert genutzt werden.
Wenn Sie beispielsweise einem 16-Bit-Integer einen 32-Bit-Integer hinzufügen, dann wird der 16-Bit-Integer dem 32-Bit-Integer angepasst. Der Compiler erstellt einen neuen Puffer für die angepassten Daten und LabVIEW zeigt an der Funktion Addieren einen Typumwandlungspunkt an. In diesem Beispiel kann LabVIEW den 32-Bit-Integer-Eingangswert für den Ausgangspuffer verwenden, sofern der Eingangswert alle anderen Anforderungen erfüllt. Wenn LabVIEW jedoch den 16-Bit-Integer anpasst, kann der für diesen Eingangswert belegte Speicher nicht wiederverwendet werden.
Zum Minimieren der Speicherbedarfs sollten Sie soweit wie möglich einheitliche Datentypen verwenden. Bei einheitlichen Datentypen entfallen die Datenkopien, die bei jeder Umwandlung in eine größere Datengröße angelegt werden müssen. In manchen Anwendungen kann der Speicherbedarf evtl. durch kleinere Datentypen verringert werden. So wären beispielsweise 4-Byte-Werte mit einfacher Genauigkeit besser geeignet als 8-Byte-Werte mit doppelter Genauigkeit. Um jedoch unnötige Typumwandlungen zu vermeiden, können Datentypen von mit einem SubVI verbundenen Objekten an den vom SubVI erwarteten Datentyp angepasst werden.
Optimierung der Speicherauslastung beim Erzeugen eines bestimmten Datentyps
Beim Erzeugen von Daten eines bestimmten Typs kann es sein, dass Sie Datentypen in Ihrem Blockdiagramm konvertieren müssen. Sie können jedoch die Speicherauslastung optimieren, indem Sie mit Hilfe der Funktionen und VIs zur Konvertierung Datentypen umwandeln, bevor LabVIEW große Arrays erstellt.
Im folgenden Beispiel müssen die Ausgangsdaten Fließkommawerte einfacher Genauigkeit sein, um mit dem Datentyp des Eingangs eines anderen VIs übereinzustimmen. LabVIEW erstellt ein Array mit 1.000 zufälligen Werten und fügt das Array einem skalaren Wert hinzu. An der Funktion "Addieren" wird ein Typumwandlungspunkt angezeigt, da LabVIEW den skalaren Datentyp "Fließkommawert einfacher Genauigkeit" an die zufällige Fließkommazahl mit doppelter Genauigkeit anpasst.
Das folgende Blockdiagramm zeigt einen Versuch, dieses Problem durch Konvertierung des Arrays aus Fließkommazahl mit doppelter Genauigkeit mit Hilfe der Funktion Nach Fließkomma (einfache Genauigkeit) zu beheben.
Da diese Funktion immer noch den Datentyp des großen Arrays nach dem Erstellen des Arrays konvertiert, benötigt das VI genauso viel Speicher wie im Beispiel mit den Typumwandlungspunkten.
Das folgende Blockdiagramm illustriert, wie durch Konvertierung der Zufallszahl die Speichernutzung und Ausführungsgeschwindigkeit optimiert werden, bevor LabVIEW das Array erstellt.
Wenn sich Umwandlungen nicht vermeiden lassen, können Sie vor dem Erstellen großer Arrays eine Konvertierungsfunktion auf die Array-Daten anwenden. Auf diese Weise können Sie die großen Datenpuffer umgehen, die beim Umwandeln des Arrays in einen anderen Datentyp anfallen. Der Speicherbedarf eines VIs kann also beispielsweise dadurch reduziert werden, indem Daten vor dem Erzeugen großer Arrays umgewandelt werden.
Ständiges Ändern der Datengröße vermeiden
Unterscheidet sich die Größe von Ein- und Ausgabe, so wird der Datenpuffer des Eingangswert für den Ausgangswert nicht wiederverwendet. Dies gilt für Funktionen wie Array erstellen, Strings verknüpfen und Teil-Array, mit denen die Größe eines Arrays oder Strings geändert wird. Vermeiden Sie bei der Arbeit mit Arrays und Strings die ständige Verwendung dieser Funktionen, da Ihr Programm aufgrund des dauerhaften Kopierens von Daten mehr Datenspeicher nutzt und die Ausführung langsamer wird.
Beispiel 1: Erstellen von Arrays
Nehmen Sie als Beispiel das folgende Blockdiagramm, mit dem ein Daten-Array erzeugt wird. Dieses Blockdiagramm erstellt durch wiederholtes Aufrufen der Funktion "Array erstellen" in einer Schleife ein Array, indem es bei jedem Aufruf ein Element hinzufügt. Das Eingangs-Array wird von der Funktion "Array erstellen" wiederverwendet. Das VI vergrößert bei jedem Durchlauf den Puffer, um Platz für das neue Array zu schaffen und das neue Element anhängen zu können. Die Ausführungsgeschwindigkeit wird dadurch langsamer, besonders wenn die Schleife oft ausgeführt wird.
| | Hinweis Bei der Bearbeitung von Arrays, Clustern, Signalverläufen und Variantelementen können Sie die Inplace-Elementstruktur nutzen, um den Speicherbedarf von VIs zu verringern. |
Möchten Sie mit jedem Schleifendurchlauf dem Array einen Wert hinzufügen, so erreichen Sie eine optimale Leistung durch die Verwendung der Auto-Indizierung am Rand einer Schleife. Bei For-Schleifen kann das VI die Größe des VIs vorher festlegen (basierend auf dem mit N verbundenen Wert). Der Puffer wird dann nur einmal vergrößert.
Bei While-Schleifen ist die Auto-Indizierung nicht ganz so effizient, da die endgültige Größe des Arrays nicht bekannt ist. Die Auto-Indizierung bei While-Schleifen verhindert aber die Vergrößerung des Ausgangs-Arrays bei jeder Iteration, indem das Ausgangs-Array in großen Inkrementen vergrößert wird. Wenn die Schleife vollständig ausgeführt wurde, wird das Ausgangs-Array an die korrekte Größe angepasst. Die Effizienz der Auto-Indizierung ist bei While- und For-Schleifen fast identisch.
Bei der Auto-Indizierung wird angenommen, dass dem Array bei jedem Durchlauf der Schleife ein Wert hinzugefügt wird. Wenn Sie einem Array bedingt Werte hinzufügen müssen, aber eine Obergrenze für die Array-Größe festlegen können, wäre eine Vorbelegung von Speicher für das Array und die Verwendung der Funktion Teil-Array ersetzen zum Füllen des Arrays ratsam.
Wenn das Array alle Werte enthält, können Sie das Array an die korrekte Größe anpassen. Das Array wird nur einmal erstellt und die Funktion "Teil-Array ersetzen" kann den Eingangspuffer für den Ausgangspuffer wiederverwenden. Die Ausführungseffizienz ähnelt dabei der von Schleifen mit Auto-Indizierung. Achten Sie bei Anwendung dieser Methode darauf, dass das Array, in welchem die Werte ersetzt werden, groß genug für die resultierenden Daten ist, da die Funktion "Teil-Array ersetzen" Arrays nicht automatisch vergrößert.
Im folgenden Blockdiagramm ist dieser Prozess dargestellt.
Beispiel 2: Suche über Strings
Mit der Funktion Muster suchen können Sie einen String für ein Muster suchen. Je nach Verwendung kann das die Ausführungsgeschwindigkeit beeinträchtigen, wenn unnötig String-Datenpuffer erstellt werden.
Wenn Sie beispielsweise einen Integer-Wert in einem String vergleichen möchten, können Sie [0–9]+ als regulären Ausdruck für die Eingabe dieser Funktion verwenden. Um ein Array aller Integer-Werte in einem String zu erstellen, verwenden Sie eine Schleife und rufen Sie die Funktion "Regulären Ausdruck suchen" mehrmals auf, bis der ausgegebene Offset-Wert –1 lautet.
Das folgende Blockdiagramm zeigt eine Möglichkeit, nach allen Vorkommnissen von Integer-Werten in einem String zu suchen. Es erstellt ein leeres Array und sucht dann bei jedem Schleifendurchlauf im verbleibenden String nach dem numerischen Muster. Wird das Muster gefunden (Offset ist nicht –1), so addiert das Blockdiagramm mit Hilfe der Funktion "Array erstellen" die Zahl zu einem resultierenden Zahlen-Array. Wenn der String durchsucht wurde, gibt die Funktion "Regulären Ausdruck suchen" –1 aus und das Blockdiagramm schließt die Ausführung ab.
Ein Problem mit diesen Blockdiagramm ist die Verwendung der Funktion "Array erstellen", um den neuen Wert mit dem vorherigen Wert zu verknüpfen. Stattdessen können Sie die Auto-Indizierung verwenden, um die Werte am Rand der Schleife zu sammeln. Beachten Sie, dass ein zusätzlicher unerwünschter Wert im Array angezeigt wird. Dieser stammt vom letzten Schleifendurchlauf, bei dem die Funktion "Regulären Ausdruck suchen" keinen Treffer mehr erzielen konnte. Dieser unerwünschte Wert kann mit der Funktion "Teil-Array" entfernt werden. Dies ist im im folgenden Blockdiagramm zu sehen.
Ein weiteres Problem mit dem Blockdiagramm ist die Erzeugung einer überflüssigen Kopie des verbleibenden Strings bei jedem Schleifendurchlauf. Die Funktion "Regulären Ausdruck suchen" hat einen Eingang, an dem Sie den Ausgangspunkt der Suche angeben können. Wenn Sie sich den Offset der vorherigen Iteration merken, können Sie diese Zahl als Beginn der Suche für den nächsten Durchlauf angeben. Dies ist im im folgenden Blockdiagramm zu sehen.

Entwickeln effizienter Datenstrukturen
Eine Kernaussage des vorherigen Beispiels war, dass sich hierarchische Datenstrukturen wie Cluster oder Arrays aus Clustern mit großen Arrays oder Strings schwer bearbeiten lassen. Dieser Abschnitt beschreibt die Ursache dafür und führt Strategien für die Wahl effizienter Datentypen auf.
Das Problem mit komplizierten Datenstrukturen ist, dass Elemente innerhalb einer Datenstruktur schwer zugänglich und veränderbar sind, ohne dass Kopien der Elemente, auf die Sie zugreifen, erstellt werden. Handelt es sich dabei um große Elemente, z. B. Arrays und Strings, können diese Kopien sehr viel Speicherplatz belegen. Des Weiteren wird viel Zeit für das Kopieren des Speichers benötigt.
In der Regel können Skalar-Datentypen sehr effizient bearbeitet werden. Ähnlich lassen sich auch kleine Strings und Arrays mit einem Skalar als Element effizient bearbeiten. Bei einem Array aus Skalarwerten zeigt der folgende Code, was Sie tun müssen, um einen Wert in einem Array zu erhöhen.
| | Hinweis Bei der Bearbeitung von Arrays, Clustern, Signalverläufen und Variantelementen können Sie die Inplace-Elementstruktur nutzen, um den Speicherbedarf von VIs zu verringern. Bei vielen LabVIEW-Operationen ist das Kopieren und Speichern von Datenwerten erforderlich. Dadurch verringert sich die Ausführungsgeschwindigkeit und der Speicherbedarf erhöht sich. Mit Hilfe der Inplace-Elementstruktur werden LabVIEW-Operationen ausgeführt, ohne dass mehrere Kopien der Daten im Speicher angefertigt werden müssen. Stattdessen führt die Inplace-Elementstruktur Operationen an Datenelementen an derselben Stelle im Speicher aus und gibt diese Elemente an derselben Stelle im Array, Cluster, Variant oder Signalverlauf aus. Da LabVIEW die Datenelemente an derselben Stelle im Speicher ausgibt, muss der LabVIEW-Compiler keine zusätzlichen Kopien der Daten im Speicher anfertigen. |

Diese Lösung ist sehr effizient, da keine zusätzlichen Kopien des gesamten Arrays erzeugt werden müssen. Hinzu kommt, dass das durch die Funktion Array indizieren erzeugte Element ein Skalarwert ist, der effizient erstellt und bearbeitet werden kann.
Dasselbe gilt für ein Array aus Clustern, vorausgesetzt, der Cluster enthält ausschließlich Skalare. Im folgenden Blockdiagramm ist die Bearbeitung von Elementen etwas komplizierter, da die Funktionen Bündeln und Aufschlüsseln verwendet werden müssen. Da der Cluster aber höchstwahrscheinlich eher klein ist (Skalare benötigen sehr wenig Speicherplatz), wird beim Zugriff auf die Cluster-Elemente und das anschließende Einfügen der Elemente zurück in den Original-Cluster kein bedeutender Overhead erzeugt.
Im folgenden Blockdiagramm sehen Sie das effiziente Muster für Aufschlüsseln, Operation und erneutes Bündeln. Die Datenquelle sollte nur mit dem Eingang der Funktion "Aufschlüsseln" und dem mittleren Anschluss der Funktion "Bündeln" verbunden werden. LabVIEW erkennt dieses Muster und ist in der Lage, einen leistungsfähigeren Code zu generieren.

Bei einem Cluster-Array, bei dem die Cluster große Teil-Arrays oder Strings enthalten, kann das Indizieren und Ändern der Elementwerte im Cluster hinsichtlich Speicher und Geschwindigkeit weniger vorteilhaft sein.
Bei der Indizierung eines Elements im Gesamt-Array wird eine Kopie des Elements erstellt. Somit wird eine Kopie des Clusters und der dazugehörigen großen Teil-Arrays oder Strings erstellt. Da Strings und Arrays in der Größe variieren, kann während des Kopierens Speicher belegt werden, um die Größe des Strings oder Teil-Arrays in die passende Größe umzuwandeln, was zum Overhead für das eigentliche Kopieren der Daten hinzuzurechnen ist. Wenn Sie einen solchen Vorgang nur ein paar Mal ausführen, ist das wahrscheinlich weniger problematisch. Greift Ihre Anwendung aber regelmäßig auf diese Datenstruktur zu, so summieren sich der Speicher- und Ausführungs-Overhead recht schnell.
Die Lösung ist eine alternative Darstellung Ihrer Daten. Die folgenden Fallstudien zeigen drei verschiedene Anwendungen sowie Vorschläge für optimale Datenstrukturen in jedem Fall.
Fallstudie 1: Vermeiden von komplizierten Datentypen
Nehmen Sie eine Anwendung, in der Sie die Ergebnisse verschiedener Tests aufzeichnen möchten. Als Ergebnisse sollen ein String zur Beschreibung des Tests sowie ein Array mit den Testergebnissen ausgegeben werden. Auf dem folgenden Frontpanel sehen Sie einen für das Speichern dieser Angaben geeigneten Datentyp.

Zur Änderung eines Elements im Array muss ein Element des Gesamt-Arrays indiziert werden. Dann müssen die Elemente für dieses Cluster aufgeschlüsselt werden, so dass sie das Array erreichen. Anschließend ersetzen Sie ein Element des Arrays und speichern das resultierende Array im Cluster. Zum Abschluss speichern Sie das resultierende Cluster im originalen Array. Im folgenden Blockdiagramm ist dies dargestellt.

Jede Stufe der Aufschlüsselung/Indizierung kann zu einer Kopie der erzeugten Daten führen. Eine Kopie wird aber nicht zwingend erzeugt. Das Kopieren von Daten kostet sowohl Zeit als auch Speicher. Daher sollten Datenstrukturen so flach wie möglich gehalten werden. Teilen Sie in dieser Fallstudie beispielsweise die Datenstruktur in zwei Arrays auf. Das erste Array ist das String-Array. Das zweite Array ist ein 2D-Array, bei dem jede Zeile die Ergebnisse eines Tests anzeigen. Das Ergebnis dieser Änderung sehen Sie in der folgenden Abbildung.

Bei dieser Datenstruktur kann ein Array-Element mit Hilfe der Funktion "Teil-Array ersetzen" direkt ersetzt werden (siehe folgendes Blockdiagramm).

Fallstudie 2: Globale Tabelle mit gemischten Datentypen
Hierbei handelt es sich um eine Anwendung für eine Tabelle. Auf die Daten soll global zugegriffen werden können. Die Tabelle könnte Einstellungen für ein Gerät enthalten, z. B. Verstärkung, Mindest- und Höchstspannung sowie einen Namen für den Kanal.
Um in der gesamten Anwendung Zugriff auf diese Daten zu haben, können Sie SubVIs erstellen, z. B. die nachfolgend dargestellten SubVIs "Change Channel Info.vi" und "Remove Channel Info.vi".


In den folgenden Abschnitten werden drei verschiedene Umsetzungen für diese VIs erläutert.
Offensichtliche Umsetzung
Mit diesem Satz an Funktionen kommen verschiedene Datenstrukturen für die zugrunde liegende Tabelle in Frage. Sie könnten eine globale Variable mit einem Cluster-Array verwenden, wobei jeder Cluster die Verstärkung, die Mindest- und Höchstspannung sowie den Kanalnamen enthält.
Wie im vorherigen Abschnitt beschrieben, ist eine effiziente Bearbeitung dieser Datenstruktur sehr schwierig, da Sie in der Regel eine Reihe von Indizierungs- und Aufschlüsselungsvorgängen für den Datenzugriff durchführen müssen. Hinzu kommt, dass die Datenstruktur eine Ansammlung verschiedenartiger Daten ist und Sie die Funktion 1D-Array durchsuchen für die Suche nach einem Kanal nicht verwenden können. Sie können mit dieser Funktion nach speziellen Clustern in einem Cluster-Array suchen, aber nicht nach Elementen, die mit einem einzelnen Cluster-Element übereinstimmen.
Alternative Umsetzung 1
Wie auch in der vorherigen Fallstudie sollten Sie die Daten auf zwei verschiedene Arrays aufteilen. Ein Array enthält die Kanalnamen und das andere die Kanaldaten. Der Index eines gegebenen Kanalnamens im Namen-Array wird verwendet, um die entsprechenden Kanaldaten im anderen Array zu finden.
Beachten Sie, dass das String-Array von den Daten getrennt ist und Sie somit die Funktion "1D-Array durchsuchen" für die Suche nach einem Kanal nutzen können.
Wenn Sie in der Praxis mit dem VI "Change Channel Info.vi" ein Array mit 1.000 Kanälen erstellen, ist diese Umsetzung circa zweimal so schnell wie die vorherige Version. Diese Änderung ist nicht von großer Bedeutung, da ein anderer Overhead die Leistung beeinträchtigt.
Während des Lesevorgangs aus einer globalen Variablen wird eine Kopie der Daten dieser Variablen erstellt. Folglich wird bei jedem Zugriff auf ein Element eine vollständige Kopie aller Array-Daten erstellt. Die nächste Methode ist noch effizienter und vermeidet auch den eben aufgeführten Overhead.
Alternative Umsetzung 2
Es gibt eine Alternative für das Speichern globaler Daten, und zwar die Verwendung eines nicht initialisierten Schieberegisters. Grundsätzlich merkt sich ein Schieberegister, wenn kein Anfangswert verbunden ist, den Wert von Aufruf zu Aufruf.
Der LabVIEW-Compiler handhabt den Zugriff auf Schieberegister sehr effizient. Das Lesen eines Schieberegisterwerts erzeugt nicht zwingend eine Kopie der Daten. Sie können im Grunde genommen ein in einem Schieberegister gespeichertes Array indizieren und sogar ändern und aktualisieren, ohne zusätzliche Kopien des Gesamt-Arrays zu erzeugen. Das einzige Problem mit dieser Methode ist, dass das VI, in dem sich das Schieberegister befindet, auf die Daten des Schieberegisters zugreifen kann. Andererseits hat das Schieberegister dadurch den Vorteil der Modularität.

Sie können ein einzelnes SubVI mit einem Modus-Eingang erstellen, an dem Sie zwischen Auslesen, Ändern und Entfernen eines Kanals auswählen können und festlegen können, ob die Daten für alle Kanäle auf Null gesetzt werden sollen.
Das SubVI enthält eine While-Schleife mit einem Schieberegister für die Kanaldaten und einem Register für die Kanalnamen. Keines der beiden Schieberegister ist initialisiert. Fügen Sie anschließend eine mit dem Modus-Eingang verbundene Case-Struktur in die While-Schleife ein. Je nach ausgewähltem Modus können Sie die Daten des Schieberegisters auslesen und möglicherweise sogar ändern.
Die folgende Abbildung zeigt ein SubVI mit einer Schnittstelle, die diese drei Modi handhabt. Nur der Code "Change Channel Info" wird angezeigt.

Für 1.000 Elemente ist diese Umsetzung zweimal so schnell wie die vorherige und viermal so schnell wie die originale Implementierung.
Fallstudie 3: Statische globale Tabelle mit Strings
Die vorherige Fallstudie behandelte eine Anwendung, in der eine Tabelle verschiedene Datentypen enthielt und die Tabelle sich regelmäßig ändern könnte. Bei vielen Anwendungen bleibt der Inhalt der Tabelle nach dem Erstellen der Tabelle jedoch weitgehend unverändert. Die Tabelle wird beispielsweise von einer Tabellenkalkulationsdatei gelesen. Nachdem die Tabelle einmal in den Speicher gelesen wurde, dient sie primär Informationszwecken.
In diesem Fall könnte Ihre Umsetzung aus den Funktionen "Initialize Table From File.vi" und "Get Record From Table.vi" bestehen.


Ein Weg, diese Tabelle umzusetzen, ist die Verwendung eines zweidimensionalen String-Arrays. Beachten Sie, dass der Compiler jeden String in ein String-Array in einem anderen Speicherblock speichert. Ist die Anzahl an Strings sehr hoch (z. B. über 5.000), so könnten Sie den Speichermanager belasten. Diese Belastung kann mit zunehmender Anzahl an individuellen Objekten zu einem erheblichen Leistungsverlust führen.
Eine alternative Methode für das Speichern großer Tabellen ist das Einlesen der Tabelle als einzelnen String. Erstellen Sie dann ein separates Array mit den Offsets für jeden Datensatz im String. Anstelle tausender relativ kleiner Speicherblöcke sind nun nur noch ein großer Block (für den String) und ein kleiner Block (für das Array mit den Offsets) vorhanden.
Diese Methode ist in der Umsetzung vielleicht etwas komplizierter, kann aber für große Tabellen sehr viel schneller sein.