NI does not actively maintain this document.
This content provides support for older products and technology, so you may notice outdated links or obsolete information about operating systems or other relevant products.

Dieses Whitepaper beschreibt die Herausforderungen, denen Programmierer von Multicore-Anwendungen heutzutage gegenüberstehen. Das Dokument behandelt die vielfältigen Multicore-Programmiermuster, die in einer Softwarearchitektur angewendet werden können.
Da Programmiermuster detailliert in der Fachliteratur behandelt werden, gibt dieses Dokument einen Überblick über die folgendenen Konzepte und stellt ihre Anwendung in LabVIEW differenziert dar:
1. Task-Parallelität
2. Datenparallelität
3. Pipelining
4. Strukturierte Gittermuster
Aus Softwaresicht sollte ein paralleles Ablaufmuster integriert werden, das am besten zur Aufgabenstellung der Anwendung passt. Bevor man sich für ein Muster entscheidet, sollten sowohl Anwendungscharakteristik als auch die Hardwarearchitektur in Betracht gezogen werden.
Darüber hinaus werden verschiedene LabVIEW-Strukturen im Zusammenhang mit oben aufgeführten Mustern (reguläre While-Schleifen, Feedback-Knoten, Schieberegister, zeitgesteuerte Schleifen und parallele For-Schleifen) behandelt.
Parallel ablaufende Tasks stellen die einfachste Form der parallelen Programmierung dar. Die Anwendung wird dabei in einzelne, voneinander unabhängig Aufgaben (Tasks) unterteilt, die auf verschiedenen Prozessoren ausgeführt werden können. Ein Beispiel wäre ein Programm mit zwei Schleifen (Schleife A und Schleife B), wo Schleife A eine Signalverarbeitungsroutine und Schleife B Updates der Benutzeroberfläche ausführt. Hier spricht man von Task-Parallelität, denn eine Multithreading-fähige Anwendung kann diese zwei Schleifen in separaten Threads auf zwei verschiedenen Prozessoren ausführen.
Die Task-Parallelität in LabVIEW wird durch parallele Codeabschnitte auf dem Blockdiagramm erzielt. Der Vorteil von LabVIEW gegenüber textbasierten Programmiersprachen ist, dass man die Parallelität des Programmcodes "sehen" und so einzelne Tasks einfach voneinander trennen kann. Außerdem teilt LabVIEW eine Anwendung automatisch in mehrere Threads auf, so dass sich der Anwender keine Gedanken um die Thread-Verwaltung oder die Synchronisierung von Threads machen muss.
Die Datenparallelität lässt sich auf große Datensätze anwenden, indem ein umfangreiches Array oder eine Matrix in Untereinheiten aufgeteilt, die jeweilige Operation durchgeführt und die Ergebnisse danach wieder kombiniert werden.
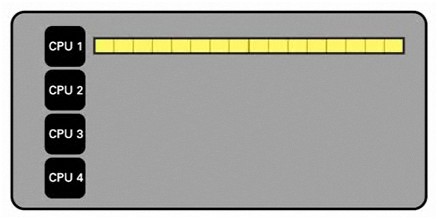
Zum besseren Verständnis wird hier zunächst eine sequenzielle Implementierung dargestellt, bei der ein einzelner Prozessor den gesamten Datensatz verarbeiten muss.
Abbildung: Verarbeitung mit einem Prozessor
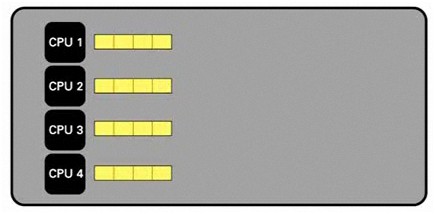
Zum Vergleich wird hier derselbe Datensatz in vier Threads aufgeteilt. Jetzt lassen sich die Teildaten auf die verfügbaren Cores verteilen und dieselbe Operation kann viel schneller durchgeführt werden.
Abbildung: Verarbeitung mit mehreren Prozessoren
Beim echtzeitfähigen Hochleistungsrechnen (HPC, High-Performance Computing) wie etwa in Steuer- und Regelsystemen ist die parallele Ausführung von Matrix-Vektor-Multiplikationen beträchtlicher Größe eine gängige und effiziente Strategie. Meist ist die Matrix fix und kann im Voraus aufgeschlüsselt werden. Von Sensoren erfasste Messungen liefern jeweils einen Vektor pro Schleifendurchlauf. So kann das Ergebnis des Matrix-Vektors zur Steuerung von Aktoren verwendet werden.
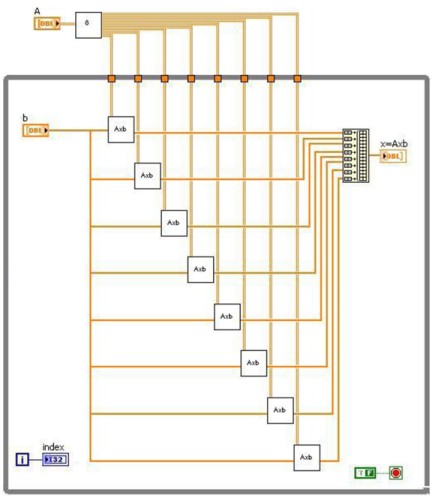
Folgendes Blockdiagramm zeigt eine auf acht Cores aufgeteilte Matrix-Vektor-Multiplikation.
Abbildung: Matrix-Vektor-Multiplikation in LabVIEW
Das Blockdiagramm führt von links nach rechts folgende Schritte aus:
1. Aufteilung von Matrix A vor Eingang in die While-Schleife
2. Multiplikation jedes Teils von Matrix A mit Vektor b
3. Kombination der resultierenden Vektoren zum Endergebnis x = A x b
Pipelining ähnelt in gewisser Hinsicht der Fließbandarbeit. Besonders hilfreich ist es in Streaming-Anwendungen und wenn ein prozessorintensiver CPU-Algorithmus sequenziell modifiziert werden muss und jeder Schritt zeitaufwändig ist.
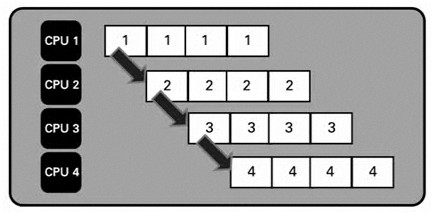
Abbildung: Sequenzielle Phasen eines Algorithmus
Wie bei einem Fließband entspricht jede Phase einem Arbeitsgang. Jedes Ergebnis geht zur nächsten Phase über, bis es "fertig" ist.
Um eine Pipelining-Strategie auf eine Applikation anzuwenden, die auf einem Multicore-Prozessor laufen wird, teilt man den Algorithmus in Schritte auf, die ungefähr den gleichen Rechenaufwand verursachen und führt jeden Schritt auf einem separaten Core aus. Der Algorithmus kann an mehreren Datensätzen oder an kontinuierlich per Streaming übertragenen Daten wiederholt werden.
Abbildung: Pipelining-Strategie
Der Schlüssel hierbei ist, den Algorithmus in Schritte aufzuteilen, die jeweils ca. gleich viel Zeit benötigen, da jeder Durchlauf so lange braucht wie der längste einzelne Schritt im Gesamtprozess. Braucht also Schritt 2 eine Minute, die Schritte 1, 3 und 4 aber jeweils nur 10 Sekunden, dauert der gesamte Durchlauf eine Minute.
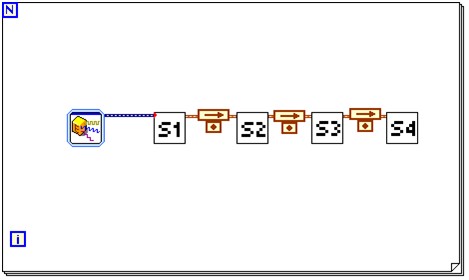
Das LabVIEW-Blockdiagramm in Abbildung 4 zeigt ein Beispiel für die Pipelining-Strategie. Eine For-Schleife enthält die Phasen S1, S2, S3 und S4, die für die Funktionen im Algorithmus stehen, welche nacheinander ablaufen müssen. Da LabVIEW eine strukturierte Datenflusssprache ist, bewegt sich die Ausgabe jeder Funktion den Draht entlang zum Eingang der nächsten.
Abbildung: Pipelining in LabVIEW
Hier erscheint jeweils ein Feedback-Knoten als Pfeil über einem kleinen Punkt. Feedback-Knoten zeigen eine Aufteilung der Funktionen in separate Pipelining-Phasen an. Eine nicht in Pipelines gegliederte Version desselben Codes sieht ähnlich aus, hat aber keine Feedback-Knoten. Beispiele, die diese Technik häufig nutzen, sind Streaming-Anwendungen, bei denen Fast-Fourier-Transformationen (FFTs) immer nur einen Schritt gleichzeitig verarbeiten.
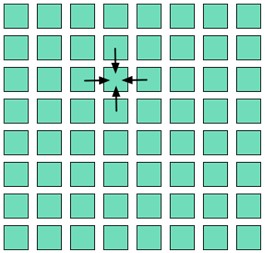
Viele Berechnungen rund um physikalische Modelle verwenden ein strukturiertes Gittermuster. Bei diesem Muster berechnet man mit jedem Durchlauf ein 2D- oder ND-Gitter und jeder aktualisierte Gitterwert ist eine Funktion seiner Nachbarn (siehe Abbildung 8).
Abbildung: Strukturierte Gittermuster
Bei einer parallelen Version eines strukturierten Gittermusters wird das Gitter in kleinere Einheiten aufgeteilt und jedes kleine Gitter wird einzeln berechnet. Die Threads müssen nur über die an den Rändern liegenden Felder Daten austauschen. Die parallele Effizienz ist eine Funktion des Verhältnisses von der Fläche zum Umfang des Musters.
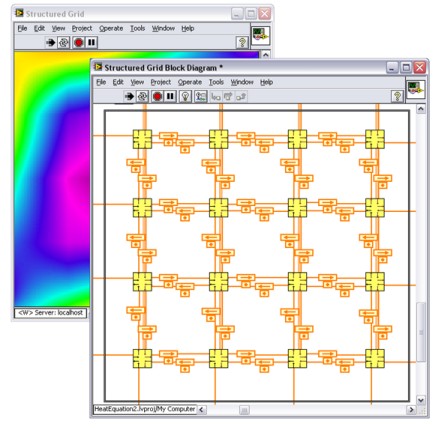
So kann beispielsweise das Blockdiagramm in folgender Abbildung die Wärmegleichung lösen, wo sich die Randbedingungen ständig ändern.
Abbildung: Strukturierte Gittermuster in LabVIEW
Die 16 sichtbaren Symbole stellen Tasks dar, welche die Laplace-Gleichung einer bestimmten Gittergröße lösen können, wobei die Laplace-Gleichung eine Methode zur Lösung der Wärmegleichung ist. Die 16 Tasks beziehen sich auf 16 Cores. Einmal während des Schleifendurchlaufs tauschen diese Cores Randbedingungen aus und der Prozess erstellt eine globale Lösung. Die Feedback-Knoten, die als Pfeile über kleinen Punkten dargestellt werden, weisen auf den Datenaustausch zwischen Elementen hin. Solche Blockdiagramme können genauso auf Computern mit einem, zwei, vier oder acht Cores ausgeführt werden. Auch wenn in Zukunft Computer mit noch mehr Kernen verfügbar sind, kann diese Strategie weiter verfolgt werden.
While-Schleifen sind elementare Strukturen, die mit einer Vielzahl von Programmiermustern eingesetzt werden. Je nach dem jeweiligen Muster reicht eine reguläre While-Schleife, während in anderen Situationen eine spezielle Art von While-Schleife (wie etwa die zeitgesteuerte Schleife) in Frage kommt.
Für die oben beschriebene Pipelining-Strategie sollten entweder Schieberegister oder Feedback-Knoten verwendet werden (beide verhalten sich in diesem Szenario gleich).
Die parallele For-Schleife ermöglicht die programmatische Einstellung der Anzahl paralleler "Arbeiter"-Threads, die den Code ausführen, um implizite Parallelität zu erzielen. Das heißt, dass nicht explizit in parallelen Strukturen programmiert werden muss, sondern der Schleifencode automatisch auf mehrere Prozessorkerne aufgeteilt wird. Es sollte ein Thread für jeden Prozessorkern erstellt werden, um die parallele Ausführung zu maximieren.
Die parallele For-Schleife ist eine gute Methode für rechenintensive Vorgänge, die oft wiederholt werden müssen und keine Abhängigkeiten von einem Durchlauf zum nächsten aufweisen. Gibt es allerdings Abhängigkeiten, eignet sich die parallele For-Schleife nicht, denn diese Abhängigkeiten bedeuten, dass der Algorithmus sequenziell ausgeführt werden muss. In diesem Fall ist eine andere Technik, etwa Pipelining, vorzuziehen, um Parallelität zu erzielen.
Die zeitgesteuerte Schleife fungiert als While-Schleife, hat jedoch auch einige zusätzliche Eigenschaften, die helfen können, die Leistung auf Multicore-Hardware zu optimieren. Beispielsweise wird, anders als bei einer normalen While-Schleife, die mehrere Threads ausnutzen kann, Programmcode innerhalb einer zeitgesteuerten Schleife stets in einem einzigen Thread ausgeführt. Das scheint nicht besonders intuitiv zu sein und man mag sich fragen, warum auf einem Multicore-System eine Ausführung in nur einem Thread wünschenswert sein sollte. Besonders in Echtzeitsystemen und bei der Optimierung für Caches ist das eine nützliche Eigenschaft. Neben der Ausführung in einem einzigen Thread kann die Schleife die Ressourcenzuweisung festlegen. Hierbei handel es sich um einen Mechanismus, der einen Thread einem bestimmten Prozessor zuweist (und damit zur Cache-Optimierung beiträgt).
Besonders zu beachten ist, dass parallele Muster, die innerhalb einer normalen While-Schleife (etwa bei Datenparallelität und Pipelining) gut funktionieren, in einer zeitgesteuerten Schleife nicht einsetzbar sind, da innerhalb eines einzigen Threads keine Parallelität möglich ist. Stattdessen können diese Techniken mittels mehrerer zeitgesteuerter Schleifen implementiert werden. So kann eine zeitgesteuerte Schleife eine einzelne Phase in einer Pipeline darstellen, wobei die Datenübertragung zwischen den Schleifen über FIFOs erfolgt.
Queues sind wichtig für die Synchronisation von Daten zwischen mehreren Schleifen. Sie können z. B. verwendet werden, um eine Producer/Consumer-Architektur zu implementieren. Die Producer/Consumer-Architektur wird im vorliegenden Dokument nicht spezifisch behandelt, da sie nicht nur bei der parallelen Programmierung vorkommt und eher als eine universelle Programmierarchitektur dient. Trotzdem sorgt sie auf Multicore-Prozessoren für die Minimierung der Prozessorauslastung. Möglich gemacht wird das durch die Kombination von Schleifen und Queues.
Queues sind allerdings kein deterministischer Mechanismus für die Datenübertragung zwischen Schleifen. Für Echtzeitanforderungen sollten daher Real-Time-FIFOs verwendet werden.
In LabVIEW Real-Time können Prozessoren mit den sogenannten CPU Pool VIs für bestimmte Thread-Pools "reserviert" werden. Auch dieser Mechanismus optimiert die Cache-Auslastung.
Beispielhaft dafür wäre eine Anwendung, die auf einem Quad-Core-System ausgeführt wird, wobei die Anwendung Daten wiederholt so schnell wie möglich bearbeiten soll. Diese Art Vorgang eignet sich gut zum Ablauf aus dem Cache, solange der Datensatz in den Prozessor-Cache passt. Die Ausführung im Cache kann sogar effektiver sein, als zu versuchen, den Code in parallele Threads aufzuteilen und alle vier Prozessoren zu verwenden. Anstatt also dem Betriebssystem die Zuteilung paralleler Tasks an alle vier Prozessoren (0-3) zu erlauben, kann der Entwickler dem Scheduler des Betriebssystems nur zwei Cores, z. B. 0 und 2, zuteilen. (Der entsprechende Quad-Core hat vielleicht einen großen gemeinsamen Cache für Core 0 und 1 und einen weiteren für 2 und 3). Werden Cores wie beschrieben zugeteilt, kann sichergestellt werden, dass die Daten im Cache bleiben und dass zwei große gemeinsame Caches ganz für die jeweilige Operation zur Verfügung stehen.
Die CPU Information VIs bieten Informationen speziell über das System, auf dem die LabVIEW-Anwendung läuft. Diese Informationen sind sehr nützlich, wenn die Anwendung auf vielen unterschiedlichen Maschinen ausgeführt wird (etwa Dual-Cores, Quad-Cores oder sogar Rechnern mit acht Kernen).
Mithilfe der CPU Information VIs kann die Anwendung Parameter wie die Anzahl der logischen Prozessoren auslesen und basierend darauf eine parallele For-Schleife entsprechend konfigurieren.
Läuft die Anwendung beispielsweise auf einem Dual-Core-Prozessor, ist die Anzahl der Logikprozessoren gleich zwei. Die optimale Einstellung für die parallele For-Schleife wäre also auch zwei. So kann Programmcode einfacher an die zugrundeliegende Hardware angepasst werden.
Tracing eignet sich gut, um Fehler in Multicore-Anwendung zu beheben. Es kann sowohl auf dem Desktop als auch auf einem Echtzeitsystem vorgenommen werden. Weitere Informationen dazu sind der Produktdokumentation des Desktop Execution Trace Toolkit und des Real-Time Execution Trace Toolkit zu entnehmen.
In jedem Fall sollte ein Programmiermuster gwählt werden, das gut zur jeweiligen Anwendung passt. Die hier behandelten Ablaufmuster waren Task-Parallelität, Datenparallelität, Pipelining und strukturierte Gittermuster.
Um diese Muster voll auszuschöpfen, sollten LabVIEW-Entwickler verschiedene Strukturen, VIs und Fehlerbehebungswerkzeuge integrieren.