 |
SVM type specifies the type of the SVM model.
| 1 | C_SVC (default)—Specifies the C-SVM model. | | 2 | NU_SVC—Specifies the nu-SVM model. |
|
 |
c specifies the c parameter for the C-SVM model. The default is 1. The lower the value of c, the more wrongly classified training samples the SVM model allows for. The c parameter must be greater than 0. This input is valid only if SVM type is C_SVC.
|
|
nu specifies the nu parameter for the nu-SVM model. The nu parameter is both a lower bound for the number of samples that are support vectors and an upper bound for the number of samples that are on the wrong side of the hyperplane. The default is 0.5. The nu parameter must be in the range [0,1]. This input is valid only if SVM type is NU_SVC.
For example, if nu is 0.05, the training samples that are wrongly classified are not allowed to take up more than 5 percent of all training samples. Also, at least 5 percent of the training samples are support vectors.
|
 |
kernel settings specifies settings to configure the kernel function.
This VI supports the following kernel functions:
| Kernel function | Definition | Description |
|---|
| Linear function | 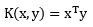 | x and y are the input sample vectors. |
| Polynomial function | 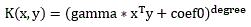 | x and y are the input sample vectors; gamma, coef0, and degree are the algorithm coefficients. |
| Radial basis function | 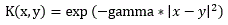 | x and y are the input sample vectors. |
| Sigmoid function |  | x and y are the input sample vectors; gamma and coef0 are the algorithm coefficients. |
|
type specifies the type of the kernel function.
| 0 | Linear (default)—Linear function |
| 1 | Polynomial—Polynomial function |
| 2 | RBF—Radial basis function |
| 3 | Sigmoid—Sigmoid function |
|
 |
degree specifies the degree coefficient of the kernel function. The default is 3.
|
|
gamma specifies the gamma coefficient of the kernel function. The default is 1.
|
|
coef0 specifies the coef0 coefficient of the kernel function. The default is 0.
|
|
 |
weighted c specifies different weights of parameter c for different classes in the training data. Use this input when the training data is unbalanced. In unbalanced data, the number of samples for some classes is much greater than that in other classes. If you specify this input, the Deploy Classification Model VI cannot return the predicted probabilities.
|
label specifies the label of the data to assign weight.
|
|
weight specifies the weight to assign to the label.
|
|
|
tolerance specifies the tolerance for the stopping criteria. The default is 0.001.
|
|
max iteration specifies the maximum number of optimization iterations for the stopping criteria. The default is 100000. The model fitting stops if the number of optimization iterations reaches max iteration.
|










