TDMS-Dateiformat – interne Struktur
Überblick
Inhalt
- Logische Struktur
- Binäres Layout
- Vordefinierte Eigenschaften
- Optimierung
- Fazit
- Zusätzliche Ressourcen
Logische Struktur
TDMS-Dateien organisieren Daten in einer dreistufigen Objekthierarchie. Die oberste Ebene besteht aus einem einzelnen Objekt, das dateispezifische Informationen wie Autor oder Titel enthält. Jede Datei kann eine unbegrenzte Anzahl von Gruppen und jede Gruppe wiederum eine unbegrenzte Anzahl von Kanälen enthalten. In der folgenden Abbildung enthält die Datei example events.tdms zwei Gruppen, von denen jede zwei Kanäle enthält.
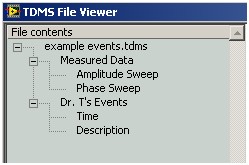
Jedes TDMS-Objekt wird durch einen Pfad eindeutig identifiziert. Jeder Pfad ist ein String mit dem Namen des Objekts und dem Namen seines Eigentümers in der TDMS-Hierarchie, getrennt durch einen Schrägstrich. Jeder Name ist in Anführungszeichen gesetzt. Jedes einfache Anführungszeichen (Hochkomma) innerhalb eines Objektnamens wird durch doppelte Anführungszeichen ersetzt. Die folgende Tabelle enthält Beispiele für die Pfadformatierung für jeden TDMS-Objekttyp:
| Objektname | Objekt | Pfad |
| -- | Datei | / |
| Measured Data | Gruppe | /'Measured Data' |
| Amplitude Sweep | Kanal | /'Measured Data'/'Amplitude Sweep' |
| Dr. T's Events | Gruppe | /'Dr. T''s Events' |
| Zeit | Kanal | /'Dr. T''s Events'/'Time' |
Damit alle TDMS-Clientanwendungen korrekt funktionieren, muss jede TDMS-Datei ein Dateiobjekt enthalten. Ein Dateiobjekt muss für jeden in einem Kanalpfad verwendeten Gruppennamen ein Gruppenobjekt enthalten. Darüber hinaus kann ein Dateiobjekt eine beliebige Anzahl von Gruppenobjekten ohne Kanäle enthalten.
Jedes TDMS-Objekt kann über eine unbegrenzte Anzahl von Eigenschaften verfügen. Jede TDMS-Eigenschaft besteht aus einem Namen (immer ein String), einem Typbezeichner und einem Wert. Typische Datentypen für Eigenschaften umfassen numerische Typen wie Integer oder Gleitkommazahlen, Zeitstempel oder Strings. Arrays werden von TDMS-Eigenschaften nicht unterstützt. Befindet sich eine TDMS-Datei in einem Suchbereich von NI DataFinder, stehen alle Eigenschaften automatisch für die Suche zur Verfügung.
Nur Kanalobjekte in TDMS-Dateien können Rohdaten-Arrays enthalten. In aktuellen TDMS-Versionen werden nur 1-D-Arrays unterstützt.
Binäres Layout
Jede TDMS-Datei enthält zwei Typen von Daten: Metadaten und Rohdaten. Metadaten sind beschreibende Daten, die in Objekten oder Eigenschaften gespeichert sind. An Kanalobjekte angehängte Daten-Arrays werden als Rohdaten bezeichnet. TDMS-Dateien enthalten Rohdaten für mehrere Kanäle in einem zusammenhängenden Block. Um Rohdaten aus diesem Block extrahieren zu können, nutzen TDMS-Dateien einen Rohdatenindex. Dieser enthält Informationen zur Datenblockzusammensetzung, einschließlich des Kanals, der den Daten entspricht, der Anzahl der Werte, die der Block für diesen Kanal enthält, und der Reihenfolge, in der die Daten gespeichert wurden.
Layout von TDMS-Segmenten
Daten werden in Form von Segmenten in TDMS-Dateien geschrieben. Jedes Mal, wenn Daten an eine TDMS-Datei angehängt werden, wird ein neues Segment erstellt. Ausnahmen von dieser Regel finden Sie in den Abschnitten Metadaten und Rohdaten dieses Artikels. Ein Segment besteht aus den folgenden drei Teilen:
- Einleitung: Enthält grundlegende Informationen wie das Tag, das Dateien als TDMS identifiziert, eine Versionsnummer und die Längeninformationen zu den Metadaten und Rohdaten.
- Metadaten: Enthält die Namen und Eigenschaften aller Objekte im Segment. Bei Objekten, die Rohdaten enthalten (Kanäle), enthält der Metadatenteil auch Indexinformationen, mit denen die Rohdaten für dieses Objekt im Segment lokalisiert werden.
- Rohdaten: Ein zusammenhängender Block aller Rohdaten, die mit den im Segment enthaltenen Objekten verknüpft sind. Der Rohdatenteil kann Interleave-Datenwerte oder eine Reihe zusammenhängender Datenmengen enthalten. Der Rohdatenteil kann außerdem Rohdaten aus DAQmx enthalten.
Alle Strings in TDMS-Dateien, wie Objektpfade, Eigenschaftsnamen, Eigenschaftswerte und Rohdatenwerte, werden in UTF-8-Unicode codiert. Mit Ausnahme der Rohdatenwerte wird allen ein vorzeichenloser 32-Bit-Integer vorangestellt, der die Länge der Strings in Byte enthält, ohne den Längenwert selbst. Strings in TDMS-Dateien können nullterminiert sein. Da die Längeninformationen jedoch gespeichert sind, wird der Nullterminator beim Lesen der Datei ignoriert.
Zeitstempel in TDMS-Dateien werden als Struktur mit zwei Komponenten gespeichert:
- (i64) Sekunden: seit dem Zeitpunkt 01.01.1904, 00:00:00.00 UTC (unter Verwendung des gregorianischen Kalenders und bei Ignorieren von Schaltsekunden)
- (u64) positive Bruchteile: (2^-64) einer Sekunde
Boolesche Werte werden jeweils als 1 Byte gespeichert, wobei 1 für TRUE und 0 für FALSE steht.
Einleitung
Die Einleitung enthält Informationen zur Validierung eines Segments. Sie enthält zudem Informationen für den Zufallszugriff auf eine TDMS-Datei. Das folgende Beispiel zeigt den binären Footprint der Einleitung einer TDMS-Datei:
| Binäres Layout (hexadezimal) | Beschreibung |
| 54 44 53 6D | „TDSm“-Tag |
| 0E 00 00 00 | ToC-Maske 0x1110 (Segment enthält Objektliste, Metadaten, Rohdaten) |
| 69 12 00 00 | Versionsnummer (4713) |
| E6 00 00 00 00 00 00 00 | Nächster Segment-Offset (Wert: 230) |
| DE 00 00 00 00 00 00 00 | Rohdaten-Offset (Wert: 222) |
Die Einleitung in der vorherigen Tabelle enthält die folgenden Informationen:
- Die Einleitung beginnt mit einem 4-Byte-Tag, das ein TDMS-Segment („TDSm“) identifiziert.
- Die nächsten vier Byte werden als Bitmaske verwendet und geben an, welche Art von Daten das Segment enthält. Diese Bitmaske wird als ToC (Inhaltsverzeichnis) bezeichnet. Im ToC kann eine beliebige Kombination der folgenden Flags codiert werden:
Flag Beschreibung #define kTocMetaData (1L<<1) Segment enthält Metadaten #define kTocRawData (1L<<3) Segment enthält Rohdaten #define kTocDAQmxRawData (1L<<7) Segment enthält DAQmx-Rohdaten #define kTocInterleavedData (1L<<5) Rohdaten im Segment sind verschachtelt (wenn das Flag nicht gesetzt ist, sind die Daten zusammenhängend) #define kTocBigEndian (1L<<6) Alle numerischen Werte im Segment, einschließlich Einleitung, Rohdaten und Metadaten, haben das Big-Endian-Format (wenn das Flag nicht gesetzt ist, haben die Daten das Little-Endian-Format). ToC ist unabhängig von der Byte-Reihenfolge immer Little-Endian. #define kTocNewObjList (1L<<2) Segment enthält neue Objektliste (z. B. sind Kanäle in diesem Segment nicht mit denen im vorherigen Segment identisch) - Die nächsten vier Byte enthalten eine Versionsnummer (vorzeichenloser 32-Bit-Integer), die die älteste TDMS-Revision angibt, mit der ein Segment konform ist. Zum Zeitpunkt der Verfassung dieses Dokuments lautet die Versionsnummer 4713. Die einzige vorherige Version von TDMS hat die Nummer 4712.
Hinweis: Die Versionsnummer 4713 entspricht der TDMS-Dateiformatversion 2.0 in LabVIEW. Die Versionsnummer 4712 entspricht der TDMS-Dateiformatversion 1.0 in LabVIEW.
- Die nächsten acht Byte (vorzeichenloser 64-Bit-Integer) beschreiben die Länge des verbleibenden Segments (Gesamtlänge des Segments minus Länge der Einleitung). Wenn weitere Segmente an die Datei angehängt werden, können Sie mit dieser Nummer den Startpunkt des folgenden Segments lokalisieren. Wenn ein schwerwiegendes Problem beim Schreiben in eine TDMS-Datei von einer Anwendung aufgetreten ist (Absturz, Stromausfall), können alle Byte dieses Integers 0xFF sein. Das kann nur beim letzten Segment in einer Datei geschehen.
- Die letzten acht Byte (vorzeichenloser 64-Bit-Integer) beschreiben die Gesamtlänge der Metainformationen im Segment. Diese Informationen werden für den Zufallszugriff auf die Rohdaten verwendet. Wenn das Segment überhaupt keine Metadaten (Eigenschaften, Indexinformationen, Objektliste) enthält, lautet dieser Wert 0.
Metadaten
TDMS-Metadaten bestehen aus einer dreistufigen Hierarchie von Datenobjekten, einschließlich Datei, Gruppen und Kanälen. Jeder dieser Objekttypen kann beliebig viele Eigenschaften enthalten. Der Metadatenabschnitt hat das folgende binäre Layout auf dem Datenträger:
- Anzahl neuer Objekte in diesem Segment (vorzeichenloser 32-Bit-Integer).
- Binärschreibweise jedes dieser Objekte.
Das binäre Layout eines einzelnen TDMS-Objekts auf dem Datenträger besteht aus Komponenten in der folgenden Reihenfolge. Abhängig von den in einem bestimmten Segment gespeicherten Informationen enthält das Objekt möglicherweise nur eine Teilmenge dieser Komponenten.
- Objektpfad (String)
- Rohdatenindex
- Wenn diesem Objekt in diesem Segment keine Rohdaten zugewiesen sind, wird anstelle der Indexinformationen ein vorzeichenloser 32-Bit-Integer (0xFFFFFFFF) gespeichert.
- Wenn dieses Objekt DAQmx-Rohdaten in diesem Segment enthält, lauten die ersten vier Byte des Rohdatenindex „69 12 00 00“ (d. h. die Rohdaten enthalten den DAQmx Format Changing Scaler) oder „69 13 00 00“ (d. h. die Rohdaten enthalten den DAQmx Digital Line Scaler). Auf diese ersten vier Byte folgen Informationen zum DAQmx-Rohdatenindex. Weitere Informationen zum FAQmx-Rohdatenindex finden Sie im folgenden Aufzählungspunkt.
- Wenn der Rohdatenindex dieses Objekts in diesem Segment genau mit dem Index übereinstimmt, den dasselbe Objekt im vorherigen Segment hatte, wird anstelle der Indexinformationen ein vorzeichenloser 32-Bit-Integer (0x0000000) gespeichert.
- Wenn das Objekt Rohdaten enthält, die nicht mit den Indexinformationen übereinstimmen, die diesem Objekt im vorherigen Segment zugewiesen waren, wird ein neuer Index für diese Rohdaten gespeichert:
- Länge des Rohdatenindex (vorzeichenloser 32-Bit-Integer)
- Datentyp (tdsDataType-Enum, als 32-Bit-Integer gespeichert)
- Array-Dimension (vorzeichenloser 32-Bit-Integer) (in TDMS-Dateiformatversion 2.0 ist 1 der einzige gültige Wert)
- Anzahl der Werte (vorzeichenloser 64-Bit-Integer)
- Gesamtgröße in Byte (vorzeichenloser 64-Bit-Integer) (nur für Datentypen mit variabler Länge gespeichert, z. B. Strings)
- Wenn der Rohdatenindex der DAQmx-Rohdatenindex ist, enthält der Index die folgenden Informationen:
- Datentyp (vorzeichenloser 32-Bit-Integer), wobei „FF FF FF FF“ angibt, dass die Rohdaten DAQmx-Rohdaten sind)
- Array-Dimension (vorzeichenloser 32-Bit-Integer) (in TDMS-Dateiformatversion 2.0 ist 1 der einzige gültige Wert)
- Anzahl der Werte (vorzeichenloser 64-Bit-Integer), auch als „Blockgröße“ bezeichnet
- Der Vektor von Skalierern für die Formatänderung
- Vektorgröße (vorzeichenloser 32-Bit-Integer)
Folgendes gilt für die Informationen des ersten Skalierers für die Formatänderung. - DAQmx-Datentyp (vorzeichenloser 32-Bit-Integer)
- Rohpufferindex (vorzeichenloser 32-Bit-Integer)
- Rohbyte-Offset innerhalb des Schritts (vorzeichenloser 32-Bit-Integer)
- Beispielformat-Bitmap (vorzeichenloser 32-Bit-Integer)
- Skalierungs-ID (vorzeichenloser 32-Bit-Integer)
(Wenn die Vektorgröße größer als 1 ist, enthält das Objekt mehrere Skalierer zur Formatänderung, und die Informationen in den vorherigen Aufzählungspunkten können wiederholt werden.)
- Vektorgröße (vorzeichenloser 32-Bit-Integer)
- Der Vektor der Rohdatenbreite
- Vektorgröße (vorzeichenloser 32-Bit-Integer)
- Elemente im Vektor (jeweils ein vorzeichenloser 32-Bit-Integer)
- Anzahl der Eigenschaften (vorzeichenloser 32-Bit-Integer)
- Eigenschaften. Für jede Eigenschaft werden die folgenden Informationen gespeichert:
- Name (String)
- Datentyp (tdsDataType)
- Wert (Zahlen werden binär gespeichert, Strings werden wie oben erläutert gespeichert).
Die folgende Tabelle enthält ein Beispiel für Metainformationen für eine Gruppe und einen Kanal. Die Gruppe enthält zwei Eigenschaften: einen String und einen Integer. Der Kanal enthält einen Rohdatenindex und keine Eigenschaften.
| Binärer Footprint (hexadezimal) | Beschreibung |
| 02 00 00 00 | Anzahl von Objekten |
| 08 00 00 00 | Länge des ersten Objektpfads |
| 2F 27 47 72 6F 75 70 27 | Objektpfad (/'Group') |
| FF FF FF FF | Rohdatenindex („FF FF FF FF“ bedeutet, dass dem Objekt keine Rohdaten zugewiesen sind) |
| 02 00 00 00 | Anzahl der Eigenschaften für /'Group' |
| 04 00 00 00 | Länge des ersten Eigenschaftsnamens |
| 70 72 6F 70 | Eigenschaftsname (prop) |
| 20 00 00 00 | Datentyp des Eigenschaftswerts (tdsTypeString) |
| 05 00 00 00 | Länge des Eigenschaftswerts (nur für Strings) |
| 76 61 6C 75 65 | Wert der Eigenschaft prop (value) |
| 03 00 00 00 | Länge des zweiten Eigenschaftsnamens |
| 6E 75 6D | Eigenschaftsname (num) |
| 03 00 00 00 | Datentyp des Eigenschaftswerts (tdsTypeI32) |
| 0A 00 00 00 | Wert der Eigenschaft num (10) |
| 13 00 00 00 | Länge des zweiten Objektpfads |
| 2F 27 47 72 6F 75 70 27 2F 27 43 68 61 6E 6E 65 6C 31 27 | Pfad des zweiten Objekts (/'Group'/'Channel1') |
| 14 00 00 00 | Länge der Indexinformationen |
| 03 00 00 00 | Datentyp der diesem Objekt zugewiesenen Rohdaten |
| 01 00 00 00 | Dimension des Rohdaten-Arrays (muss 1 sein) |
| 02 00 00 00 00 00 00 00 | Anzahl der Rohdatenwerte |
| 00 00 00 00 | Anzahl der Eigenschaften für /'Group'/'Channel1' (hat keine Eigenschaften) |
Die folgende Tabelle enthält ein Beispiel für den DAQmx-Rohdatenindex.
| Binärer Footprint (hexadezimal) | Beschreibung |
| 03 00 00 00 | Anzahl von Objekten |
| 23 00 00 00 | Länge des Gruppenobjektpfads |
| 2F 27 4D 65 61 73 75 72 65 64 20 54 68 72 6F 75 67 68 70 75 74 20 44 61 74 61 20 28 56 6F 6C 74 73 29 27 | Objektpfad (/'Measured Throughput Data (Volts)') |
| FF FF FF FF | Rohdatenindex („FF FF FF FF“ bedeutet, dass dem Objekt keine Rohdaten zugewiesen sind) |
| 00 00 00 00 | Anzahl der Eigenschaften für /'Measured Throughput Data (Volts)' |
| 34 00 00 00 | Länge des Kanalobjektpfads |
| 2F 27 4D 65 61 73 75 72 65 64 20 54 68 72 6F 75 67 68 70 75 74 20 44 61 74 61 20 28 56 6F 6C 74 73 29 27 2F 27 50 58 49 31 53 6C 6F 74 30 33 2d 61 69 30 27 69 12 00 00 | /'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0' |
| 69 12 00 00 | DAQmx-Rohdatenindex und enthält den Skalierer für die Formatänderung |
| FF FF FF FF | Datentyp, DAQmx-Rohdaten |
| 01 00 00 00 | Datendimension |
| 00 00 00 00 00 00 00 00 | Anzahl der Werte, keine Werte in diesem Segment |
| 01 00 00 00 | Größe des Vektors von Skalierern für die Formatänderung |
| 05 00 00 00 | DAQmx-Datentyp des ersten Skalierers für die Formatänderung |
| 00 00 00 00 | Rohpufferindex des ersten Skalierers für die Formatänderung |
| 00 00 00 00 | Rohbyte-Offset innerhalb des Schritts |
| 00 00 00 00 | Beispielformat-Bitmap |
| 00 00 00 00 | Skalierungs-ID |
| 01 00 00 00 | Größe des Vektors der Rohdatenbreite |
| 08 00 00 00 | Erstes Element im Vektor der Rohdatenbreite |
| 06 00 00 00 | Anzahl der Eigenschaften für /'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0' |
| 11 00 00 00 | Länge des ersten Eigenschaftsnamens |
| 4E 49 5F 53 63 61 6C 69 6E 67 5F 53 74 61 74 75 73 | Eigenschaftsname („NI_Scaling_Status“) |
| 20 00 00 00 | Datentyp des Eigenschaftswerts (tdsTypeString) |
| 08 00 00 00 | Länge des Eigenschaftswerts (nur für Strings) |
| 75 6E 73 63 61 6C 65 64 | Wert der Eigenschaft prop („unscaled“) |
| 13 00 00 00 | Länge des zweiten Eigenschaftsnamens |
| 4E 49 5F 4E 75 6D 62 65 72 5F 4F 66 5F 53 63 61 6C 65 73 | Eigenschaftsname („NI_Number_Of_Scales“) |
| 07 00 00 00 | Datentyp des Eigenschaftswerts (tdsTypeU32) |
| 02 00 00 00 | Wert der Eigenschaft (2) |
| 16 00 00 00 | Länge des dritten Eigenschaftsnamens |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 53 63 61 6C 65 5F 54 79 70 65 | Eigenschaftsname („NI_Scale[1]_Scale_Type“) |
| 20 00 00 00 | Datentyp der Eigenschaft (tdsTypeString) |
| 06 00 00 00 | Länge des Eigenschaftswerts |
| 4C 69 6E 65 61 72/span> | Eigenschaftswert („Linear“) |
| 18 00 00 00 | Länge des vierten Eigenschaftsnamens |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 53 6C 6F 70 65 | Eigenschaftsname („NI_Scale[1]_Linear_Slope“) |
| 0A 00 00 00 | Datentyp der Eigenschaft (tdsTypeDoubleFloat) |
| 04 E9 47 DD CB 17 1D 3E | Eigenschaftswert (1.693433E-9) |
| 1E 00 00 00 | Länge des fünften Eigenschaftsnamens |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 59 5F 49 6E 74 65 72 63 65 70 74 | Eigenschaftsname („NI_Scale[1]_Linear_Y_Intercept“) |
| 0A 00 00 00 | Datentyp der Eigenschaft (tdsTypeDoubleFloat) |
| 00 00 00 00 00 00 00 00 | Eigenschaftswert (0) |
| 1F 00 00 00 | Länge des sechsten Eigenschaftsnamens |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 59 6E 70 75 74 5F 53 6F 75 72 63 65 | Eigenschaftsname („NI_Scale[1]_Linear_Input_Source“) |
| 07 00 00 00 | Datentyp der Eigenschaft (tdsTypeU32) |
| 00 00 00 00 | Eigenschaftswert (0) |
Der Kanal "/'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0" aus der vorherigen Tabelle enthält zwei Skalierer. Ein Skalierer ändert das Format, wobei die Informationen des Skalierers für die Formatänderung im DAQmx-Rohdatenindex gespeichert sind. Der andere Skalierer ist ein linearer Skalierer, bei dem die Informationen als TDMS-Eigenschaften gespeichert werden. Der Skalierer zum Ändern des Formats ist identifizierbar, wenn die Steigung des linearen Skalierers 1.693433E-9 beträgt, der Achsenabschnitt 0 ist und die ID der Eingangsquelle 0 ist.
Metainformationen, die mit Metainformationen in den vorherigen Segmenten übereinstimmen, können in den folgenden Segmenten weggelassen werden. Das Auslassen redundanter Metainformationen ist optional, erhöht aber die Auslesegeschwindigkeit der Datei erheblich. Wenn Sie redundante Informationen schreiben, können Sie diese später mit der Funktion „TDMS: Defragmentieren“ in LabVIEW, LabWindows/CVI, MeasurementStudio usw. entfernen.
- Wenn Sie ein neues Objekt in das nächste Segment schreiben, bedeutet dies, dass das Segment alle Objekte aus dem vorherigen Segment sowie die hier beschriebenen neuen Objekte enthält. Wenn das neue Segment keine Kanäle aus dem vorherigen Segment enthält oder wenn sich die Reihenfolge der Kanäle im Segment ändert, muss das neue Segment eine neue Liste aller Objekte enthalten. Weitere Informationen dazu finden Sie im Abschnitt Optimierung dieses Artikels.
- Wenn Sie eine neue Eigenschaft in ein Objekt schreiben, das bereits im vorherigen Segment vorhanden ist, wird diese Eigenschaft dem Objekt hinzugefügt.
- Durch das Schreiben einer Eigenschaft, die bereits für ein Objekt vorhanden ist, wird der vorherige Wert dieser Eigenschaft überschrieben.
Hinweis: Wenn Sie in der TDMS-Dateiformatversion 2.0 einen Wert für die Namenseigenschaft eines vorhandenen Objekts angeben, wird dieses Objekt umbenannt.
Das folgende Beispiel zeigt den binären Footprint für den Metadatenabschnitt eines Segments, das direkt auf das oben beschriebene Segment folgt. Als einzige neue Metainformation wird der neue Eigenschaftswert in das Segment geschrieben.
| Binäres Layout (hexadezimal) | Beschreibung |
| 01 00 00 00 | Anzahl neuer/geänderter Objekte |
| 08 00 00 00 | Länge des Objektpfads |
| 2F 27 47 72 6F 75 70 27 | Objektpfad (/'Group') |
| FF FF FF FF | Rohdatenindex (dem Objekt sind keine Rohdaten zugewiesen) |
| 01 00 00 00 | Anzahl neuer/geänderter Eigenschaften |
| 03 00 00 00 | Länge des Eigenschaftsnamens |
| 6E 75 6D | Eigenschaftsname (num) |
| 03 00 00 00 | Datentyp des Eigenschaftswerts (tdsTypeI32) |
| 07 00 00 00 | Neuer Wert für Eigenschaft num (7) |
Rohdaten
Das Segment enthält schließlich noch die jedem Kanal zugeordneten Rohdaten. Die Daten-Arrays für alle Kanäle werden in der gleichen Reihenfolge verkettet, in der die Kanäle im Metainformationsteil des Segments angezeigt werden. Numerische Daten müssen gemäß dem Little-Endian-/Big-Endian-Flag in der Einleitung formatiert werden. Beachten Sie, dass Kanäle ihr Endian-Format oder ihren Datentyp nach dem ersten Schreibvorgang nicht mehr ändern können.
Kanäle vom Typ „String“ werden für einen schnellen Zufallszugriff vorverarbeitet. Alle Strings werden zu einem zusammenhängenden Arbeitsspeicherelement verkettet. Der Offset des ersten Zeichens jedes Strings in diesem zusammenhängenden Arbeitsspeicherelement wird in einem Array von vorzeichenlosen 32-Bit-Integers gespeichert. Dieses Array von Offset-Werten wird zuerst gespeichert, gefolgt von den verketteten String-Werten. Mit diesem Layout können Clientanwendungen von überall in der Datei auf einen beliebigen String-Wert zugreifen, indem der Lesezeiger maximal dreimal neu positioniert wird, ohne dass Daten gelesen werden, die vom Client nicht benötigt werden.
Wenn sich die Metainformationen zwischen Segmenten nicht ändern, können der Einleitungs- und der Metainformationsteil vollständig weggelassen werden. Stattdessen können einfach Rohdaten an das Ende der Datei angehängt werden. Jede folgende Rohdatenmenge hat das gleiche binäre Layout. Die Anzahl der Mengen kann aus den Einleitungs- und Metainformationen durch die folgenden Schritte berechnet werden:
- Berechnen Sie die Rohdatengröße eines Kanals. Jeder Kanal hat einen Datentyp, eine Array-Dimension und eine Anzahl von Werten in Metainformationen. Weitere Informationen dazu finden Sie im Abschnitt Metadaten dieses Artikels. Jeder Datentyp ist mit einer Typgröße verknüpft. Sie können die Rohdatengröße des Kanals wie folgt ermitteln: Typgröße von Datentyp × Array-Dimension × Anzahl der Werte. Wenn die Gesamtgröße in Byte gültig ist, hat die Rohdatengröße des Kanals diesen Wert.
- Berechnen Sie die Rohdatengröße einer Menge, indem Sie die Rohdatengröße aller Kanäle summieren.
- Berechnen Sie die Rohdatengröße der Gesamtmengen wie folgt: Nächster Segment-Offset - Rohdaten-Offset. Wenn der Wert für Nächster Segment-Offset -1 ist, entspricht die Rohdatengröße der gesamten Mengen der Dateigröße abzüglich der absoluten Anfangsposition der Rohdaten.
- Berechnen Sie die Anzahl der Mengen wie folgt: Rohdatengröße der Gesamtmengen ÷ Rohdatengröße einer Menge.
Rohdaten können in zwei Typen von Layouts eingeteilt werden: verschachtelt und nicht verschachtelt. Die ToC-Bitmaske in der Segmenteinleitung deklariert, ob Daten im Segment verschachtelt sind. Beispiel: Das Speichern von 32-Bit-Integer-Werten in Kanal 1 (1,2,3) und Kanal 2 (4,5,6) führt zu folgenden Layouts:
| Datenlayout | Binärer Footprint (hexadezimal) |
| Nicht verschachtelt | 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 05 00 00 00 06 00 00 00 |
| Verschachtelt | 01 00 00 00 04 00 00 00 02 00 00 00 05 00 00 00 03 00 00 00 06 00 00 00 |
Datentypwerte
Der folgende Enum-Typ beschreibt den Datentyp einer Eigenschaft oder eines Kanals in einer TDMS-Datei. Bei Eigenschaften wird der Datentypwert zwischen dem Namen und dem Binärwert gespeichert. Bei Kanälen ist der Datentyp Teil des Rohdatenindex.
typedef enum {
tdsTypeVoid,
tdsTypeI8,
tdsTypeI16,
tdsTypeI32,
tdsTypeI64,
tdsTypeU8,
tdsTypeU16,
tdsTypeU32,
tdsTypeU64,
tdsTypeSingleFloat,
tdsTypeDoubleFloat,
tdsTypeExtendedFloat,
tdsTypeSingleFloatWithUnit=0x19,
tdsTypeDoubleFloatWithUnit,
tdsTypeExtendedFloatWithUnit,
tdsTypeString=0x20,
tdsTypeBoolean=0x21,
tdsTypeTimeStamp=0x44,
tdsTypeFixedPoint=0x4F,
tdsTypeComplexSingleFloat=0x08000c,
tdsTypeComplexDoubleFloat=0x10000d,
tdsTypeDAQmxRawData=0xFFFFFFFF
} tdsDataType;
Hinweise:
- Weitere Informationen zur Verwendung von tdsTypeTimeStamp in LabVIEW finden Sie im Artikel LabVIEW Timestamp (LabVIEW-Zeitstempel).
- LabVIEW-Gleitkommatypen mit Einheit werden in einen Gleitkommakanal mit einer Eigenschaft namens unit_string übersetzt, die die Einheit als String enthält.
Weitere Informationen zu den TDMS-Schreibfunktionen finden Sie im Artikel VI-based API for Writing TDMS Files (VI-basierte API zum Schreiben von TDMS-Dateien).
Vordefinierte Eigenschaften
LabVIEW-Signalverläufe werden in TDMS-Dateien als numerische Kanäle dargestellt. Dabei werden die Signalverlaufsattribute dem Kanal als Eigenschaften hinzugefügt.
- wf_start_time: Diese Eigenschaft gibt die Zeit der Erfassung oder Erzeugung des Signalverlaufs an. Wenn die Zeitangaben relativ sind oder wenn es sich nicht um einen Zeitbereichssignalverlauf, sondern um einen Frequenzbereich handelt, kann diese Eigenschaft auch 0 lauten.
- wf_start_offset: Diese Eigenschaft wird für den LabVIEW-Datentyp „Express Dynamisch“ verwendet. Frequenzbereichsdaten und Histogrammergebnisse verwenden diesen Wert als ersten Wert auf der x-Achse.
- wf_increment: Diese Eigenschaft gibt das Inkrement zwischen zwei aufeinander folgenden Samples auf der x-Achse an.
- wf_samples: Diese Eigenschaft gibt die Sample-Anzahl im Signalverlauf an.
Optimierung
Durch Anwenden der Formatdefinition wie in den vorherigen Abschnitten beschrieben werden gültige TDMS-Dateien erstellt. TDMS ermöglicht jedoch eine Vielzahl von Optimierungen, die üblicherweise von Software von NI wie LabVIEW, LabWindows/CVI, MeasurementStudio usw. verwendet werden. Anwendungen, die versuchen, von NI-Software geschriebene Daten zu lesen, müssen die in diesem Absatz beschriebenen Optimierungsmechanismen unterstützen.
Beispiel für inkrementelle Metainformationen
Metainformationen wie Objektpfade, Eigenschaften und Rohindizes werden einem Segment nur hinzugefügt, wenn sie sich ändern. Im folgenden Beispiel werden inkrementelle Metainformationen erläutert.
In der ersten Schreibiteration werden Kanal 1 und Kanal 2 geschrieben. Jeder Kanal weist drei 32-Bit-Integer-Werte (1,2,3 und 4,5,6) sowie mehrere beschreibende Eigenschaften auf. Der Metainformationsteil des ersten Segments enthält Pfade, Eigenschaften und Rohdatenindizes für Kanal 1 und Kanal 2. Die Flags kTocMetaData, kTocNewObjList und kTocRawData des ToC-Bitfeldes werden gesetzt. Mit der ersten Schreibiteration wird ein Datensegment erstellt. In der folgenden Tabelle ist der binäre Footprint des ersten Segments beschrieben.
| Teil | Binärer Footprint (hexadezimal) |
| Einleitung | 54 44 53 6D 0E 00 00 00 69 12 00 00 8F 00 00 00 00 00 00 00 77 00 00 00 00 00 00 00 |
| Anzahl von Objekten | 02 00 00 00 |
| Metainformationsobjekt 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 76 61 6C 69 64 |
| Metainformationsobjekt 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 |
| Rohdatenkanal 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Rohdatenkanal 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
In der zweiten Schreibiteration hat sich keine der Eigenschaften geändert. Kanal 1 und Kanal 2 weisen immer noch jeweils drei Werte auf, und es werden keine zusätzlichen Kanäle geschrieben. Daher schreibt diese Iteration keine Metadaten. Die Metadaten aus dem vorherigen Segment gelten weiterhin als gültig. Mit dieser Iteration wird kein neues Segment erstellt. Stattdessen hängt diese Iteration nur die Rohdaten an das vorhandene Segment an und aktualisiert dann den Nächsten Segment-Offset im Einleitungsabschnitt. In der folgenden Tabelle ist der binäre Footprint des aktualisierten Segments beschrieben.
| Teil | Binärer Footprint (hexadezimal) |
| Einleitung | 54 44 53 6D 0E 00 00 00 69 12 00 00 A7 00 00 00 00 00 00 00 77 00 00 00 00 00 00 00 |
| Anzahl von Objekten | 02 00 00 00 |
| Metainformationsobjekt 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 76 61 6C 69 64 |
| Metainformationsobjekt 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 |
| Rohdatenkanal 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Rohdatenkanal 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
| Rohdatenkanal 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Rohdatenkanal 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
In der vorherigen Tabelle enthalten die letzten beiden Zeilen Daten, die während der zweiten Schreibiteration an das erste Segment angehängt werden.
Die dritte Schreibiteration fügt jedem Kanal drei weitere Werte hinzu. Im Kanal 1 wurde die Eigenschaft status im ersten Segment auf valid gesetzt. Sie muss jetzt aber auf error eingestellt werden. Diese Iteration erstellt ein neues Segment. Der Metadatenabschnitt dieses Segments enthält jetzt den Objektpfad für Kanal, Name, Typ und Wert für diese Eigenschaft. Bei zukünftigen Dateilesevorgängen überschreibt der Wert für error den zuvor geschriebenen Wert für valid. Der vorherige gültige Wert verbleibt aber in der Datei, sofern er nicht defragmentiert wird. In der folgenden Tabelle ist der binäre Footprint des zweiten Segments beschrieben.
| Teil | Binärer Footprint (hexadezimal) |
| Einleitung | 54 44 53 6D 0A 00 00 00 69 12 00 00 50 00 00 00 00 00 00 00 38 00 00 00 00 00 00 00 |
| Anzahl von Objekten | 01 00 00 00 |
| Metainformationsobjekt 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 65 72 72 6F 72 |
| Rohdatenkanal 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Rohdatenkanal 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
Die vierte Schreibiteration fügt einen zusätzlichen Kanal hinzu (voltage), der fünf Werte enthält (7,8,9,10,11). Diese Iteration erstellt ein neues Segment (das dritte Segment) in der TDMS-Datei. Da alle anderen Metadaten aus dem vorherigen Segment noch gültig sind, enthält der Metadatenabschnitt des vierten Segments nur den Objektpfad, die Eigenschaften und die Indexinformationen für den Kanal „voltage“. Der Rohdatenabschnitt enthält drei Werte für Kanal 1, drei Werte für Kanal 2 und fünf Werte für den Kanal „voltage“. In der folgenden Tabelle ist der binäre Footprint des dritten Segments beschrieben.
| Teil | Binärer Footprint (hexadezimal) |
| Einleitung | 54 44 53 6D 0A 00 00 00 69 12 00 00 5E 00 00 00 00 00 00 00 32 00 00 00 00 00 00 00 |
| Anzahl von Objekten | 01 00 00 00 |
| Metainformationsobjekt 3 | 12 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 76 6F 6C 74 61 67 65 27 14 00 00 00 03 00 00 00 01 00 00 00 05 00 00 00 00 00 00 00 00 00 00 00 |
| Rohdatenkanal 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Rohdatenkanal 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
| Rohdatenkanal 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
Im vierten Segment hat Kanal 2 jetzt 27 Werte. Alle anderen Kanäle bleiben unverändert. Der Metadatenabschnitt enthält jetzt den Objektpfad für Kanal 2, den neuen Rohdatenindex für Kanal 2 und keine Eigenschaften für Kanal 2. In der folgenden Tabelle ist der binäre Footprint des vierten Segments beschrieben.
| Teil | Binärer Footprint (hexadezimal) |
| Einleitung | 54 44 53 6D 0A 00 00 00 69 12 00 00 BF 00 00 00 00 00 00 00 33 00 00 00 00 00 00 00 |
| Anzahl von Objekten | 01 00 00 00 |
| Metainformationsobjekt 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 1B 00 00 00 00 00 00 00 00 00 00 00 |
| Rohdatenkanal 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Rohdatenkanal 2 | 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 0C 00 00 00 0D 00 00 00 0E 00 00 00 0F 00 00 00 10 00 00 00 11 00 00 00 12 00 00 00 13 00 00 00 14 00 00 00 15 00 00 00 16 00 00 00 17 00 00 00 18 00 00 00 19 00 00 00 1A 00 00 00 1B 00 00 00 |
| Rohdatenkanal 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
Im fünften Segment beendet die Anwendung den Schreibvorgang in Kanal 2. Die Anwendung schreibt nur weiter in Kanal 1 und im Kanal voltage. Das stellt eine Änderung der Kanalreihenfolge dar. Daher müssen Sie eine neue Liste mit Kanalpfaden schreiben. Sie müssen das ToC-Bit kTocNewObjList setzen. Der Metadatenabschnitt des neuen Segments muss eine vollständige Liste aller Objektpfade enthalten, jedoch keine Eigenschaften und keine Rohdatenindizes, sofern diese sich nicht ebenfalls ändern. In der folgenden Tabelle ist der binäre Footprint des fünften Segments beschrieben.
| Teil | Binärer Footprint (hexadezimal) |
| Einleitung | 54 44 53 6D 0E 00 00 00 69 12 00 00 61 00 00 00 00 00 00 00 41 00 00 00 00 00 00 00 |
| Anzahl von Objekten | 02 00 00 00 |
| Metainformationsobjekt 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 00 00 00 00 00 00 00 00 |
| Metainformationsobjekt 2 | 12 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 76 6F 6C 74 61 67 65 27 00 00 00 00 00 00 00 00 |
| Rohdatenkanal 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Rohdatenkanal 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
Indexdateien
Alle in eine TDMS-Datei geschriebenen Daten werden in einer Datei mit der Erweiterung *.tdms gespeichert. TDMS-Dateien können von einer optionalen *.tdms_index-Indexdatei begleitet werden. Mit der Indexdatei wird der Lesevorgang in der *.tdms-Datei beschleunigt. Wenn eine NI-Anwendung eine TDMS-Datei ohne Indexdatei öffnet, erstellt die Anwendung die Indexdatei automatisch. Wenn eine NI-Anwendung wie LabVIEW oder LabWindows/CVI eine TDMS-Datei schreibt, erstellt die Anwendung die Indexdatei und die Hauptdatei gleichzeitig.
Die Indexdatei ist eine exakte Kopie der *.tdms-Datei, außer dass sie keine Rohdaten enthält und jedes Segment mit einem TDSh-Tag anstelle eines TDSm-Tags beginnt. Die Indexdatei enthält alle Informationen, um einen beliebigen Wert eines Kanals in der *.tdms-Datei genau zu lokalisieren.
Fazit
Zusammenfassend lässt sich sagen, dass das TDMS-Dateiformat für besonders schnelle Schreib- und Lesevorgänge bei Messwerten unter Beibehaltung eines hierarchischen Systems beschreibender Informationen konzipiert ist. Während das binäre Layout an sich recht einfach ist, können die durch das inkrementelle Schreiben von Metadaten möglichen Optimierungen für sehr ausgefeilte Dateikonfigurationen sorgen.
Zusätzliche Ressourcen
Für die Verwendung der Marke LabWindows wurde eine Lizenz bei der Microsoft Corporation eingeholt. Windows ist ein in den USA und anderen Ländern eingetragenes Warenzeichen der Microsoft Corporation.