Deploying Deep Learning Models to NI Hardware
Contents
- Deep Learning Overview
- Using Deep Learning
- Deploy a Deep Learning Model with LabVIEW
- Additional Resources
Deep Learning Overview
Deep Learning is a mathematical method to find patterns and make decisions by training neural networks with large amounts of data to make decisions like is a part is detected? What is it? Is it “good” or “bad? Where it is located? The initial training will take time and many images, but the benefit is that the model you develop can be trained to make decisions in a variety of conditions without having to define the decision criteria.
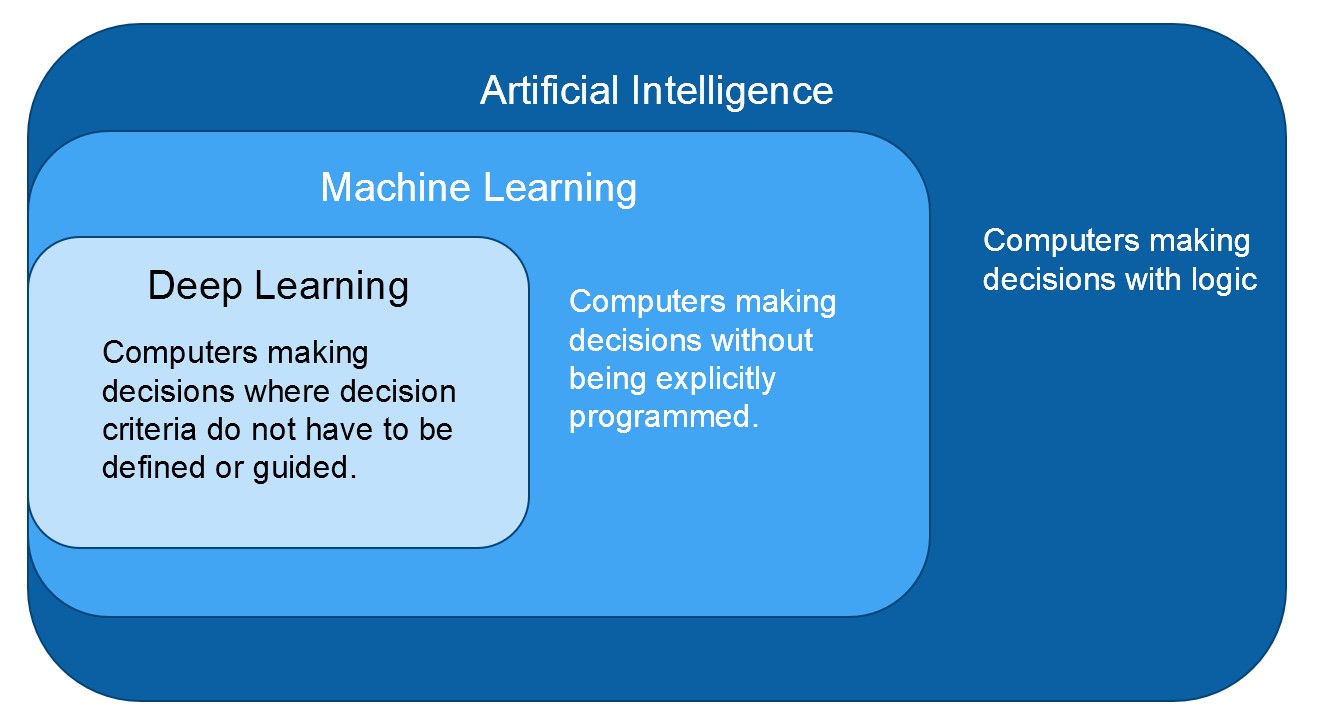
Figure 1: Deep Learning is Subset of Machine Learning
Machine vision tools already take advantage of Machine Learning. To understand the differences between Machine Learning and Deep Learning let’s think about an identification problem. On a production line you want to understand whether a finished part is ready to ship or if it has a defect. To do this, you might create a region of interest around the part, determine an ideal template (or several templates) and compare against them to determine a pass or fail. This method allows you to quickly perform a pass/fail inspection on a part where the parameters for “good” and “bad” can be limited by a region of interest and a template (or several templates). You did not explicitly program the parameters, but we are using the template to help the algorithm determine what features of the part are most important for determining a match.
With a deep learning approach, neural networks with multiple layers are used, each layer and neuron are analyzing subsets of the image -- attempting to find patterns for what makes the part “good” or “bad” and rather than comparing against a template, hundreds of labeled good and bad images are analyzed by the network and the decision criteria are determined during this training. As the network learns it will automatically define and weight the features of the image that are most important for making the decision.
There are many tools for training deep learning models. The Vision Development module currently supports TensorFlow-an open source tool from Google that helps develop Deep Learning Models for a variety of applications and requirements. The Vision Development Module helps you deploy these deep learning models on NI Hardware, so you can use the capabilities of LabVIEW to acquire the image, pass it to the model, and then interface with your inspection architecture or hardware based on the results. You can learn more about getting started with TensorFlow here.
Using Deep Learning
Deep Learning is useful in vision applications when the pass or failure conditions are difficult to define, or the environmental complexity is high because of changing lighting or inspection orientations. Maybe there are slight variations in the parts that you want to inspect, or the location or orientation of the part could change image to image. In these cases, it would be worth the time and effort of generating and training a deep learning model to gain accurate insight. These insights can be divided into three categories:
Detection: Is the object present?
Classification: What is the object?
Segmentation: Where is the object?
When you are trying to gain this type of insight, the environment can get so complex that training deep learning algorithms to adapt to these changing conditions can save a large amount of development time and will be more accurate than machine vision tools like pattern matching. Plus, in some cases, building a model from scratch is not necessary. There are pre-built models available in the TensorFlow Model Zoo.
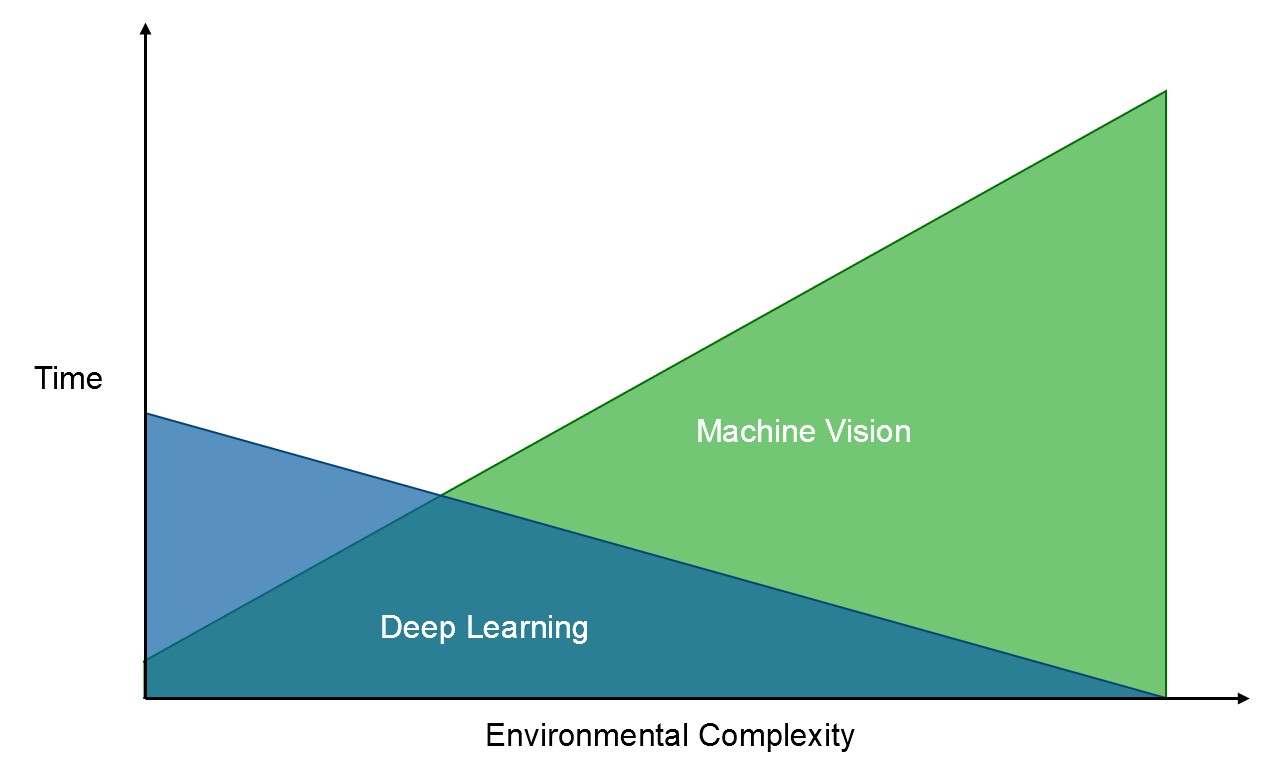
Figure 2: Weighing Deep Learning Training Time over Machine Vision Development Time for Complex Problems
Deep Learning requires training time and images (in many cases hours of training time over hundreds or thousands of images). If an object or feature can be quickly detected using a machine vision pattern matching algorithm, then machine vision is the right approach. However, when the complexity requires tens or hundreds of different templates or the environment cannot be controlled so that conditions like lighting or camera angle will not be constant then it will take more time to try to determine the features of the template that need to be highlighted in each situation. In these situations, using a Deep Learning model lets you analyze a previously un-analyzable image because of the complexity.
Deploy a Deep Learning Model with LabVIEW
The Vision Development Module in LabVIEW works with frozen deep learning models developed using Tensor Flow. You can deploy these models on Windows 64-bit and Linux RT 64-bit operating systems to perform inference (applying the previously trained model to newly acquired images). If you are developing a deep learning model using Keras, (a higher-level TensorFlow tools for building Deep Learning models), then you will need to convert it to a frozen model before deployment.
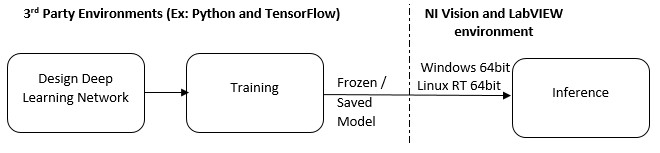
Figure 3: Deep Learning Workflow
After you develop a compatible model, you can use LabVIEW to load the trained model, configure the inputs and outputs, and run the model to analyze your product or device. Vision Development Module includes a built-in example of deploying a Deep Learning Model to help get started.

Figure 4: Deep Learning Functions in Vision Development Module
Additional Resources
- Now that you have learned about deploying deep learning models using Vision Development Module, you can download an evaluation here.
- Do you need Cameras, Frame Grabbers, Lighting, or computer hardware for image processing? Visit NI Vision Hardware to select the right vision hardware for your inspection system.
The registered trademark Linux® is used pursuant to a sublicense from LMI, the exclusive licensee of Linus Torvalds, owner of the mark on a worldwide basis.