Programmierstrategien für Multicore-Prozessoren: Datenparallelität
Überblick
Dieses Whitepaper ist Bestandteil der Serie „Grundlagen der Multicore-Programmierung“

Inhalt
- Datenparallelität
- Datenparallelität in LabVIEW
- Datenparallelität in einer Anwendung
- Weitere Informationen zur Multicore-Programmierung finden Sie unter:
Datenparallelität
Datenparallelität ist eine Programmiertechnik, bei der ein großer Datensatz in kleinere Abschnitte aufgeteilt wird, die parallel verarbeitet werden können. Nachdem die Daten verarbeitet wurden, werden sie wieder zu einem Datensatz verbunden. Mithilfe dieser Technik können Programmierer einen Prozess, der normalerweise die Leistung der Multicore-Verarbeitung nicht in Anspruch nehmen kann, so ändern, dass er die gesamte verfügbare Verarbeitungsleistung effektiv nutzen kann.
Abbildung 1 zeigt einen großen Datensatz, der von einem einzelnen Prozessor bearbeitet wird. In diesem Fall sind die anderen drei CPU-Kerne, die zur Verfügung stehen, nicht im Betrieb, während der erste Prozessor die Verarbeitungslast für den gesamten Datensatz übernimmt.
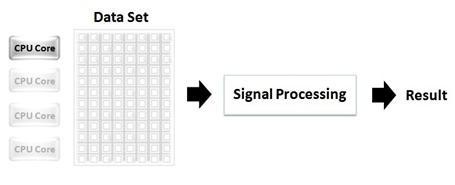
Abb. 1: Bei traditionellen Programmiermethoden wird ein großer Datensatz auf einem einzigen CPU-Kern verarbeitet, die anderen CPU-Kerne warten währenddessen.
Die in Abbildung 2 gezeigte Implementierung nutzt Datenparallelität, um die von einem Prozessor mit vier Kernen gebotene Verarbeitungsleistung voll auszunutzen. In diesem Fall wird der große Datensatz in vier Teilsätze aufgeteilt. Jeder Teilsatz wird einem einzelnen Kern zur Verarbeitung zugewiesen. Nach Abschluss der Verarbeitung werden die Teilsätze wieder zu einem einzigen kompletten Datensatz zusammengefügt.
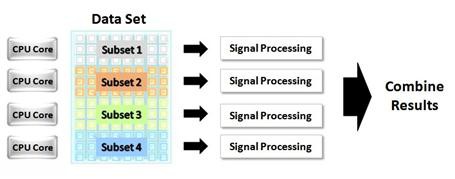
Abb. 2: Dank der Datenparallelität kann ein großer Datensatz parallel auf mehreren CPU-Kernen verarbeitet werden.
Die grafische Programmierumgebung NI LabVIEW eignet sich hervorragend für parallele Datenarchitekturen. Die parallele Verarbeitung in NI LabVIEW ist intuitiv und einfach. Traditionelle textbasierte Sprachen hingegen erfordern fortgeschrittene Programmierkenntnisse, um multithreading-fähige Anwendungen zu erstellen.
Datenparallelität in LabVIEW
Der Programmcode in Abbildung 3 zeigt eine Matrixmultiplikation, die auf zwei Matrizen ausgeführt wird: Matrix 1 und Matrix 2. Das ist eine Standardimplementierung in LabVIEW einer Multiplikation zweier großer Matrizen.
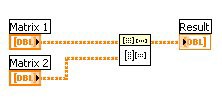
Abb. 3: Eine Matrixmultiplikation nutzt in LabVIEW keine Datenparallelität.
Eine Verarbeitung wie diese kann zur Fertigstellung viel Zeit in Anspruch nehmen, besonders dann, wenn große Datensätze dabei sind. Der Code in Abbildung 3 zieht keinerlei Nutzen aus der zusätzlichen Computerleistung, die von einem Multicore-Prozessor geboten wird, es sei denn, das VI „Matrix Multiply“ ist bereits multithreading-fähig implementiert und komplett für einen Multicore-Prozessor optimiert. Dagegen nutzt der Programmcode in Abbildung 4 Datenparallelität und kann daher erheblich schneller auf einem Dual-Core-Prozessor ausgeführt werden als der in Abbildung 3 gezeigt Code.
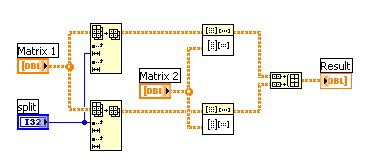
Abb. 4: Dieser LabVIEW-Code stellt die Datenparallelität dar. Durch Halbierung der Matrix kann die Operation simultan auf zwei CPU-Kernen verarbeitet werden.
Wird diese Technik in LabVIEW genutzt, um die Leistung auf einem Multicore-Prozessor zu steigern, muss man wissen, dass eine Leistungsverbesserung nur erreicht werden kann, wenn das VI „Matrix Multiply“ ablaufinvariant ist. Ist es das nicht, können die einzelnen Instanzen des VIs nicht unabhängig und gleichzeitig arbeiten.
In der folgenden Tabelle werden Vergleichswerte für die Ausführungszeit des LabVIEW-Codes in Abbildung 3 und 4 gezeigt, wobei 1000 x 1000 Matrizen für die Eingangsmatrizen genutzt werden. Eine Leistungsverbesserung wird selbst auf einem Single-Core-Prozessor erreicht, wenn Datenparallelität eingesetzt wird. Bei Dual-Core-Prozessoren kann eine Leistungsverbesserung um beinahe das Zweifache festgestellt werden, wenn Datenparallelität genutzt wird.
|
| Ausführungszeit auf Single-Core-Prozessor | Ausführungszeit auf Dual-Core-Prozessor |
| Matrixmultiplikation ohne Datenparallelität | 1,224 Sekunden | 1,159 Sekunden |
| Matrixmultiplikation mit Datenparallelität | 1,195 Sekunden | 0,629 Sekunden |
Datenparallelität in einer Anwendung
Mit Datenparallelität und ähnlichen Techniken können Programmierer die Multicore-Verarbeitungsleistung voll ausnutzen. Eine Umstrukturierung von Prozessen, die an sich nicht parallel sind, trägt dazu bei, dass Softwarearchitekten das volle Potenzial von Multicore-Prozessoren einsetzen können. LabVIEW bildet dabei ganz unkompliziert die Parallelität im Programmcode ab.