Improving Streaming Application Performance with Zero-copy and Asynchronous TDMS
Overview
Contents
- The Need for Zero-Copy
- Zero-Copy Theory and Implementation
- Asynchronous TDMS
- Stream to Disk Example
- Stream from Disk Example
- When Not to use Zero-Copy and Asynchronous TDMS
- Throughput Improvement Benchmarks
- Where to Start with Zero-Copy and Asynchronous TDMS
- Summary
The Need for Zero-Copy
In a traditional stream to disk application, data is passed from the instrument to disk as shown in Figure 1 below.
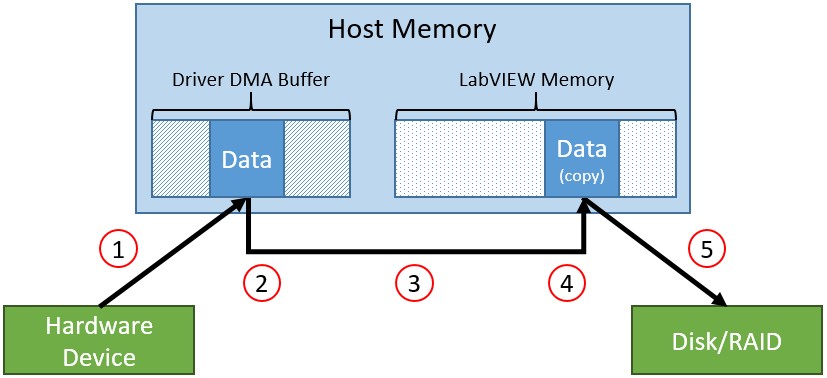
Figure 1: Traditional Flow of Data from Hardware Device to Disk
Due to the data copy created by the device driver read function, this approach causes five “hits” to the host memory controller. First, the hardware writes to the DMA buffer allocated by the device driver (1). When the device driver API Read function (FIFO.Read, RFSA Fetch, etc.) is called, the acquired data is read from the DMA buffer (2) written to ADE memory (4). However, in order to write the data to ADE memory, the data must first be read into the CPU cache (3). Finally, when the File I/O API’s write function is called, that data is read from ADE memory (5) in order to be written to disk. Figure 2 below shows the same five operations in the LabVIEW code for streaming FPGA data to disk.
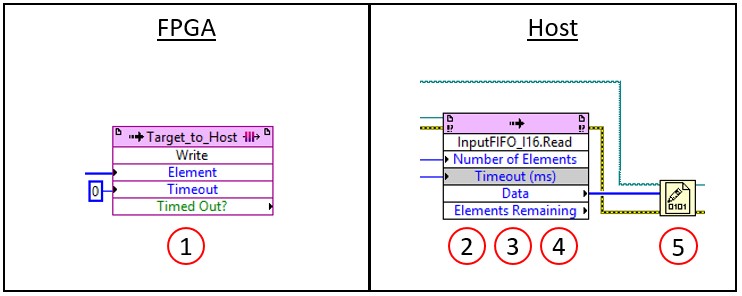
Figure 2: Data Copy in LabVIEW FPGA Interface
In applications with little or no data processing between acquiring data and writing to disk, operations 2,3, and 4, all a cause of the data copy, are unnecessary uses of memory bandwidth. As an example, streaming 200MHz bandwidth of I16 RF IQ data (1GB/s) would use 5GB/s of memory bandwidth. Without the data copy, the same operation would only require 2GB/s of memory bandwidth. Zero-copy access to DMA buffers eliminates the unnecessary data copy.
Zero-Copy Theory and Implementation
In order to eliminate the data copy incurred by reading data from the device DMA buffer, some NI instrument drivers implement a function that returns an External Data Value Reference (EDVR) to data, instead of the data itself. Similar to the native LabVIEW Data Value Reference (DVR), an EDVR is simply a reference to data in memory outside of LabVIEW. The In Place Element Structure allows dereferencing and in-place operation on the data.
In streaming applications, EDVRs can be leveraged to provide zero-copy access to hardware device DMA buffers, as shown in Figure 3 below.
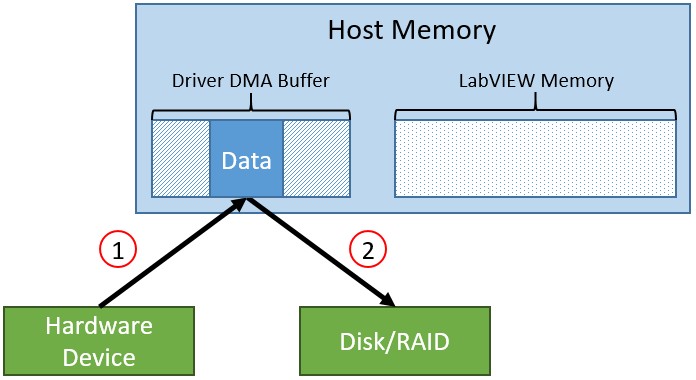
Figure 3: Zero-Copy Data Streaming with EDVR Model
This model of data streaming only requires two “hits” to the host memory controller. First, the hardware instrument writes data to the driver DMA buffer (1). Then, through the EDVR returned by the instrument driver API, the disk or RAID storage device can read the data directly from the host DMA buffer (2). Figure 4 below shows the same operations in the LabVIEW code for streaming FPGA data to disk.
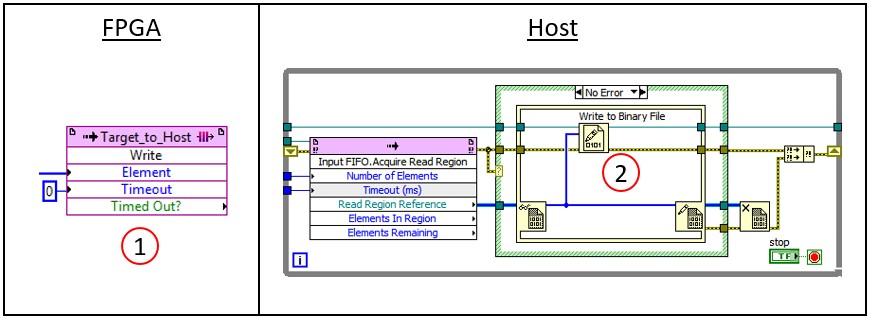
Figure 4: Zero-Copy with LabVIEW FPGA Interface
Asynchronous TDMS
While the approach shown in Figure 4 is certainly an improvement over the method shown in Figure 2, the Write to Binary File function operates synchronously, meaning it blocks execution until the entire write to disk is complete. As a result, each iteration of the loop spends significant time performing overhead tasks such as DMA programming of the disk or RAID controller before the data is actually transferred to disk. Performing the file I/O asynchronously allows the application to squeeze additional performance out of the hard disk by keeping by reducing disk idle time between writes. Figure 5 below shows the disk idle time (gaps between green blocks) for synchronous versus asynchronous file I/O.
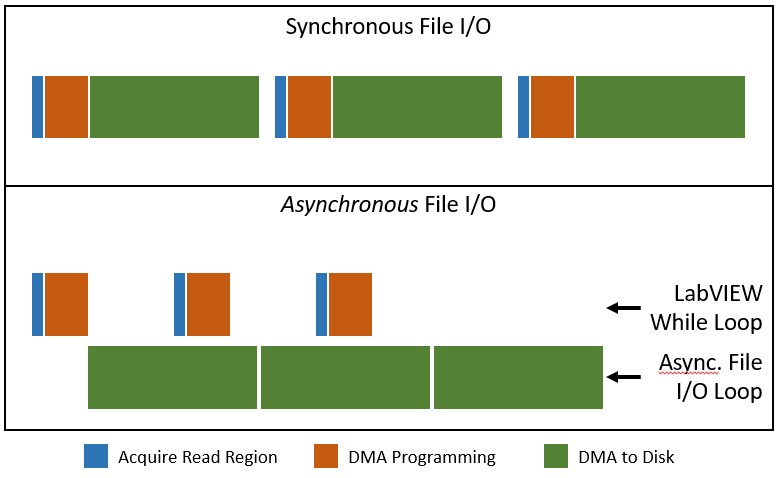
Figure 5: Disk Dead Time in Synchronous vs. Asynchronous File I/O
Performing file I/O asynchronously could be achieved through calling the Write to Binary function in a separate loop and using a queue to pass data between loops. However, the Advanced TDMS API provides a simpler solution that does not require the user to manage multiple asynchronous loops manually. Specifically, the TDMS Advanced Data Reference I/O palette (File I/O>>TDM Streaming>>Advanced TDMS>>TDMS Advanced Data Reference I/O) allows the user to pass the EDVR returned by the instrument driver API directly to an asynchronous TDMS read/write function. This API automatically handles releasing data references upon completion of each asynchronous write and ensures data is written to disk in the appropriate order. Additionally, using the TDMS Reserve File Size function allows the user to pre-allocate space on disk for data files, eliminating file-system fragmentation. This architecture can be used for both streaming to and streaming from disk, as shown in the next two sections.
Stream to Disk Example
Figure 6 below shows the LabVIEW code for an FPGA-based data record loop utilizing EDVRs and the asynchronous TDMS API.
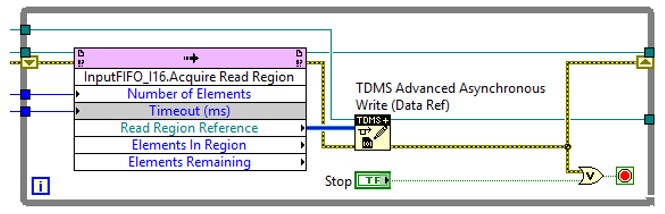
Figure 6: EDVRs with Asynchronous TDMS for FPGA Acquisition
In this code, the Acquire Read Region function returns an EDVR pointing to the data specified by the “Number of Elements” input, relative to the current read position in the DMA FIFO buffer. The EDVR is then passed to the TDMS Advanced Asynchronous Write (Data Ref) function, which begins an asynchronous write of the referenced data, then returns immediately. There are a few important caveats to consider:
- The Advanced TDMS APIs disable buffering by default. As a result, the chunk size (specified by the “Number of Elements” in the code above) must be an integer multiple of the hard disk sector size (usually 4096 bytes).
- The Acquire Read Region method does not automatically wrap back to the beginning of the DMA buffer if the requested number of elements would force the driver to read past the end of the buffer. In that situation, the EDVR returned will reference the number of elements from the current read position to the end of the buffer. The actual number of elements returned will be indicated in the “Elements in Region” output. National Instruments recommends that Number of Elements be a clean integer divisor of the host FIFO size to avoid this problem.
Stream from Disk Example
Figure 7 below shows the LabVIEW code for an FPGA-based data playback loop utilizing EDVRs and the asynchronous TDMS API.
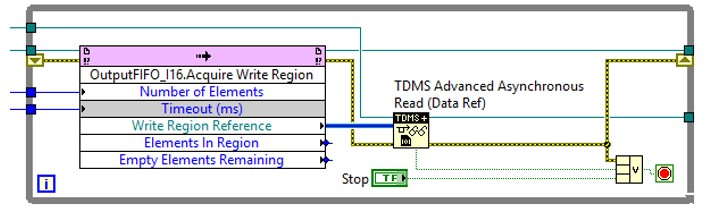
Figure 7: EDVRs with Asynchronous TDMS for FPGA Generation
While this code looks very similar to the acquisition instance, it is moving data from disk to the hardware device. In this case, the “Acquire Write Region” method returns a reference to the current write position in the host DMA buffer. This reference is then passed to the TDMS Advanced Asynchronous Read (Data Ref) function, which starts an asynchronous read operation of the specified Number of Elements and returns immediately. In the background, the asynchronous TDMS thread reads the data from disk directly into the device DMA buffer. Streaming data from disk using this architecture is subject to the same caveats mentioned above for streaming to disk.
When Not to use Zero-Copy and Asynchronous TDMS
Zero-copy data streaming will not yield significant performance increases in all applications. In the following situations, a zero-copy approach will have either a negligible or negative effect on performance:
- Small read block sizes – There is additional overhead incurred with the “Acquire Read Region” function that is not present with a standard FIFO Read. This additional overhead may actually reduce performance if the system has plenty of available CPU cycles available and the data to be copied is relatively small (tens of kB). The crossover point at which time saved by eliminating the data copy is greater than this overhead typically occurs with reads greater than 60kB, but is dependent on many other factors, including controller architecture and CPU loading.
- Substantial data processing before writing to disk - In this situation, the CPU cycles and memory bandwidth required by the data copy are negligible compared to that consumed by processing. As such, the additional complexity of using EDVRs and modifying processing algorithms to work on data in-place may not be worth the effort.
- Abundant memory bandwidth and CPU cycles – If the required data throughput is small relative to the available memory bandwidth, the performance decrease caused by the data copy may be acceptable. System memory bandwidth is dependent on the DRAM generation (ex. DDR4), data clock frequency, and number of memory channels.
Additionally, only NI-RIO, the LabVIEW FPGA Host Interface, PXImc and NI Vision Development Module include a zero-copy API at this time.
Throughput Improvement Benchmarks
As an example of the performance increase yielded by a zero-copy approach, consider the system shown in figure 8 below:
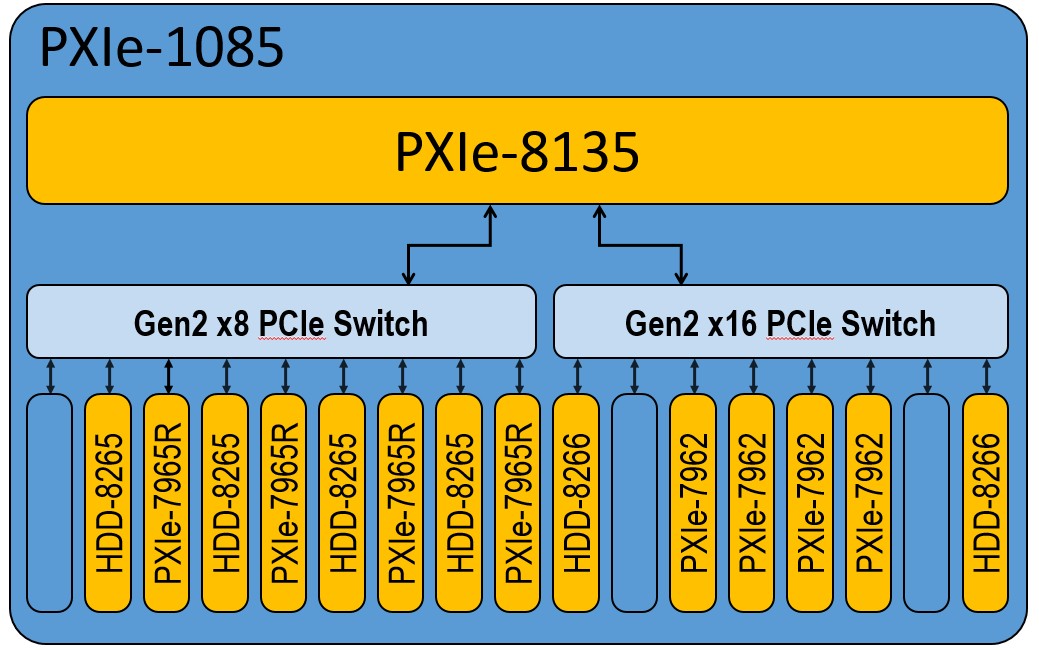
Figure 8: Benchmark Test System
The maximum data throughput was tested by increasing the data rate of each FlexRIO device, until a DMA overflow error occurred. The table below shows the system performance for the traditional read (with data copy) method and the zero-copy method. Both methods used asynchronous TDMS file I/O operations.
| Method | Per Device (MB/s) | Total Data (GB/s) | Copy BW (GB/s) | Data to Disk (GB/s) | Total Memory BW (GB/s) |
| Read (with copy) | 550 | 4.4 | 8.8 | 4.4 | 17.6 |
| Acquire Read Region | 850 | 6.8 | 0.0 | 6.8 | 13.6 |
As the table shows, the zero-copy method resulted in higher device throughput while consuming less total memory bandwidth. The additional 8.8 GB/s of memory bandwidth consumed by the data copy in the read method caused the total system throughput to be limited by the memory bandwidth of the PXIe-8135 controller. By eliminating the data copy, the system reached 13.6 GB/s total throughput (6.8 GB/s up, 6.8 GB/s down), and was instead limited by the PCIe Gen2 chassis bandwidth.
Further testing with additional inline processing in the same system showed a 40% reduction in CPU utilization by using a zero-copy approach.
Where to Start with Zero-Copy and Asynchronous TDMS
NI has developed an extensible example template for high data rate streaming applications that utilizes both zero-copy data transfers (EDVRs) and the advanced asynchronous TDMS API. The NI EDVR Input Stream Framework can be downloaded from VI Package Manager for free. The included LabVIEW Class provides an abstraction layer that can be overridden by child classes specific to your hardware device. For an example of how to develop a full streaming application using this framework, you can download the NI Streaming Host Example for the NI 5668R from VI Package Manager.
Summary
A zero-copy data streaming approach utilizing External Data Value References simplifies high throughput streaming applications while simultaneously improving performance. This approach reduces consumption of host memory bandwidth, reduces CPU utilization, avoids run-time memory allocations, and reduces total memory usage. Similarly, using the asynchronous TDMS API minimizes disk idle-time and eliminates file fragmentation, increasing overall disk throughput.
By pairing a zero-copy approach with asynchronous TDMS file I/O, high-throughput streaming applications can increase maximum throughput while reducing application complexity and resource utilization.