Empfohlene Methoden für die TestStand-Codemodulentwicklung
Überblick
Beim Erstellen eines Testprogramms mit TestStand wird die Kerntestfunktionalität in separaten Codemodulen implementiert. Die Adapter von TestStand rufen Codemodule auf, die mit verschiedenen Programmierumgebungen und -sprachen wie LabVIEW, LabWindows™/CVI™, C#, VB .NET, C/C ++ und ActiveX entwickelt werden.
In diesem Dokument werden empfohlene Methoden erläutert, die bei der Entwicklung Ihrer Testsystem-Codemodule und beim Aufrufen aus der Testsequenz zu berücksichtigen sind. Bei diesem Dokument wird davon ausgegangen, dass Sie über grundlegende Kenntnisse von TestStand verfügen und wissen, wie Sie eine einfache Testsequenz erstellen. Wenn Sie mit diesen Konzepten nicht vertraut sind, lesen Sie die folgenden Ressourcen für die ersten Schritte, bevor Sie dieses Dokument verwenden:
Weitere Informationen zum Implementieren von Codemodulen finden Sie in den TestStand-Hilfethemen Built-In Step Types (Integrierte Schritttypen) und Module Adapters (Moduladapter).
Inhalt
- Aufstellen einer Strategie für die Entwicklung von Codemodulen
- Entscheiden, an welchem Ort Funktionalität implementiert wird
- Empfohlene Methoden für die Implementierung von Codemodulen
- Verwenden der Instrumentierung in Codemodulen
- Weitere Abschnitte zur TestStand Advanced Architecture-Serie anzeigen
Aufstellen einer Strategie für die Entwicklung von Codemodulen
Bevor Sie mit der Entwicklung eines Testsystems beginnen, sollten Sie einen allgemeinen Ansatz für die folgenden Aspekte des Testsystems definieren:
- Granularität von Codemodulen: Definieren Sie den Funktionsumfang jedes Moduls.
- Definieren einer Verzeichnisstruktur für Testcode: Eine gut definierte Verzeichnisstruktur erleichtert das Freigeben von Code für andere Entwickler und das Bereitstellen von Code auf Testsystemen.
Granularität von Codemodulen
Beim Entwurf eines Testsystems müssen Sie eine konsistente Granularitätsebene für Codemodule definieren. Die Granularität bezieht sich auf den Funktionsumfang jedes Codemoduls in einem Testsystem. Eine Testsequenz mit geringer Granularität ruft nur wenige Codemodule auf, die jeweils mehr Funktionen ausführen. Eine Sequenz mit hoher Granularität ruft dagegen viele Codemodule mit jeweils kleinerem Umfang auf.
| Geringe Granularität | Hohe Granularität |
|
|
Sie sollten ein Gleichgewicht zwischen diesen Extremen anstreben, da jeder Ansatz seine eigenen Vorteile hat.
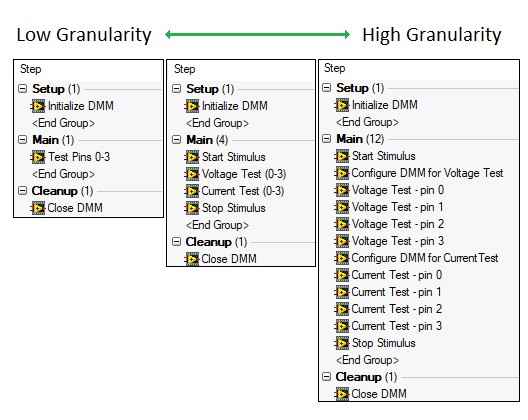
Implementierung eines einfachen Tests mit unterschiedlichen Granularitätsstufen
Erstellen Sie eine Reihe von Standards für die Entwicklung von Codemodulen, um eine einheitliche Granularität in Ihrem Testsystem zu gewährleisten, z. B.:
- Führen Sie die Hardwareinitialisierung und das Herunterfahren in separaten Codemodulen durch, damit TestStand die Lebensdauer von Hardware-Sessions verwalten kann.
- Bestimmen Sie die Granularität basierend auf den Testanforderungen, indem Sie für jedes Anforderungselement einen einzelnen Testschritt erstellen. Durch diesen Ansatz können Sie besser sicherstellen, dass alle Anforderungen abgedeckt sind. Darüber hinaus können Sie NI Requirements Gateway mit TestStand verwenden, um Verknüpfungen zwischen Ihren Testschritten und Anforderungsdokumenten herzustellen. Weitere Informationen finden Sie im Tutorial Coupling NI Requirements Gateway with TestStand (NI Requirements Gateway mit TestStand koppeln).
- Bestimmen Sie den Umfang der einzelnen Schritte anhand der gewünschten Struktur der Testergebnisse. Da für jeden Schritt ein Ergebniseintrag erstellt wird, erleichtert das Erstellen einer Eins-zu-Eins-Zuordnung von Testschritten zu erforderlichen Ergebniseinträgen das Organisieren von Testergebnissen mit minimalen Änderungen an Reporting oder Datenbankprotokollierung.
Definieren einer Verzeichnisstruktur für Sequenzdateien und Codemodule
Wenn Sie den Pfad eines Codemoduls in einem Testschritt angeben, können Sie einen absoluten oder relativen Pfad verwenden. Es wird aus folgenden Gründen empfohlen, absolute Pfade zu vermeiden:
- Wenn Sie die Sequenzdatei und ihre Abhängigkeiten auf dem Datenträger verschieben, ist der Pfad nicht mehr gültig.
- Wenn Sie die Sequenzdatei auf einem Zielcomputer bereitstellen, sind Pfade ungültig, wenn die Dateien nicht an demselben Speicherort installiert sind.
Wenn Sie einen relativen Pfad angeben, verwendet TestStand eine Liste von Suchverzeichnissen, um den Pfad aufzulösen. Diese Suchverzeichnisse enthalten in der Regel das aktuelle Sequenzdateiverzeichnis, TestStand-spezifische Verzeichnisse und Systemverzeichnisse.
Definieren Sie unbedingt vor Beginn der Entwicklung eine Dateistruktur für Ihre Testsequenzen und Codemodule. Verwenden Sie die folgenden Richtlinien beim Definieren einer Strategie zum Speichern von Sequenzdateien und Codemodulen.
- Speichern Sie für Codemodule, die in einer einzelnen Sequenzdatei verwendet werden, die Codemoduldateien in einem Unterverzeichnis relativ zur Sequenzdatei. Dadurch wird sichergestellt, dass die Sequenzdatei die Codemodule immer finden kann, wenn sie auf dem System verschoben oder auf ein anderes System kopiert werden.
- Bei Codemodulen, die von mehreren zugehörigen Sequenzdateien gemeinsam genutzt werden, können Sie denselben Ansatz wie bei einer einzelnen Sequenzdatei verwenden, wenn Sie die zugehörigen Sequenzdateien in demselben Verzeichnis speichern. Erstellen Sie einen Arbeitsbereich, der alle zugehörigen Sequenzdateien und Codemodule enthält.
- Bei Codemodulen, die von mehreren nicht verwandten Sequenzdateien gemeinsam genutzt werden, sollten Sie ein spezielles Verzeichnis erstellen, das alle gemeinsam genutzten Codemodule enthält, und ein neues Suchverzeichnis erstellen, das auf diesen Speicherort verweist. Dadurch wird sichergestellt, dass alle Sequenzdateien auf dem System die Dateien mithilfe eines relativen Pfads zu diesem Suchverzeichnis finden können. Bei der Bereitstellung des Codemoduls können Sie die Konfigurationsdatei für Suchverzeichnisse bereitstellen. Diese befindet sich unter <TestStand-Anwendungsdaten>\Cfg\SearchDirectories.cfg. Wenn Sie diesen Ansatz verwenden, verschieben Sie keine Codemoduldateien innerhalb des Verzeichnisses. Ansonsten könnten die in aufrufenden Sequenzdateien angegebenen Pfade unterbrochen werden.
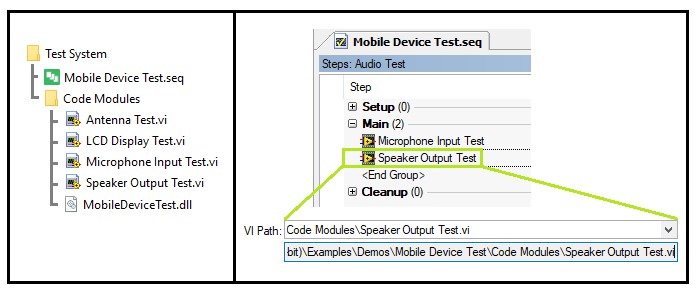
Definieren einer Verzeichnisstruktur, in der sich Codemodule in einem Unterverzeichnis der Sequenzdatei befinden
Wenn Sie Testcode mit dem TestStand Deployment Utility bereitstellen, können Sie bestimmte Ziele für Sequenzdateien und für abhängige Codemodule auswählen. Wenn zwischen den Zielverzeichnissen für die Sequenzdatei und dem Codemodul ein relativer Pfad vorhanden ist, aktualisiert das TestStand Deployment Utility den Pfad in der Sequenzdatei so, dass er auf den aktualisierten Speicherort verweist. In den meisten Fällen sollten Sie die Verzeichnisstruktur Ihrer Bereitstellung an die auf dem Entwicklungssystem anpassen, um sicherzustellen, dass die Bereitstellung dem Code auf Ihrem Entwicklungscomputer so ähnlich wie möglich ist.
Entscheiden, an welchem Ort Funktionalität implementiert wird
Beim Definieren des Umfangs der Codemodule für Ihr Testsystem müssen Sie eine Strategie aufstellen, die bestimmt, welche Funktionalität in den Codemodulen im Vergleich zur Sequenzdatei implementiert wird. In den folgenden Abschnitten können Sie den am besten geeigneten Ort für die Implementierung allgemeiner Funktionen ermitteln:
- Auswerten von Messergebnissen bezüglich festgelegter Grenzwerte
- Definieren von Stimuluswerten
- Melden und Protokollieren von Testergebnissen und Fehlern
- Schleifenoperationen
- Durchführen von Schaltvorgängen
- Durchführen von Berechnungen und Bearbeiten von Daten
Auswerten von Grenzwerten und Testergebnissen
Idealerweise sollte das Codemodul Funktionen enthalten, die in direktem Zusammenhang mit dem Erhalten von Testmessungen stehen. Dabei sollte die Testsequenz sollte das rohe Testergebnis verarbeiten. Dieser Ansatz hat die folgenden Vorteile:
- Testlimits sind in der Sequenzdatei einfacher zu verwalten, da Sie Tools wie den Property Loader verwenden können, um Limits für mehrere Schritte an einem einzigen zentralen Ort zu verwalten.
- In der Sequenz definierte Testgrenzwerte werden automatisch in die Testergebnisse aufgenommen, z. B. in das Protokoll oder die Datenbank.
- Testgrenzwerte können aktualisiert werden, ohne Änderungen an den Codemodulen vorzunehmen. Sie erfordern zudem weniger Validierung, da nur die Testsequenz geändert wird.
Für einfachere Messungen kann das Codemodul den Rohmesswert zur Verarbeitung an die Sequenz zurückgeben. Wenn in einem Testschritt beispielsweise die Spannung an einem bestimmten Kontakt des Prüflings gemessen wird, sollte das Codemodul den Messwert zurückgeben, anstatt die Prüfung direkt im Codemodul durchzuführen. Sie können diesen Wert verarbeiten, um das Testergebnis in der Sequenzdatei mithilfe eines Numeric-Limit-Testschritts zu ermitteln.
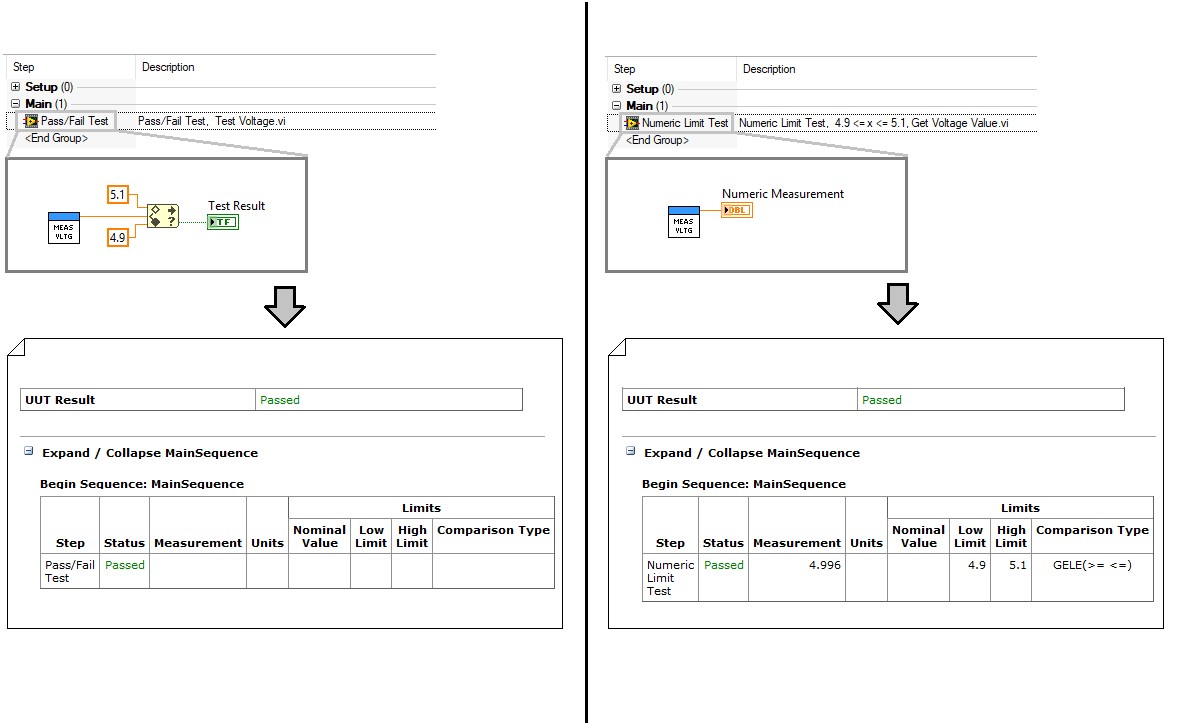
Das Auswerten von Grenzwerten im Testschritt vereinfacht Codemodule und verbessert die Ergebnisprotokollierung
Aufgrund der Komplexität einiger Tests ist es jedoch nicht immer möglich, rohe Testergebnisse in der Sequenzdatei zu verarbeiten. Bei komplexeren Messungen ist wahrscheinlich eine zusätzliche Verarbeitung der Ergebnisdaten erforderlich. Komplexe Daten können zu einer einzelnen Zeichenfolge oder einem numerischen Ergebnis verarbeitet werden. Dieses kann dann in TestStand mithilfe eines String- oder Zahlenvergleichs ausgewertet werden kann. Beispielsweise sind die Ergebnisse eines Frequenz-Sweep-Tests komplex. Sie können nicht direkt ausgewertet werden, aber die Daten können zu einer einzelnen Zahl verarbeitet werden, die den Mindestwert darstellt. In diesem Fall sollte das Codemodul das verarbeitete Ergebnis auswerten und die Frequenzdaten in einem separaten Parameter für die Protokollierung zurückgeben, wie im folgenden Testbeispiel für mobile Geräte dargestellt:
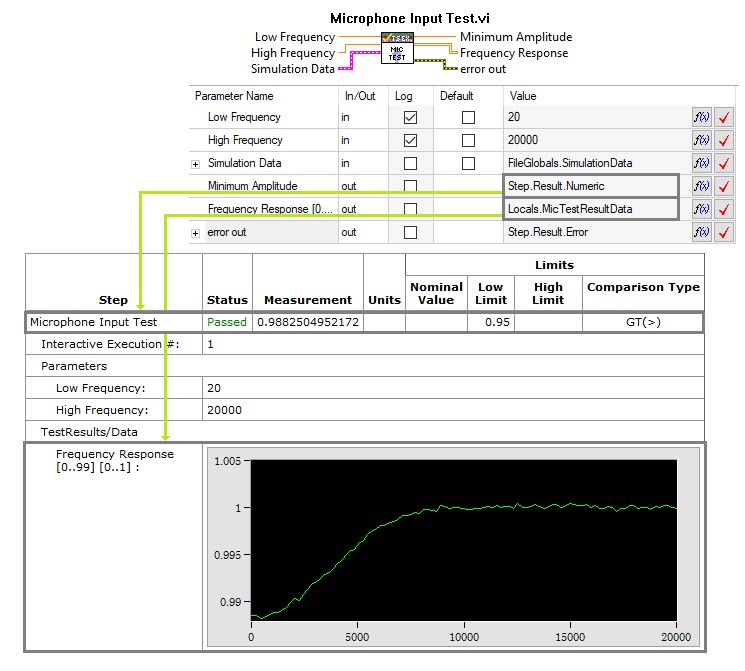
Verarbeiten Sie komplexere Daten im Codemodul, um ein numerisches oder Zeichenfolgenergebnis zu generieren, und verwenden Sie einen Parameter, um die Rohdaten für die Protokollierung auszugeben
Wenn die Rohdaten sehr groß sind, kann die Übergabe der Daten an TestStand erhebliche Auswirkungen auf die Leistung haben. In diesem Fall sollten Sie Daten direkt in einer TDMS-Datei protokollieren und das Testprotokoll mit der Datei verknüpfen. So können Sie aus dem Protokoll auf die Daten verweisen, ohne sie an TestStand übergeben zu müssen. Weitere Informationen zu diesem Ansatz finden Sie unter Including Hyperlinks in a Report - TDMS File (Einschließen von Hyperlinks in eine Protokoll-TDMS-Datei).
Wenn der Schritt das Testergebnis nicht anhand der in den Testschritten verfügbaren Auswertungstypen ermitteln kann, sollten Sie einen neuen Schritttyp mit zusätzlichen Funktionen erstellen, um den erforderlichen Testtyp zu verarbeiten. Weitere Informationen zum Erstellen benutzerdefinierter Schritttypen finden Sie im Artikel Best Practices for Custom Step Type Development (Bewährte Methoden für die Entwicklung benutzerdefinierter Schritttypen) in dieser Reihe.
Definieren von Teststimuli
Bei vielen Tests muss sich der Prüfling oder die Testumgebung in einem bestimmten Zustand befinden, bevor der Test durchgeführt werden kann. Beispielsweise kann eine Erregerspannung erforderlich sein, um eine Temperaturmessung durchzuführen, oder eine beheizte Kammer muss auf eine bestimmte Temperatur eingestellt werden. Verwenden Sie für diese Modultypen Parameter, um Eingangswerte wie die Erregerspannung oder die gewünschte Temperatur zu übergeben. Das bietet viele der Vorteile, die Sie mit der Rückgabe von Rohdaten in Testcodemodulen erhalten, im Vergleich zu Verarbeitungsbeschränkungen direkt im Code, wie im vorherigen Abschnitt erläutert.
Protokollieren von Testergebnissen
TestStand bietet integrierte Funktionen für die Protokollerstellung und Datenbankprotokollierung unter Verwendung der Ergebnisse aus Testschritten. Implementieren Sie aus diesem Grund keine Datenprotokollierung direkt in Codemodulen. Stellen Sie stattdessen sicher, dass alle Daten, die Sie protokollieren möchten, als Parameter ausgegeben werden, und verwenden Sie TestStand, um die Daten zu protokollieren. Einige Daten wie Testergebnisse, Grenzwerte und Fehlerinformationen werden automatisch protokolliert. Um andere Daten zu protokollieren, können Sie mit der Funktion für zusätzliche Ergebnisse weitere Parameter angeben, die in den Bericht aufgenommen werden sollen.
Weitere Informationen zum Hinzufügen von Ergebnissen zum Testprotokoll finden Sie im Beispiel Adding Custom Data to a Report (Hinzufügen benutzerdefinierter Daten zu einem Bericht), das in TestStand enthalten ist.
Wenn spezielle Anforderungen für die Protokollierung gelten, können Sie ein Plug-in für die Ergebnisverarbeitung ändern oder erstellen. So können Sie Ergebnisse mit der integrierten TestStand-Ergebnissammlung erfassen, während Sie bestimmen können, wie die Ergebnisse verarbeitet und dargestellt werden. Weitere Informationen finden Sie im Abschnitt „Creating Plug-ins“ (Erstellen von Plug-ins) im Dokument Best Practices for TestStand Process Model Development and Customization (Bewährte Methoden für die Entwicklung und Anpassung von TestStand-Prozessmodellen).
Schleifenoperationen
Es kann schwierig sein, den besten Ansatz für die Implementierung von Schleifen zu bestimmen, da jeder Ansatz seine eigenen Vor- und Nachteile hat. Verwenden Sie die folgenden Richtlinien, um die beste Strategie für Ihre Anwendung zu bestimmen:
Interne Schleife im Codemodul
- Verbesserte Leistung, insbesondere bei schnellen Schleifen. Da jeder Codemodulaufruf einige Millisekunden Overhead verursachen kann, können Schleifen von Hunderten oder Tausenden von Iterationen mit einer externen Schleife die Testgeschwindigkeit beeinträchtigen.
- Ermöglicht ein komplexeres Schleifenverhalten.
Externe Schleifen in der Sequenzdatei
- Anzeigen und Ändern von Schleifeneinstellungen direkt in der Sequenzdatei ohne Änderungen am Codemodul.
- Einfacher Zugriff auf den Schleifenindex in der Sequenzdatei. Das ist nützlich, um Switch-Routen oder anderes Verhalten zu bestimmen, das sich basierend auf der aktuellen Iteration ändert.
- Jede Iteration der Schleife wird separat protokolliert und zeigt die Ergebnisse für jede Iteration im Protokoll oder in der Datenbank an.
Durchführen von Schaltvorgängen
Viele Testsysteme verwenden das Schalten, damit ein einzelnes Hardwareelement mehrere Standorte testen kann. Mit Switches können Sie programmatisch steuern, welche Kontakte eines Prüflings über vordefinierte Routen mit bestimmter Hardware verbunden sind.
Sie können das Schalten in TestStand-Codemodulen auf folgende Arten implementieren:
- Mithilfe der integrierten Schalteigenschaften eines Schritts (erfordert NI Switch Executive)
- Mithilfe der TestStand IVI Switch-Schritte (nur 32-Bit-TestStand)
- Durch direktes Aufrufen von Switch-Treiberfunktionen in Codemodulen
Wenn Sie NI Switch-Hardware verwenden, können Sie mit NI Switch Executive schnell Routen definieren. Wenn Sie Zugriff auf NI Switch Executive haben, ist die Verwendung der integrierten Schritteinstellungen für das Schalten normalerweise der beste Ansatz mit den folgenden Vorteilen:
- Durch das Definieren von Switch-Konfigurationen im Schritt werden die Schaltfunktionen vom Testcode entkoppelt. Das kann die Wiederverwendbarkeit erhöhen und die Komplexität Ihrer Codemodule verringern.
- Viele der Felder in den Schalteinstellungen werden durch einen Ausdruck angegeben. Dabei können Sie die RunState.LoopIndex-Eigenschaft oder eine andere Variable verwenden, um die Routen- oder Routengruppennamen für Schritte zu indizieren, über die Sie iterieren.
- Für parallele Tests können Sie den Test-Socket-Index (RunState.TestSockets.MyIndex) als Teil der Routing-Zeichenfolge verwenden, um unterschiedliche Switch-Routen für jeden Test-Socket zu verwenden.
- Sie können die Verbindungslebensdauer mit dem Schritt, der Sequenz, dem Thread oder der Ausführung verknüpfen.
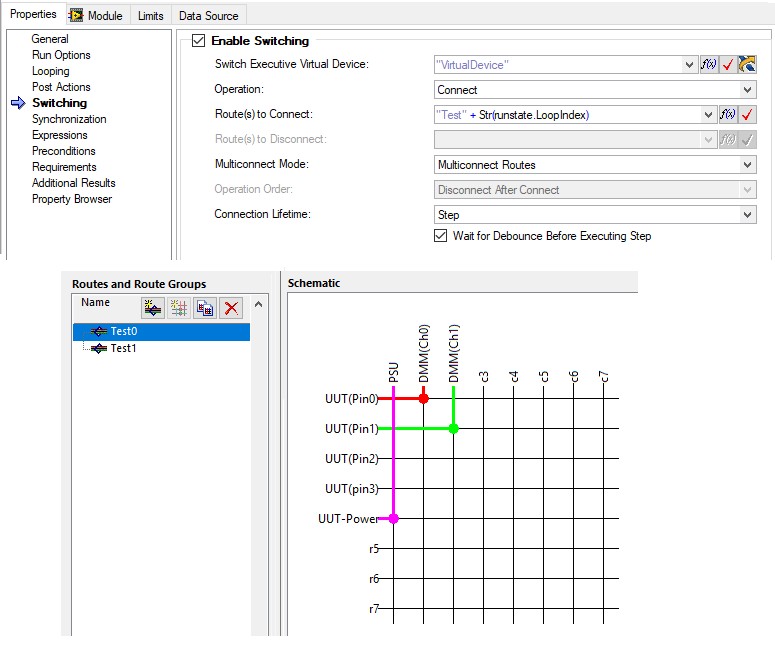
Verwenden Sie NI Switch Executive, um Routen direkt aus den TestStand-Schritteinstellungen anzugeben. Damit können Sie auch TestStand-Ausdrücke verwenden, um die Route mithilfe des aktuellen Schleifenindex oder anderer Eigenschaften dynamisch zu bestimmen
Durchführen von Berechnungen und Bearbeiten von Daten
Um das Verwalten von Codemodulen für einfachere Aufgaben zu vermeiden, können Sie mit der Ausdruckssprache in TestStand einfache Berechnungen und eindimensionale Array-Manipulationen durchzuführen. Höhere Programmieranforderungen sollten in Codemodulen implementiert werden, da Programmiersprachen eine robustere Funktionalität bieten, die für diese Aufgaben besser geeignet ist. Das Verketten mehrdimensionaler Arrays ist beispielsweise mit der nativen LabVIEW-Funktion „Array erstellen“ viel einfacher als mit der Ausdruckssprache.
In einigen Fällen können Sie die mit dem .NET-Framework bereitgestellten nativen Klassen verwenden, um die Erstellung von allzu komplexen Ausdrücken zu vermeiden. Sie können beispielsweise die System.IO.Path-Klasse verwenden, um schnell eine Pfadmanipulation durchzuführen, ohne ein Codemodul zu erstellen.
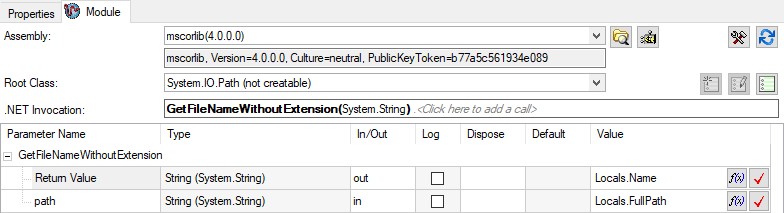
Sie können einen .NET-Schritt verwenden, um .NET-Framework-Methoden zu verwenden, ohne dass ein Codemodul erforderlich ist
Empfohlene Methoden für die Implementierung von Codemodulen
Bei der Implementierung von Codemodulen müssen Sie viele Entwurfsentscheidungen treffen, die sich auf viele der von Ihnen erstellten Codemodule auswirken. Dieser Abschnitt enthält Richtlinien für die folgenden Konzepte:
- Übertragen von Daten von TestStand an Codemodule
- Verarbeitung der Sequenzbeendigung innerhalb von Codemodulen
- Melden von Codemodulfehlern an TestStand
- Verwalten der Ausführungsgeschwindigkeit und Speicherauslastung von Codemodulen
Übertragen von Daten von TestStand an Codemodule
Sie können innerhalb eines Codemoduls über zwei Ansätze auf TestStand-Daten zugreifen:
- Übergeben der Daten über Codemodulparameter
- Zugriff auf die Daten direkt aus dem Codemodul mit der TestStand-API
In den meisten Fällen bietet es sich aus folgenden Gründen an, Parameter anstelle der TestStand-API zum Übergeben von Daten zu verwenden, um direkt darauf zuzugreifen:
- Weniger fehleranfällig – Fehler in den Eigenschaftsnamen oder Datentypen sind leicht zu finden, da die Parameterwerte in den Schritttypeinstellungen in TestStand und nicht direkt im Codemodul definiert werden.
- Besser verwaltbar – Änderungen an Schritteigenschaften werden ohne Änderungen am Codemodul in der Parameterkonfiguration in TestStand angegeben.
- Einfachere Wiederverwendung außerhalb von TestStand – Da das Codemodul nicht von der TestStand-API abhängig ist, kann das Modul ohne Änderung außerhalb von TestStand verwendet werden.
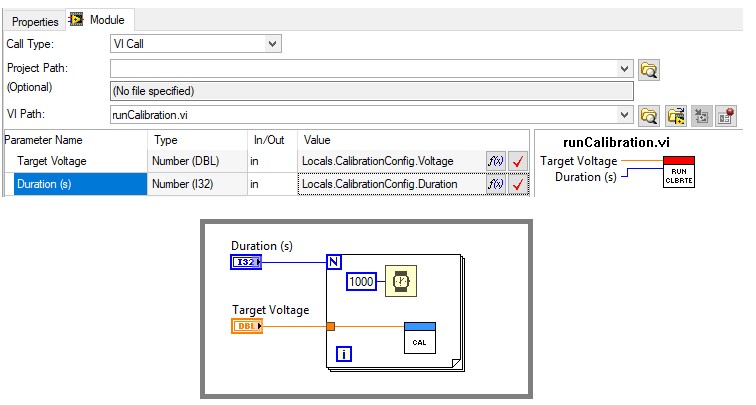
Verwenden Sie nach Möglichkeit Parameter, um die erforderlichen Daten an Codemodule zu übergeben
Die Verwendung der API für den direkten Zugriff auf Eigenschaften kann jedoch in Fällen nützlich sein, in denen das Codemodul basierend auf dem Status des Schritts dynamisch auf eine Vielzahl von Daten zugreift. Die Verwendung von Schrittparametern kann in diesem Fall zu einer langen Liste von Parametern führen, von denen nur einige tatsächlich unter verschiedenen Bedingungen verwendet werden.
Wenn Sie die TestStand-API in einem Codemodul verwenden, übergeben Sie eine Referenz zum SequenceContext-Objekt (ThisContext) als Parameter. Das SequenceContext-Objekt bietet Zugriff auf alle anderen TestStand-Objekte, einschließlich der TestStand-Engine und des aktuellen Runstate. Die Sequenzkontextreferenz ist auch erforderlich, wenn Sie den Termination Monitor oder die modalen Dialog-VIs verwenden.
Verwenden Sie SequenceContext, um in Codemodulen auf die TestStand-API zuzugreifen, mit der Sie programmatisch auf Daten zugreifen können
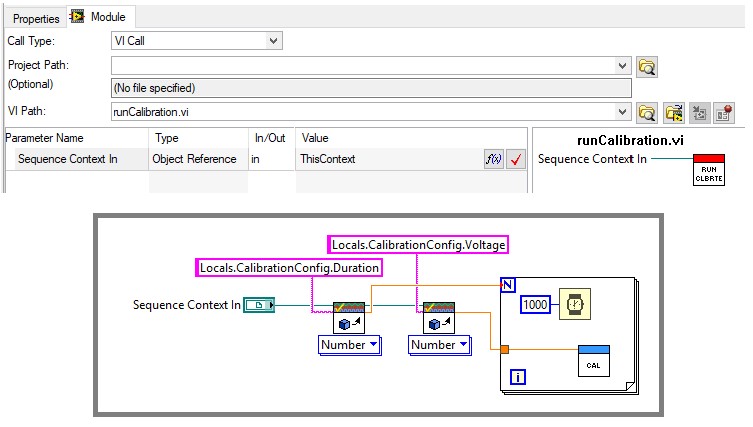
Wenn Sie Codemodule außerhalb von TestStand wiederverwenden, beachten Sie, dass alle Vorgänge, die die TestStand-API verwenden, nur verfügbar sind, wenn das Modul aus einer TestStand-Sequenz aufgerufen wird. Daten, die das Modul über die API von TestStand abruft, sind nicht verfügbar. Sie können einen alternativen Mechanismus zum Abrufen von Testdaten in Fällen definieren, in denen das Codemodul außerhalb von TestStand aufgerufen wird. Prüfen Sie dazu zunächst, ob die Sequenzkontextreferenz null ist. In LabVIEW können Sie die Funktion Keine Zahl/Kein Pfad/Keine Referenz? verwenden, die einen booleschen Wert zurückgibt, wie in Abbildung 3 dargestellt.
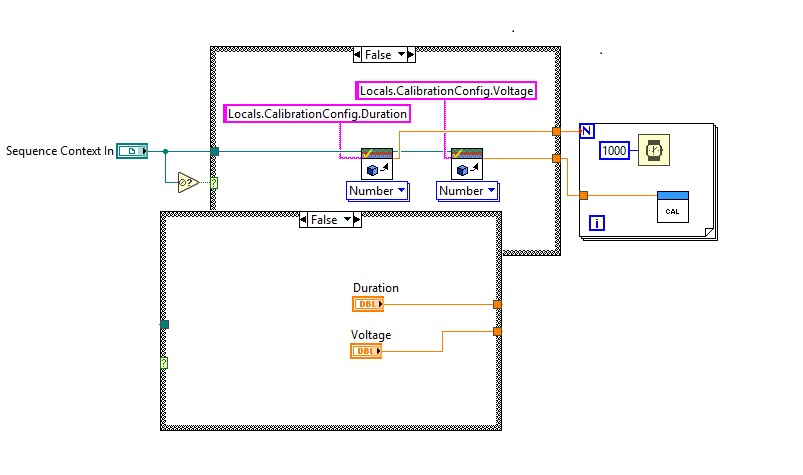
Verwenden Sie Keine Zahl/Kein Pfad/Keine Referenz?, um die Gültigkeit der SequenceContext-Objektreferenz für Codemodule zu überprüfen, die außerhalb von TestStand verwendet werden
Umgang mit großen Datensätzen in Codemodulen
In vielen Fällen können Codemodule große Mengen komplexer Daten aus Messungen oder Analysen erzeugen. Speichern Sie diese Art von Daten nicht in TestStand-Variablen, da TestStand beim Speichern eine Kopie der Daten erstellt. Diese Kopien können die Laufzeitleistung verringern und/oder Fehler wegen nicht genügend Arbeitsspeicher verursachen. Verwenden Sie die folgenden Ansätze, um große Datensätze zu verwalten, ohne unnötige Kopien zu erstellen:
- Arbeiten Sie innerhalb der Codemodule mit großen Datensätzen. Analysieren Sie beispielsweise Daten in demselben Codemodul, in dem sie erfasst wurden, und geben Sie nur die erforderlichen Ergebnisse an TestStand zurück.
- Übergeben Sie Datenzeiger zwischen TestStand und Codemodulen. Verwenden Sie für LabVIEW-Codemodule Datenwertreferenzen (DWR).
Verarbeitung der Sequenzbeendigung innerhalb von Codemodulen
Wenn ein Benutzer die Schaltfläche „Terminate“ (Beenden) drückt, stoppt TestStand die Ausführungssequenz und führt alle Bereinigungsschritte aus. Wenn die Ausführung jedoch ein Codemodul aufgerufen hat, muss das Modul die Ausführung abschließen und die Kontrolle an TestStand zurückgeben, bevor die Sequenz beendet werden kann. Wenn die Laufzeit eines Codemoduls länger als einige Sekunden ist oder wenn das Modul auf das Auftreten einer Bedingung wartet, z. B. eine Benutzereingabe, kann es dem Benutzer so erscheinen, als ob der Befehl zum Beenden ignoriert wurde.
Um dieses Problem zu beheben, können Sie den Termination Monitor verwenden, damit Codemodule den Beendigungsstatus der aufrufenden Ausführung überprüfen und darauf reagieren können. Im mitgelieferten Beispiel Computer Motherboard Test wird beispielsweise der Termination Monitor im Simulationsdialog verwendet (siehe unten). Wenn die Testsequenz beendet wird, gibt das VI „Check Termination state“ (Status der Beendigung prüfen) „False“ zurück, und die Schleife wird gestoppt.
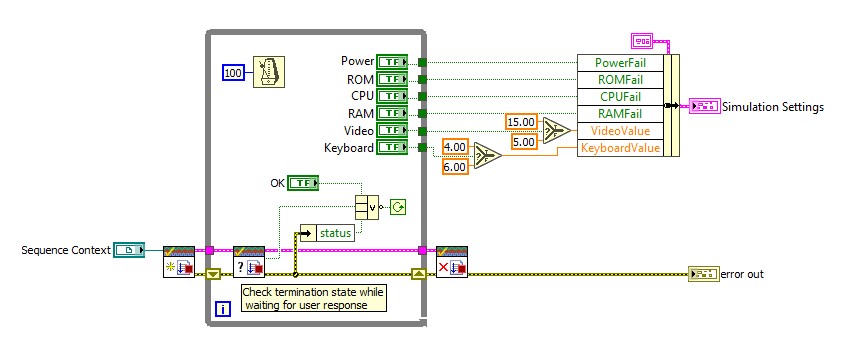
Weitere Informationen zur Verwendung des Termination Monitor finden Sie in den Termination Monitor-Beispielen.
Fehlerbehandlung
Ein Fehler in einem Testsystem ist ein unerwartetes Laufzeitverhalten, das die Durchführung von Tests verhindert. Wenn ein Codemodul einen Fehler erzeugt, geben Sie diese Informationen an die Testsequenz zurück, um zu bestimmen, welche Aktion als Nächstes ausgeführt werden soll, z. B. das Beenden der Ausführung, das Wiederholen des letzten Tests oder die Rückfrage beim Testoperator.
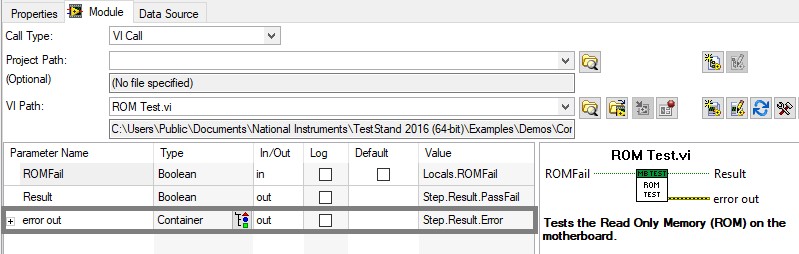
Verwenden Sie den Result.Error-Container des Schritts, um TestStand Fehlerinformationen von Codemodulen bereitzustellen, wie unten gezeigt. TestStand prüft diese Eigenschaft nach jedem Schritt automatisch, um festzustellen, ob ein Fehler aufgetreten ist. Sie müssen keine Fehlerinformationen von TestStand an das Codemodul übergeben. Wenn das Codemodul einen Fehler an TestStand zurückgibt, kann die Ausführung zu einem anderen Teil der Testsequenz verzweigen, z. B. zur Bereinigungsschrittgruppe.
Mithilfe der Einstellung On Run-Time Error (Bei Laufzeitfehler) auf der Registerkarte „Execution“ (Ausführung) der Stationsoptionen können Sie bestimmen, wie TestStand auf Schrittfehler reagiert. In der Regel sollten Sie beim Entwickeln Ihrer Sequenzen die Option „Show Dialog Box“ (Dialogfeld anzeigen) verwenden, um die Fehlersuche zu unterstützen, da Sie mit dieser Option die Ausführung unterbrechen und den aktuellen Status der Sequenz prüfen können. Verwenden Sie für bereitgestellte Systeme die Option „Run Cleanup“ (Bereinigung ausführen) oder „Ignore“ (Ignorieren), anstatt eine Eingabe von Testbetreibern anzufordern. Fehlerinformationen werden automatisch in den Testergebnissen protokolliert, anhand derer Sie die Fehlerursache ermitteln können.
Übergeben Sie Fehlerinformationen an den Step.Result.Error-Container, um TestStand über einen aufgetretenen Schrittfehler zu benachrichtigen
Verwalten der Leistung und der Speicherauslastung von Codemodulen
Standardmäßig lädt TestStand alle Codemodule in einer Sequenzdatei in den Arbeitsspeicher, wenn Sie eine Sequenz in der Datei ausführen. Diese bleiben dann geladen, bis Sie die Sequenzdatei schließen. Mit diesen Einstellungen kann eine anfängliche Verzögerung auftreten, wenn Sie eine Sequenz starten, während die Module geladen sind. Nachfolgende Ausführungen der Sequenzdatei sind jedoch schneller, da die Module im Arbeitsspeicher verbleiben.
Sie können auf der Registerkarte „Run Options“ (Ausführungsoptionen) des Bereichs mit den Schritteinstellungen konfigurieren, wann ein Codemodul geladen und entladen wird. Normalerweise bieten die Standardladeoptionen die beste Leistung. In einigen Fällen kann es sich jedoch anbieten, das Codemodul mit der Option Load dynamically (Dynamisch laden) erst zu laden, wenn es verwendet wird. Codemodule, die in der typischen Ausführung nicht aufgerufen werden, z. B. Diagnosen, die erst ausgeführt werden, nachdem ein bestimmter Test fehlgeschlagen ist, sollten dynamisch geladen werden, da diese Module in den meisten Fällen überhaupt nicht geladen werden müssen.
Beachten Sie beim dynamischen Laden von Codemodulen, dass TestStand keine Probleme für die Codemodule meldet, bis das Codemodul geladen wurde. Das könnte erst gegen Ende einer längeren Ausführungsdauer erfolgen. Mit dem Sequence Analyzer können Sie jedoch vor der Ausführung überprüfen, ob eine Sequenz Fehler enthält. Das Analyseprogramm prüft sowohl statisch als auch dynamisch geladene Codemodule.
Bei speicherintensiven Codemodulen können Sie die Standardentladeoption ändern, um die Gesamtspeicherauslastung zu reduzieren. Setzen Sie das Modul beispielsweise auf Unload After Step Executes (Entladen nach Schrittausführung) oder Unload After Sequence Executes (Entladen nach Sequenzausführung). Diese Änderung verlängert jedoch die Ausführungsdauer, da TestStand das Modul für jeden nachfolgenden Aufruf neu laden muss. Verwenden Sie nach Möglichkeit eher die 64-Bit-Version von TestStand und ein System mit mehr physischem Speicher, um trotz hoher Speicherauslastung die schnellste Testleistung zu erzielen.
Wenn Ihre Codemodule gemeinsam genutzte Daten wie statische Variablen oder funktionale globale LabVIEW-Variablen verwalten, kann das Ändern von Entladeoptionen zu Verhaltensänderungen führen, da globale Daten beim Entladen von Modulen verloren gehen. Stellen Sie beim Ändern der Entladeoptionen sicher, dass alle erforderlichen Daten entweder an die TestStand-Sequenz übergeben oder in einem dauerhafteren Speicherort gespeichert werden, um Datenverlust zu vermeiden.
Weitere Informationen zu anderen Möglichkeiten zur Optimierung der Leistung eines Testsystems finden Sie unter Best Practices for Improving NI TestStand System Performance (Empfohlene Methoden zur Verbesserung der Leistung des NI TestStand-Systems).
Verwenden der Instrumentierung in Codemodulen
Eine häufige Verwendung für Codemodule ist die Anbindung an Testhardware, um Stimuli einzurichten und Testmessungen durchzuführen. Zu den Hardware-Kommunikationsmethoden gehören:
• Verwenden eines Hardwaretreibers wie NI-DAQmx für die direkte Kommunikation mit der Hardware
• Verwenden eines Gerätetreibers, der intern Befehle über den VISA- oder IVI-Hardwaretreiber an ein Gerät sendet
Die von Ihnen verwendete Kommunikationsmethode hängt von der Art der verwendeten Hardware ab. Für beide Kommunikationstypen öffnen Sie eine Referenz oder Sitzung zum Treiber, bevor Sie treiberspezifische Aufrufe tätigen. Sie schließen das Handle, nachdem die Interaktion abgeschlossen ist.
Auswählen eines Ansatzes zum Verwalten von Hardwarereferenzen
In den meisten Fällen kommunizieren Sie in mehreren Testschritten mit derselben Hardware. Um die Leistungsauswirkungen des Öffnens und Schließens der Geräte-Session in jedem Codemodul zu vermeiden, müssen Sie überlegen, wie Sie Hardwarereferenzen in Ihren Testsequenzen verwalten. Es gibt zwei gängige Ansätze zum Verwalten von Hardwarereferenzen:
- Verwalten Sie Hardwarereferenzen manuell, indem Sie Initialisierungs- und Schließfunktionen aus Ihren Codemodulen aufrufen.
- Verwenden Sie den Session-Manager, um die Lebensdauer der Hardwarereferenzen automatisch zu verwalten.
Wenn Sie einen Gerätetreiber verwenden oder über die VISA- oder IVI-Treiber direkt mit Geräten kommunizieren, verwenden Sie den Session-Manager, es sei denn, Sie müssen die Lebensdauer der Hardware-Sessions direkt steuern. Wenn Sie einen Hardwaretreiber wie DAQmx verwenden, können Sie den Session-Manager nicht verwenden. Dann müssen Sie Referenzen manuell verwalten.
Manuelles Verwalten von Hardwarereferenzen mithilfe von TestStand-Variablen
Wenn Sie das Gerät initialisieren, übergeben Sie die Session-Referenz als Ausgabeparameter an die aufrufende Sequenz und speichern Sie die Referenz dann in einer Variablen. Anschließend können Sie die Variable als Eingabe an jeden Schritt übergeben, der auf das Gerät zugreifen muss.
Viele Treiber, einschließlich NI-DAQmx, VISA und die meisten Gerätetreiber, verwenden den Datentyp I/O-Referenz zum Speichern von Session-Referenzen. Verwenden Sie den LabviewIOControl-Datentyp in TestStand, um diese Referenzen zu speichern.
Verwenden Sie eine Variable mit dem Typ LabVIEWIOControl, um Hardwarereferenzen wie eine DAQ-Taskreferenz zwischen Codemodulen zu übergeben
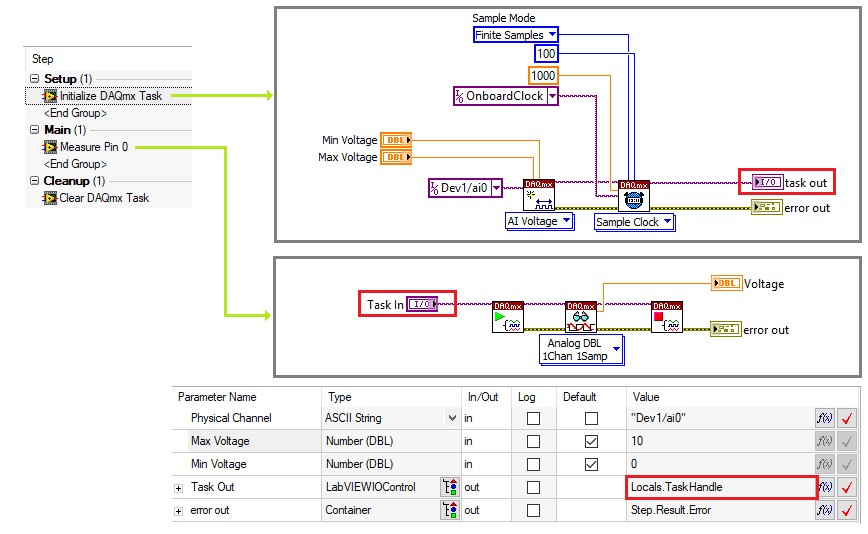
Wenn Sie Geräte-Handles explizit zwischen TestStand und Codemodulen übergeben, speichern Sie die Hardwarereferenz in einer lokalen Variablen. Wenn die Hardware über mehrere Sequenzen hinweg verwendet wird, übergeben Sie das Handle als Sequenzparameter an jede Sequenz, die es erfordert. Verwenden Sie keine globalen Variablen zum Speichern von Hardwarereferenzen, da nur schwer sichergestellt werden kann, dass das Gerät vor der Verwendung der Referenz initialisiert wurde.
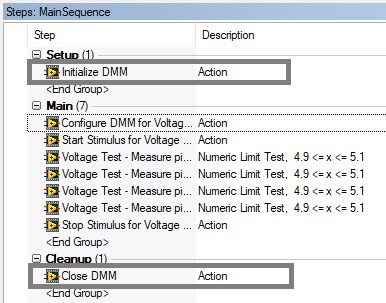
Verwenden Sie aus folgenden Gründen die Schrittgruppe „Setup“ zum Initialisieren der Hardware und die Schrittgruppe „Cleanup“ (Bereinigung) zum Schließen von Hardwarereferenzen:
- Hardwarereferenzen werden weiterhin geschlossen, wenn der Benutzer die Sequenzausführung beendet, da die Bereinigungsschrittgruppe immer ausgeführt wird, wenn eine Ausführung beendet wird.
- Ermöglicht die interaktive Ausführung von Schritten, die die Hardwarereferenz verwenden, da die Schrittgruppen für Setup und Bereinigung vor und nach den ausgewählten Schritten ausgeführt werden.
Verwenden Sie die Gruppen „Setup“ und „Cleanup“ (Bereinigung), um Hardwarereferenzen zu initialisieren und zu schließen
Manuelles Verwalten von Hardwarereferenzen mit Session-Manager
Für VISA- und IVI-Geräte-Handles können Sie den Session-Manager verwenden, um Hardwarereferenzen automatisch zu verwalten. Die Verwendung des Session-Managers bietet viele Vorteile, darunter:
- Reduzierte Kopplung: Sie müssen keine Geräte-Handle-Variablen zwischen Softwarekomponenten übergeben. Stattdessen gibt jede Komponente einen logischen Gerätenamen an, um eine Session zu erhalten.
- Weniger Einschränkungen aufgrund von Programmiersprachen: Codemodule, die in unterschiedlichen Sprachen geschrieben sind, können dieselbe Session gemeinsam nutzen, ohne Handles zu übergeben, die möglicherweise nicht einfach zwischen Sprachen konvertiert werden können.
- Lebensdauerkontrolle: Da Geräte-Sessions ActiveX-Objekte mit Referenzzählern sind, können Sie die Lebensdauer der Session an die Lebensdauer einer ActiveX-Referenzvariablen binden. So müssen Sie das Gerät in Sprachen, die ActiveX-Referenzvariablen unterstützen, nicht mehr explizit schließen.
Der Session-Manager initialisiert das Handle automatisch, nachdem die Session erstellt wurde, und schließt das Handle automatisch, wenn die letzte Referenz zur Session freigegeben wird. Codemodule und Sequenzen übergeben einen logischen Namen wie „DMM1“, um ein Session-Objekt vom Session-Manager abzurufen, das das entsprechende Geräte-Handle enthält.
Speichern Sie bei Verwendung des Session-Managers das Session-Objekt in einer TestStand-Objektreferenzvariablen. Da die Session-Lebensdauer mit der Lebensdauer der Objektreferenzvariablen verknüpft ist, wird das Geräte-Handle einmal pro Ausführung initialisiert und geschlossen, unabhängig davon, wie viele Sequenzcodemodule und Untersequenzen auf dieselbe Session zugreifen.
Im folgenden Beispiel erhält der Schritt „Get DMM Session“ (DMM-Session abrufen) eine Referenz zum Geräte-Session-Objekt für das DMM für den logischen Namen. Der Schritt speichert die Session-Referenz in einer lokalen Variablen, sodass die Session für die Dauer der Sequenzausführung initialisiert bleibt.
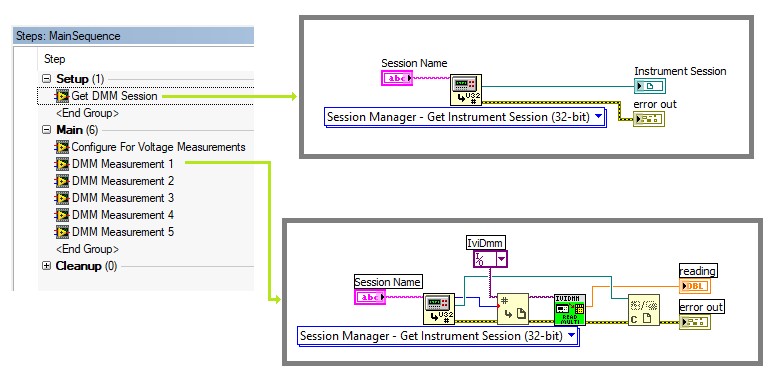
Verwenden Sie den Session-Manager, um Geräte mit einem logischen Namen zu referenzieren. Das Session-Manager-VI erhält die DMM-I/O-Referenz unter Verwendung des logischen Namens
Weitere Informationen zur Verwendung des Session-Managers finden Sie in der NI Session Manager-Hilfe unter <Programme>\National Instruments\Shared\Session Manager.
In der vorherigen Beispielsequenz wird die Session von einem LabVIEW-Codemodul abgerufen, das den Session-Manager aufruft, anstatt durch direkten Aufruf des Session-Managers, da in diesem Beispiel der LabVIEW-Adapter so konfiguriert wurde, dass VIs in einem separaten Prozess ausgeführt werden. Weitere Informationen zur Verwendung des Session-Managers finden Sie in der NI Session Manager-Hilfe unter <Programme>\National Instruments\Shared\Session Manager.
Aufrufen von Hardwaretreiberbibliotheken
Für die Kommunikation mit jeder Art von Hardware verwenden Sie Treiberbibliotheken. Diese stellen eine Reihe von Funktionen bereit, mit denen Sie mehrere Aufgaben mit einer Programmiersprache ausführen können. Wenn Sie Treiberbibliotheken verwenden, rufen Sie häufig mehrere VIs oder Funktionen auf, um eine einzelne logische Operation auszuführen, z. B. eine Messung durchzuführen oder einen Trigger zu konfigurieren. Das Erstellen eines Codemoduls zum Implementieren dieser Funktionalität anstelle des direkten Aufrufs der Bibliotheksfunktionen aus einem TestStand-Schritt bietet mehrere Vorteile:
- Vermeidet den Overhead der Schrittfunktionalität um jede Funktion
- Bietet eine Abstraktionsschicht zwischen Treiberaufrufen und TestStand-Sequenzen
- Erleichtert die gemeinsame Nutzung der Implementierung über Testprogramme hinweg