Multicore-Programmierung mit LabVIEW
Überblick
Inhalt
- Die Herausforderung der parallelen Programmierung
- Automatische Ausnutzung der Vorteile von Multicore-Prozessoren
- Manuelle Thread-Erstellung
- Intuitive Darstellung parallelen Codes
- Task-Parallelität
- Datenparallelität
- Pipelining
- Leistungsstarke grafische Fehlerbehebungswerkzeuge
- „Multicore-Ready“-Softwarestapel mit Echtzeit-SMP-Unterstützung
- Lösungen für die größten Anwendungsherausforderungen
Die Herausforderung der parallelen Programmierung
Parallele Programmierung wird zunehmend zu einer Notwendigkeit, um das volle Potenzial von Multicore-Prozessoren auszunutzen. Aus verschiedenen Gründen, u. a. Stromverbrauch und Speicherbandbreite, können die Taktraten moderner Prozessoren nicht weiter erhöht werden. Stattdessen integrieren CPU-Hersteller nun mehrere Prozessorkerne mit gleichbleibenden oder sogar verringerten Taktfrequenzen auf einem Chip. Das bedeutet, dass nun Anwendungen erstellt werden müssen, die auf Multicore-Prozessoren ausgeführt werden können. Sollten Anwendungen nicht für eine Multicore-Ausführung optimiert werden, kann es zu Leistungseinbußen kommen.
Um sich dieser Herausforderung zu stellen, stehen verschiedene Werkzeuge zur Verfügung, mit denen Programmcode erstellt werden kann, der das volle Potenzial von Multicore-Prozessoren nutzt. Eine Möglichkeit besteht im manuellen Zuweisen von Codeabschnitten auf Threads, die dann vom Betriebssystem auf die verschiedenen Prozessorkerne aufgeteilt werden. Allerdings kann sich die Verwaltung der Threads schwierig und zeitaufwändig gestalten. Zwar abstrahieren einige Programmiersprachen und APIs die Arbeitsschritte mit Threads, jedoch müssen Anwender trotzdem festlegen, welche Operationen parallel ausgeführt werden sollen.
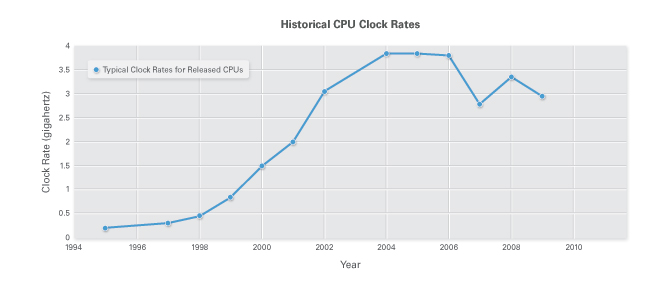
Abbildung 1: CPU-Taktraten werden nicht weiter erhöht, stattdessen sorgen nun Multicore-Prozessoren für Leistungssteigerungen.
Automatische Ausnutzung der Vorteile von Multicore-Prozessoren
Programmierung in LabVIEW bedeutet die Erstellung grafischen Codes (G), der einem Flussdiagramm ähnelt. Dies unterscheidet sich grundlegend von der Programmierung mit traditionellen, sequenziellen Sprachen. Die grafische Programmierung wird auch als Datenflussprogrammierung bezeichnet. Anstelle von Befehlssequenzen, die nacheinander ausgeführt werden, enthält LabVIEW Variablen, die durch Operationen miteinander verbunden werden. Der LabVIEW-Compiler legt dabei automatisch fest, in welcher Reihenfolge Befehle ausgeführt werden, um das gewünschte Ergebnis zu erzielen. Das bedeutet auch, dass in LabVIEW zwei voneinander unabhängige, parallele Codeabschnitte zur gleichen Zeit auf unterschiedlichen Cores des Prozessors ausgeführt werden können.
Dies wird durch das einfache arithmetische Programm in Abbildung 2 verdeutlicht. LabVIEW erkennt, dass sowohl die Multiplizier- und Addierfunktion als auch die Subtrahierfunktion parallel ausgeführt werden können, da sie nicht voneinander abhängen.
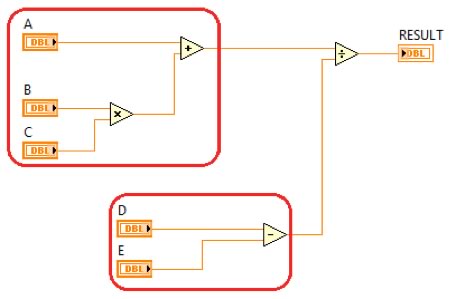
Abbildung 2: Unabhängige Codepfade können simultan ablaufen.
Der LabVIEW-Compiler identifiziert verschiedene parallele Codeabschnitte auf dem Blockdiagramm und weist diese zur Ausführung einer festgelegten Anzahl an Threads zu. Somit ist es nicht notwendig, Threads manuell zu verwalten. Des Weiteren wird verhindert, dass zu viele Threads erstellt werden, was zu Leistungseinbußen führen kann.
Manuelle Thread-Erstellung
LabVIEW verwaltet Threads und die Zuweisung auf Multicore-Prozessoren zwar automatisch, jedoch besteht weiterhin die Möglichkeit der manuellen Verwaltung. Es kann z. B. notwendig sein, einen spezifischen Task wie die Überwachung einer Notfallbedingung in einem dedizierten, priorisierten Thread auszuführen. Timing-Strukturen in LabVIEW, wie z. B. die zeitgesteuerte Schleife, erstellen jeweils einen einzelnen Thread, in dem der Code der Struktur ausgeführt wird. Die Threads können über die Option „Zuordnen von Prozessorressourcen“ während der Entwicklungs- wie auch der Ausführungszeit einem spezifischen Prozessorkern zugewiesen werden. Mit LabVIEW können Anwender sich in allererster Linie auf die Problemlösung konzentrieren, behalten aber, wenn notwendig, trotzdem eine Low-Level-Kontrolle.
Intuitive Darstellung parallelen Codes
LabVIEW bietet noch einen weiteren wichtigen Vorteil beim Einsatz von Multicore-CPUs: die intuitive grafische Darstellung parallelen Codes. Parallele Programme können zwar auch mit traditionellen, sequenziellen Sprachen erstellt werden, doch ist es häufig eine Herausforderung, den Überblick über parallele Operationen zu behalten. Da Entwickler bei der Erstellung umfangreicher Anwendungen häufig in Teams arbeiten, stellt die Dekodierung parallelen Codes, der von anderen geschrieben wurde, häufig eine weitere Schwierigkeit dar.
Im Gegensatz dazu stellt die Datenflussprogrammierung von LabVIEW eine einfache Kommunikationsform dar: das Flussdiagramm. Seit Jahren nutzen sequenzielle Programmierer Flussdiagramme, um einen Überblick über die Programmelemente zu behalten und miteinander zu kommunizieren. Anstatt Flussdiagramme in sequenziellen Code zu übersetzen und umgekehrt, können bei grafischem Code Entwicklungsideen direkt implementiert werden. Zudem können parallele Codepfade, die auf unterschiedlichen Prozessorkernen ausgeführt werden können, schnell identifiziert werden.
LabVIEW 8.5 führte den automatischen Multithreading-Scheduler vom Desktop – bekannt als symmetrisches Multiprocessing (SMP) – in deterministische Echtzeitsysteme mit Verbesserungen des LabVIEW Real-Time Module ein.
Task-Parallelität
Task-Parallelität bedeutet, dass mindestens zwei separate Operationen parallel ausgeführt werden können. Im untenstehenden LabVIEW-Code ist zu sehen, dass die Filter- und FFT-Operation nicht voneinander abhängig sind und somit simultan auf verschiedenen Prozessorkernen ausgeführt werden können.
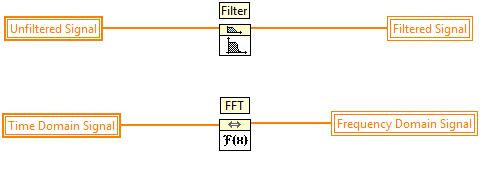
Abbildung 3: Beispiel für die Task-Parallelität
Datenparallelität
Bei der Datenparallelität handelt es sich um ein gängiges Programmiermuster, bei dem ein großer Datenabschnitt in kleinere Abschnitte aufgeteilt wird, die simultan ablaufen, bevor die Ergebnisse zusammengeführt werden. Im nachfolgenden Code werden die Aufteilung der Datenkanäle, die Verarbeitung und Wiederzusammenführung dargestellt.
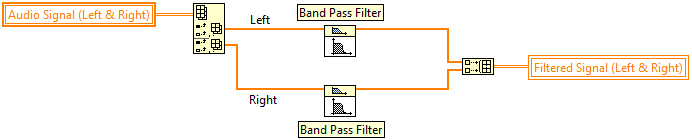
Abbildung 4: Ein Beispiel für Datenparallelität
Pipelining
Pipelining ist eine Art Fließband für Operationen, bei dem Funktionen wiederholt durchgeführt und die Daten an die nächste Operation weitergegeben werden. In LabVIEW kann das Pipelining mithilfe von Feedback-Knoten zwischen Operationen dargestellt werden.
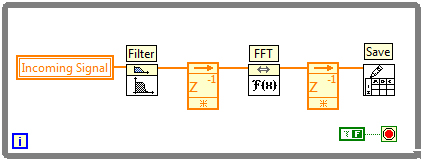
Abbildung 5: Ein Beispiel für Pipelining
Ein Großteil realer Anwendungen wie z. B. RF-Signalverarbeitung und Bildanalyse nutzt eine Kombination dieser und anderer paralleler Programmiermuster. So können beispielsweise mehrere Pipelines in ein LabVIEW-Blockdiagramm implementiert werden, das sowohl Task-Parallelität als auch Pipelining repräsentiert. Mithilfe der intuitiven Darstellung des parallelen Codes in LabVIEW können Anwendungen für Multicore-Prozessoren optimiert werden.
Leistungsstarke grafische Fehlerbehebungswerkzeuge
Die Fehlerbehebung ist ein wichtiger Bestandteil der Anwendungsentwicklung und LabVIEW bietet sowohl integrierte grafische Fehlerbehebungsfunktionen als auch Anbindungsmöglichkeiten für Zusatzprogramme. Mit der Highlight-Funktion in LabVIEW können Anwender sehen, wie Daten zwischen Operationen fließen und paralleler Code simultan ausgeführt wird. Das LabVIEW Desktop Execution Trace Toolkit zeigt zudem die exakte Sequenz der Anwendungsereignisse. Bei LabVIEW-Hardwarezielen, die Echtzeitbetriebssysteme ausführen, zeigt das NI Real-Time Execution Trace Toolkit den vollständigen Programmverlauf der auf den jeweiligen CPU-Cores ausgeführten Threads mit detaillierten Zeitangaben an, sodass Probleme wie Prioritätsumkehrung, bei der ein Task mit höherer Priorität auf die Ausführung eines Tasks mit niedrigerer Priorität warten muss, identifiziert und behoben werden können. Die Möglichkeit, zu sehen, welcher Thread auf welchem Core zu welchem Zeitpunkt und unter Verwendung welcher Ressourcen ausgeführt wird, ermöglicht eine Optimierung der Leistung und Zuverlässigkeit.
„Multicore-Ready“-Softwarestapel mit Echtzeit-SMP-Unterstützung
Intel hat vier Lagen des Software-Stacks definiert, mit denen Sie die „Bereitschaft“ für die Multicore-Entwicklung evaluieren können. Beachten Sie, dass parallele Programme auf Multicore-Systemen nicht schneller ausgeführt werden, wenn die verwendeten Bibliotheken und Treiber nicht „Multicore-bereit“ sind oder das Betriebssystem keine Lastverteilung zwischen Tasks über mehrere Core hinweg ermöglicht.
| Softwarestapel | Bedeutung von „Multicore-Ready“ | LabVIEW-Unterstützung |
|---|---|---|
| Entwicklungswerkzeug | Unterstützung wird auf dem Betriebssystem Ihrer Wahl bereitgestellt; das Werkzeug erleichtert das korrekte Threading und hilft bei der Optimierung | Beispiel: Multithread-Natur von LabVIEW und Strukturen, die eine Optimierung ermöglichen |
| Bibliotheken | Thread-sichere, ablaufinvariante Bibliotheken | Beispiel: Analyse-Bibliotheken |
| Gerätetreiber | Treiber für optimale Multithread-Leistung konzipiert | Beispiel: NI-DAQmx-Treibersoftware |
| Betriebssystem | Betriebssystem unterstützt Multithreading und Multitasking und kann Tasks ausbalancieren | Beispiel: Unterstützung für Windows, macOS, Linux und Echtzeitbetriebssysteme |
Abbildung 6: Beschreibung eines „Multicore-Ready“-Softwarestapels
Ein Beispiel auf der Ebene der Gerätetreibersoftware ist die Treibersoftware NI-DAQmx. Der traditionelle NI-DAQ-Treiber ist threadsicher, d. h. die gesamte Bibliothek verhindert, dass andere Threads aufgerufen werden, wenn eine NI-DAQ-Funktion aufgerufen wird.
Auf den ersten Blick kann dieses Verhalten logisch erscheinen, da NI-DAQ zur Steuerung von Hardware verwendet wird, die oft als eine einzelne Ressource betrachtet wird. NI-DAQmx, der neu entwickelte moderne Datenerfassungstreiber, ist ablaufinvariant. Das heißt, mehrere Datenerfassungs-Tasks können parallel ausgeführt werden, ohne Threads zu blockieren.
Mit diesem Ansatz kann der Treiber mehrere Tasks, etwa analoge und digitale I/O, parallel auf demselben Gerät ausführen.
Auf der niedrigsten Ebene des Software-Stacks, dem Betriebssystem, unterstützen viele der führenden Anbieter von Real-Time-Betriebssystemen (RTOS) noch keine automatische Lastverteilung von Threads über mehrere Kerne hinweg.
Mit LabVIEW 8.5 wird der automatische Multithreading-Scheduler vom Desktop (SMP) auf deterministische Echtzeitsysteme mit Verbesserungen am LabVIEW Real-Time Module übertragen.
Lösungen für die größten Anwendungsherausforderungen
Zusätzlich zur Programmierung von Multicore-CPUs kann LabVIEW auch mit anderer paralleler Hardware, u. a. FPGAs, grafischen Verarbeitungseinheiten und sogar Computing Clouds, eingesetzt werden. Alle diese Hardwareplattformen haben individuelle Eigenschaften sowie Vor- und Nachteile, jedoch gibt LabVIEW Ingenieuren und Wissenschaftlern genau die richtigen Werkzeuge an die Hand, um die passende Plattform für die jeweilige Anwendungsanforderung optimal zu nutzen. Da LabVIEW mit ganz unterschiedlicher Hardware eingesetzt werden kann, können Anwender die grafische Programmierung für eine große Auswahl an Projekten mit paralleler Verarbeitung nutzen.
Tatsächlich setzen Wissenschaftler, die an den komplexesten Forschungsprojekten der Welt arbeiten – von der Erforschung der Kernfusion bis zum weltgrößten Teleskop – LabVIEW zusammen mit paralleler Hardware ein. LabVIEW wurde dafür konzipiert, Anwender der unterschiedlichsten Branchen dabei zu unterstützen, ihre Ideen in funktionierende Programme umzuwandeln. Da LabVIEW mithilfe des intuitiven grafischen Codes automatisch das volle Potenzial von Multicore-Prozessoren ausschöpft, können Anwender stets die aktuellste parallele Hardware einsetzen, um sich technischen und wissenschaftlichen Herausforderungen zu stellen.