FL - Regel erstellen
- Aktualisiert2025-07-30
- 6 Minute(n) Lesezeit
Erzeugt eine Regel für ein Fuzzy-System. Interaktiv werden Regeln auf der Seite Regel-Editor des Fuzzy-System-Designers erstellt.
Ein-/Ausgänge
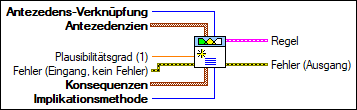
 Antezedens-Verknüpfung
—
Antezedens-Verknüpfung
—
Antezedens-Verknüpfung gibt an, wie das VI den Wahrheitswert des zusammengerechneten Regel-Antezedens berechnen soll.
 Antezedenzien
—
Antezedenzien
—
Antezedenzien gibt die Antezedenzien, also die "Wenn"-Teile, der Regel an. Jedes Antezedens besteht aus drei Teilen: 1. dem Index einer linguistischen Variablen, 2. einem Operator, der angibt, ob der Zugehörigkeitsgrad oder der Nichtzugehörigkeitsgrad der linguistischen Variablen zu einem linguistischen Term berechnet werden soll, und 3. einem Index des linguistischen Terms. Die Variablen oder linguistischen Terme sind ihrer Erstellungsreihenfolge nach indiziert. Die Antezedenzien werden einzeln mit dem VI FL - Antezedens erstellen erzeugt und entweder mit der Funktion Array erstellen oder mit einer Schleife zu einem Array zusammengefasst. Das Array kann mit diesem Eingang verbunden werden.
 Plausibilitätsgrad (1)
—
Plausibilitätsgrad (1)
—
Plausibilitätsgrad gibt die Gewichtung der Regel zwischen 0 und 1 an. Der Standardwert lautet 1. Durch Multiplizieren des Plausibilitätsgrads mit dem Wahrheitswert des zusammengerechneten Regel-Antezedens ergibt sich die Regelgewichtung.  Fehler (Eingang, kein Fehler)
—
Fehler (Eingang, kein Fehler)
—
Fehler (Eingang) beschreibt Fehlerbedingungen, die vor der Ausführung des Knotens auftreten. An Fehler (Eingang) werden Standardfehlerdaten übergeben.
Konsequenzen
—
Konsequenzen gibt die Konsequenzen, also die "Dann"-Teile, der Regel an. Jede Konsequenz besteht aus drei Teilen: 1. dem Index einer linguistischen Variablen, 2. einem Operator, der angibt, ob der Zugehörigkeitsgrad oder der Nichtzugehörigkeitsgrad der linguistischen Variablen zu einem linguistischen Term berechnet werden soll, und 3. einem Index des linguistischen Terms. Die Variablen oder linguistischen Terme sind ihrer Erstellungsreihenfolge nach indiziert. Die Konsequenzen werden einzeln mit dem VI FL - Konsequenz erstellen erzeugt und entweder mit der Funktion Array erstellen oder mit einer Schleife zu einem Array zusammengefasst. Das Array kann mit diesem Eingang verbunden werden.
Implikationsmethode
—
Implikationsmethode gibt die Implikationsmethode an, die -- unter Zuhilfenahme der Regelgewichtung -- zum Skalieren der Zugehörigkeitsfunktionen der linguistischen Ausgangsvariablen verwendet werden soll.
 Regel
—
Regel
—
Regel gibt die Regel mit den festgelegten Antezedenzien, Konsequenzen und Beziehungen an.
 Fehler (Ausgang)
—
Fehler (Ausgang)
—
Fehler (Ausgang) enthält Angaben zum Fehler. Dieser Ausgang ist ein Standardausgang zur Fehlerausgabe. |
 Var-Index
—
Var-Index
—
 Antezedenzien
—
Antezedenzien
—
 Var-Index
—
Var-Index
—
 Bed
—
Bed
—
 Plausibilitätsgrad
—
Plausibilitätsgrad
—