可用性とは
内容

概要
「RASM」とは、機能システムの4つの関連特性、Reliability (信頼性)、Availability (可用性)、Serviceability (保守性)、Manageability (管理性) の頭文字をとったものです。初期のコンピュータ業界で、製品の堅牢性を表すのに、「RAS」 (Reliability (信頼性)、Availability (可用性)、Serviceability (保守性)) という頭字語を初めて使用した企業の1つが、IBM社であると一般的に考えられています[1]。「Manageability (管理性)」の「M」は、信頼性、可用性、保守性を多角的に促進することでシステムの堅牢性を支援する役割があるとして、最近追加されました。RASM機能は、テスト、計測、制御、実験およびそれらに関連するビジネス目標に大きく貢献します。
変化の激しい現代の経済では、企業は資産の効率を最大限に高める必要があります。自動テストシステム、データ収集システム、制御システムといった資産は、極力常時稼働していることが求められます。そのため、ダウンタイムは大きなコストとなります。ムーアの法則に近いペースで複雑化するコンピュータベースのシステムでは、新しい機能の追加がシステムの信頼性を脅かす可能性があり、故障やダウンタイムの危険性が高まります。システムが決して故障しないという前提は、理想的ではありますが多くの場合非現実的です。そのため、利用状況を測定し、タスクの実行に必要な可用性を確保する必要があります。利用状況の測定は、複雑なコンピュータベースシステムの投資利益率を評価する方法として一般的です。利用率を測る最もシンプルな方法は、システムが使用された時間とシステムの稼働時間の割合を算出することです。
そして可用性を測る最もシンプルな方法は、アップタイム (システムがタスクを実行している時間) をアップタイムとダウンタイム (システムがタスクを実行していない時間) を足したもので除算する方法です。
[2]
この比率は必要な時にシステムが「利用可能」な確率を表すもので、パーセントに変換することができます。つまり可用性とは、必要な時にシステムがタスクを実行できる確率ということになります。ここで注意しておきたいのは、100パーセントの可用性でも、必ずしも利用率が100パーセントとは限らないということです。その理由は需要の不足、不十分な需要計画、オペレータのスキル不足などによるダウンタイムです。多くの企業は、システムを週7日24時間休まず稼働させて、利用率を最大限に高め資産をフルに活用したいと考えています。さらに可用性は、この数十年の間に、通信や情報技術、製造などの産業分野で、システムの品質を測る基準として重要度が大きく拡大しました。
このホワイトペーパーでは、ダウンタイムを回避するという観点から可用性の基本概念について解説します。
略語のACTとは、ダウンタイムを防ぐための3つの基本策を表したものです。
1) 厳密で質の高い設計、プランニング、調達、製造によりダウンタイムを回避 (Avoid) する
2) 積極的な障害予知機能と予防保全により、ダウンタイムを計画外の機能停止から計画的な機能停止に変換 (Convert) する
3) システム内に別の冗長部品、または自動エラー補正機能などを組み込むことで、コンポーネントの故障を許容 (Tolerate) する
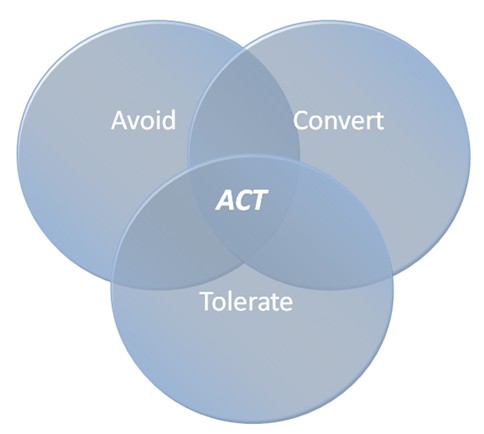
図1. ACT方式の相互関係を表した図
可用性の定義
There are many definitions for availability, but all contain the probability of a system operating as required when required.
Hence, availability is the probability that a system will be available to preform its function when called upon.
The "Nines" of Availability
In high-demand applications that are commonly in service 24/7, the availability is frequently measured by the number of “nines.” If availability is 99.0 percent, it is stated to be “2 nines,” and if it is 99.9 percent, it is called “3 nines,” and so on. Figure 2 depicts the amount of downtime a system exhibits within one year (365 days) of continuous (24/7) desired operation and its associated number of nines, which are calculated using this formula:
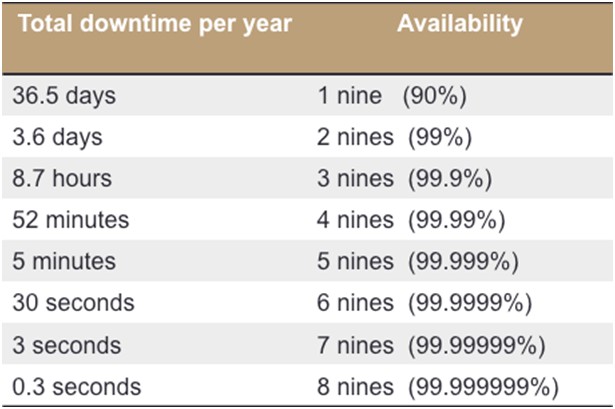
Figure 2. Downtime Allowed for 24/7/365 Usage Profile per Nines of Availability
Achieving greater than 4 nines of availability is a challenging task that often requires critical system components that are redundant and hot-swappable. Note that hot-swappable components can help reduce the time to repair a system, or mean time to repair (MTTR), which enhances serviceability. And reduced service time increases the availability. This is one way availability and serviceability are related.
ライフサイクルの各段階における可用性
図3に示すバスタブ曲線について考えてみます。この曲線は、その形状から名付けられており、システムまたは製品の経時的な故障率を示しています。製品寿命は4つの期間、つまり準備期、初期故障期、偶発故障期、摩耗故障期に分けることができます。故障の理由とメカニズムは期間によって異なります。予期せぬタイミングでの故障を防ぐため、それぞれの期間で異なる点について考慮する必要があります。図3は、これらの故障メカニズムを示しています。
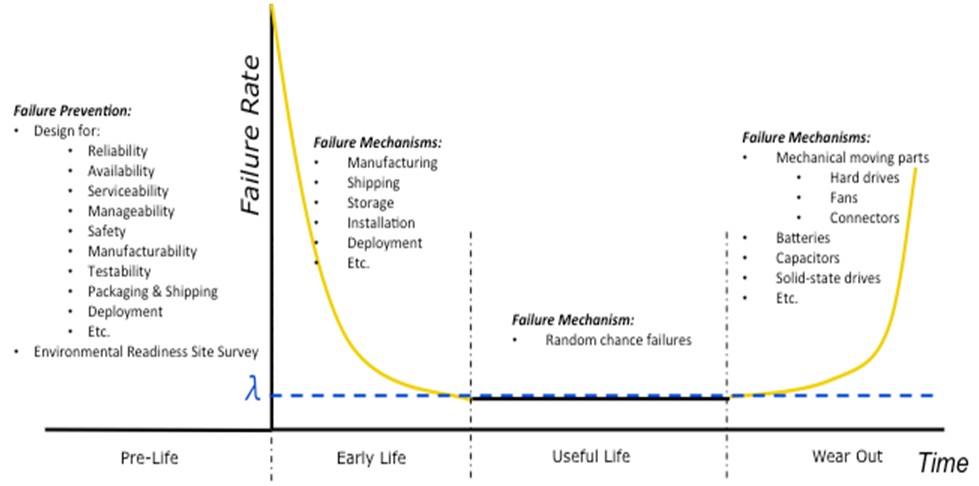
図3. バスタブ曲線
第1段階:準備期
「勝兵は先ず勝ちて而る後に戦いを求める。」
–孫子
準備期で重視されるのは、プランニングと設計です。システムの設計/プランニング段階は、可用性に多大な影響をもたらす可能性があります。しかし適切な設計を行うには、まずシステムが必要とする可用性のレベルを把握する必要があります。
可用性のニーズを特定する際に検討すべき主な要素を以下に説明します。しかしこれらがすべてではありません。
ダウンタイムのコスト:検討すべき要素としてはこれが最も基本的なものです。この情報から、システムにかかるコスト、あるいはどの程度の可用性を許容できるかがわかります。ダウンタイムのコストには、生産/販売ができなかった分のコストや、従業員/顧客が職務を行えなかったコストが含まれます。
冗長化コンポーネントの要件:可用性を高める1つの方法として、システムの重要なコンポーネントや「故障率の高いコンポーネント」を複製しておくことができます。これは一見システムの投資利益率を下げるコストとなります。しかしGeneral Electric社によると[3]、家電メーカーにとって、システムが一度使用不可になるだけで平均コストは100,000ドルにもなります。そのため使用できない状況を1回防ぐだけでも多額を節約することができ、その一部の額を冗長化コンポーネントの費用に充てることができます。
予備部品戦略:故障した部品をすぐに交換できるように予備部品を近くに置いておくことも、MTTRの削減になり、さらには可用性の向上になります。予備部品もソリューションのコストに加算されますが、部品故障の際に交換部品を注文して届くのを待つ期間は、システムが使えなくなります。それがダウンタイムのコストとなり、予備部品を在庫として保持するコストを上回る可能性があります。
診断ツール要件: 故障した部品を特定することは、修理する上で非常に重要です。そのため、故障をすばやく正確に診断し、さらには予知することが望まれます。それは、効果的な管理機能によって実現できます。優れた管理性は保守性の向上につながり、結果的に可用性が高まります。管理性、保守性、可用性はこのように関係しています。
運用/サービススキル:予備部品の準備と同様に、診断と修理の技術を持つ人員がいると可用性が向上します。さらに、予防保全に精通した人員を確保することも可用性の向上には重要です。
環境要因:システムが稼働する環境も、可用性には大きな影響をもたらします。たとえば、いつシステムにアクセスできるかということです。システムが過酷な環境でのデータ収集に使用されている場合、周囲の危険が取り除かれるまで、人員が立ち入ることは困難です。そしてそのような状況はMTTRの大幅な遅延につながります。その他にも、不安定な電力やホコリ、振動、交通量などの環境要因は、システムの適切な稼働に悪影響があります。システムの設置と実装の前にEnvironmental Readiness Site Survey (ERSS) の調査を行っておくと、そのような要素を効果的に評価できるほか、求められる可用性を実現するのに環境がどのように影響するかを理解することができます。
第2段階:初期故障期
初期故障期は、一般に偶発故障期に比べ高い故障率が特徴です。このような故障は、一般に「初期死亡率」と呼ばれます。 このような初期故障は、システムを最大負担の状態で長時間テストすることによって顕在化させることができます。これは通常システムの実装前に行われます。多くの場合製造欠陥や製造テスト時に検出されなかった不良部品や、出荷・保管・設置時の損傷が原因とされます。これらの問題が解決されると、故障率は急激に低下します。
初期故障は、無駄な時間とコストを費やすことになるため、システムの品質に対する第一印象が悪くなります。そのため、実装の完了と製造システムの稼働開始の前に、意図した用途に従って実際のターゲット環境でテストする必要があります。この初期テストは、基本的に欠陥製品がないことを確認するのが目的です。メーカーは各製品の最終的な検証テストを出荷前に実施しますが、出荷後の最終検証テストや製造環境でもシステム全体のテストを行うことはできません。潜在的な製造欠陥が製造テストで見逃されるだけでなく、製品は出荷、保管、設置、または実装時にも損傷することがあります。
第3段階:偶発故障期
偶発故障期とは、システムの初期問題が解決され、本来目的とする動作が安定的に行える信頼性の高い期間です。事後保全 (corrective maintenance: CM) と予防保全 (preventive maintenance: PM) という2種類の保守方式が、偶発故障期における可用性向上の鍵となります。
安定状態での故障に対応するCMには、故障したシステムを修理し運用/可用状態に戻すのに関わる全てのアクションが含まれます。上述のとおり、MTTRは効果の高いCMに重要です。PMに含まれるのは、システムを交換、修理してシステムの運用/可用状態を維持し、システム故障を防ぐために実施される全てのアクションです。PMは、定期メンテナンスの実施にかかる時間と頻度によって測定します。CM、PMともにシステムは可用状態でなくなるため、システムの重要部品が冗長であったり、システムが実施するサービスを中断せずにメンテナンスが行える状態でない限り、可用性は低下します。ホットスワップ可能なコンポーネントなら、可用性の低下を最低限に抑えた保守が可能です。
RASM工学の厳密な科学的・数学的概念の多くが適用されるのは、この偶発故障期です。偶発故障期では、故障は「ランダムな偶発故障」と考えられており、一定の故障率があります。故障率が一定していれば、故障の予知に関連する数式もシンプルになります。
偶発故障期では、以下のように一定の故障率、「λ」を使用して平均故障間隔 (MTBF) を計算することができます。
[4]
故障率とMTBFがわかると、主に次の3つのタイプの可用性を計算することができます。
固有可用性
固有可用性 () は最もよく使用される基準で、システム故障のCMのみを考慮に入れ、偶発故障期における安定状態を一定の故障率と仮定するものです。ここではPMや計画的ダウンタイムは考慮しません。次のように推定されます。
[5]
MTBF = 平均故障間隔
MTTR = 平均復旧時間
達成可用性
達成可用性 () はCMおよびPMを考慮します。偶発故障期における故障率とPM率が一定の安定状態を想定している点で、固有可用性と似ています。これは保守部門から見た可用性と呼ばれることもあります。また、作業に適したツール、十分な訓練を受けた人員、オンサイト予備品など、PMの実装における理想的な状況を想定しています。その他の予期せぬ状況は想定されていません。次のように推定されます。
[5]
MTBMA = 平均保守間隔 (CMとPMを含む)
MMT = 平均保守時間 (CMとPM含む)
[5]
= 故障率 =
= PMの頻度 =
[5]
MTBF = 平均故障間隔
MTTR = 平均復旧時間
MPMT = 平均予防保全時間
運用可用性
運用可用性 () は、実際の製造環境での一定期間における実際のシステム可用性を示すものです。これには、CM、PM、管理上の理由、ロジスティック、社内イベント、悪天候など、あらゆるダウンタイムが関係してきます。運用可用性は現実を反映しています。システムは都合のいい時に故障するわけではありません。休暇前の夜中や、従業員が出払っている昼休み、最も精通した人が長期休暇中や非番の時、予備部品が欠品中だったり、悪天候による便の欠航で注文した部品が届かない時などに限って、システムは故障するものです。次のように推定されます。
[5]
MDT = 平均ダウンタイム = MMT + (ロジスティック遅延) + (管理上の遅延) + (その他)
第4段階:摩耗故障期
摩耗故障期は、システムの故障率が偶発故障期の「基準」を上回るようになる頃が始まりです。この故障率の上昇は、基本的に部品の摩耗 (老化) が原因と推測されます。ファンなどの機械的回転部品、ハードドライブ、スイッチ、頻繁に使用するコネクタなどが通常最初に故障します。ただし、バッテリやコンデンサ、ソリッドステートドライブといった電気部品が最初に故障する場合もあります。ほとんどの集積回路 (IC) や電子部品は、仕様内での通常使用なら約20年[6]稼働します。
摩耗故障期では、信頼性は損なわれ、予測も難しくなります。システムがいつどのように摩耗するかの予測は、多くの信頼性の教科書で扱われ、信頼性工学または耐久性の分野で議論されてきました。この情報は予防保全と交換方針を確立するにあたって有益なものです。
まとめ
- 可用性とは、必要となった時にシステムが機能できる確率です。
- 可用性は、一般に「Nine」の数で表します。
- 冗長なしで「4 Nines」の可用性を実現するのは難しい課題です。
- システムのライフサイクルは、準備期、初期故障期、偶発故障期、摩耗故障期の4つの期間からなります。
- 準備期では、主に必要な可用性レベルを把握しそれに応じて計画を立てます。
- ダウンタイムのコストを把握することは重要です。
- Environmental Readiness Site Survey (ERSS) は、製造環境での可用性リスクを特定するのに有効なツールです。
- 初期故障期では、テストを実施してシステム運用の準備を整えます。
- MTBFとMTTRを使用して、偶発故障期での信頼性と可用性の両方を予測できます。また用途の概要に応じて、必要な予備部品数も予測できます。
- ACTは、可用性に影響するダウンタイムに対処するための3つの基本方法を表します。1) 厳密で質の高い設計、プランニング、調達、製造によりダウンタイムを回避 (Avoid) する。2) 積極的な障害予知機能と予防保全を使用して、ダウンタイムを計画外の機能停止から計画的な機能停止に変換 (Convert) する。3) システム内に別の冗長部品、または自動エラー補正機能などを組み込むことで、コンポーネントの故障を許容 (Tolerate) する。
関連情報
- Byron Radle、CRE
システム信頼性研究室、シニアエンジニア
National Instruments
-Tom Bradiich、PhD
研究開発フェロー
National Instruments
RASMホワイトペーパーシリーズは、Byron Radle (CRE) およびTom Bradicich (PhD) によって編集されています。今後寄稿をご希望の場合は、byron.radle@ni.comまたはtom.bradicich@ni.comまでEメールでご連絡ください。
[1] “Design and Evaluation,” 3rd ed., by Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems (A K Peters/CRC Press, 1998).
[2] “Reliability of Computer Systems and Networks,” by Martin L. Shooman, John Wiley & Sons, Inc., ISBN 0-471-29342-3, Chapter 1, Section 1.3.4, page 14.
[3] “High Availability for Non-Traditional Discrete and Process Applications,” GE Intelligent Platforms white paper (GFT-775).
[4] “Reliability Theory and Practice,” by Igor Bazovsky, Prentice-Hall, Inc.1961, Library of Congress Catalog Card Number:61-15632, Chapter 5, page 33.
[5] “Practical Reliability Engineering,” 5th ed., by Patrick D. O’Conner and Andre Kleyner, Wiley, ISBN 978-0-470-97981-5, Chapter 16, pages 409–410.
[6] Telcordia Technologies Special Report, SR-332, Issue1, May 2001, Section 2.4, pages 2–3.