マルチコア処理のプログラミング戦略:パイプライン処理
概要
「マルチコアプログラミングの基礎」ホワイトペーパーシリーズの一部です

「マルチコアプログラミングの基礎」ホワイトペーパーシリーズ
マルチコアアプリケーションをプログラミングする際は、今日のプロセッサの性能を活用するために特別な配慮が必要です。本書では、逐次タスクの実行中にパイプライン処理によってマルチコアCPUのパフォーマンス向上を図る方法について説明します。
内容
要約
マルチコアプロセッシングとマルチスレッドアプリケーションを開発するには、最新のCPU能力を最大限に引き出す方法を常に考える必要があります。従来のテキストベース言語では、並列化コードのプログラミングと視覚化が困難でしたが、NI LabVIEWのようなグラフィカル開発環境を使用することで、短い開発期間で新しいアイデアを実現することができます。
NI LabVIEWはデータフローに基づいているため本質的に並列的であるため、マルチスレッドアプリケーションのプログラミングを非常に簡単に行えます。ブロックダイアグラム上の独立したタスクは、プログラムが特別な作業を行わなくても自動的に並列実行されます。独立していないコードの場合はどうでしょうか。逐次処理的なアプリケーションを実装する際に、マルチコアCPUの能力を活かすためにはどうしたらよいでしょうか。
パイプライン処理とは
シリアルソフトウェアタスクの性能を高めるために一般的に採用されているテクニックが、パイプライン処理です。パイプライン処理とは、シリアルタスクを具体的なステージに分割し、組立ラインのような方法で実行できるようにするプロセスです。
例えば、自動組立ラインでの自動車の製造について考えてみます。最終タスクは完成した自動車を組み立てることですが、これを「フレームの組み立て」、「エンジンなど内部部品の取り付け」、「塗装」という3つの段階に分割します。
フレームの組み立て、部品の取り付け、塗装の各段階にはそれぞれ1時間かかると仮定します。したがって、1つの自動車を組み立てるために、3時間必要になります (図1参照)。
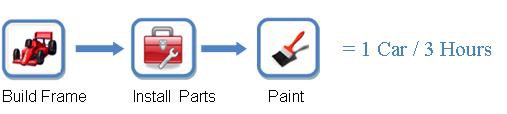
図1.この例では自動車の組み立てに3時間必要 (非パイプライン)
このプロセスはどのように改善できるでしょうか。フレームの組み立て、部品の取り付け、塗装のそれぞれの作業にシステムをセットアップするというのはどうでしょう。そうすれば1つの車の塗装中に、別の車の部品を取り付け、さらに別の車のフレームを組み立てることができます。
パイプライン処理によるパフォーマンス向上の仕組み
新しいプロセスでは、1つ1つの自動車を仕上げるためには同じく3時間かかりますが、3時間に1台ではなく1時間に1台分の自動車を完成させることができ、スループットが3倍に向上します。この例では、パイプライン処理の概念を簡略化して説明していますが、「重要な注意点」のセクションにはさらに詳細な説明が記述されています。
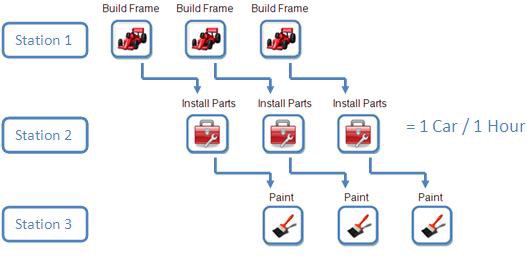
図2.パイプライン処理によるアプリケーションのスループット改善
LabVIEWでの基本的なパイプライン処理
自動車製造の例で示したパイプライン処理の概念は、逐次タスクを実行する場合のLabVIEWアプリケーションにも適用することができます。LabVIEWのシフトレジスタとフィードバックノードを使用して、各プログラムの「アセンブリライン」を形成することができます。以下の図は、複数のCPUコアで実行されるパイプライン処理アプリケーションの例を表しています。
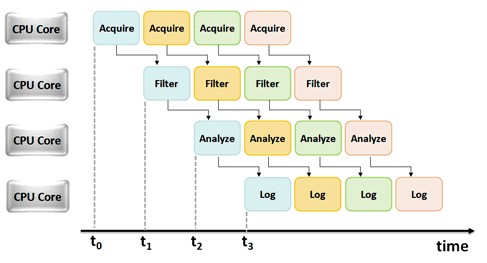
図3.複数のCPUコアで実行されるパイプライン処理を使用したアプリケーションのタイミング図
重要な注意点
パイプライン処理を使用して実際にマルチコアアプリケーションを作成する際には、いくつかの重要な注意点を考慮する必要があります。たとえば、パイプライン処理によってパフォーマンスを向上させるためには、パイプラインステージの負荷を調整し、コア間でのメモリ転送を最低限に抑える必要があります。
バランス調整段階
自動車の製造でも上述のLabVIEWプログラムの例でも、各パイプラインステージは実行にかかる時間が同じであると仮定されています。つまり、これらの例におけるパイプラインステージは平衡であると言えます。ただし、実環境のアプリケーションでは、なかなかそうは行きません。下図をよくご覧ください。ステージ1の実行にステージ2の3倍かかるとすると、2つのステージのパイプライン処理を行っても性能の向上はあまり期待できません。
非パイプライン処理 (合計時間 = 4秒):

パイプライン処理 (合計時間 = 3秒):
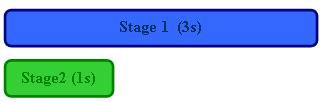
メモ:パフォーマンス向上 = 1.33倍 (パイプライン処理の効果が発揮されない)
状況を改善するため、プログラマはタスクをステージ1からステージ2に移動させて、両方のステージの実行時間が同程度になるようにする必要があります。しかしこれは、パイプラインステージの数が多い場合、難しいタスクです。
LabVIEWでは、パイプラインが平衡であることを確認するため、各パイプラインステージをベンチマークするとよいでしょう。これは、図4で示すようにフラットシーケンスストラクチャと「ティックカウント (ms)」関数を組み合わせて簡単に行うことができます。
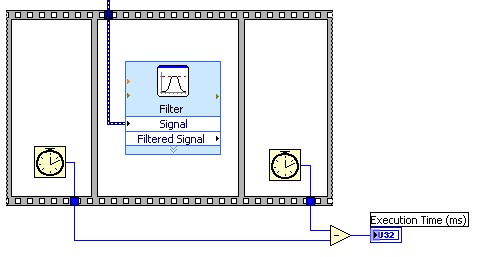
図4.パイプラインステージのベンチマークによるパイプライン処理の負荷調整確認
コア間でのデータ転送
パイプラインステージ間での大量のデータ転送は、可能な限り避けるのが最善です。パイプラインの各ステージは別々のプロセッサコア上で実行することがあるため、各ステージ間でデータを転送すると、実際には物理的なプロセッサコア間でのメモリの転送となる場合があります。2つのプロセッサコアに同じキャッシュがある場合 (あるいはメモリ転送サイズがキャッシュサイズを超える場合)、アプリケーションのエンドユーザにとってはパイプライン処理の効果が低下する可能性があります。
まとめ
パイプライン処理とは、本質的に逐次型のアプリケーションをマルチコアマシンで実行する際に性能の向上を実現できるテクニックです。CPUの各チップのコア数が増加する傾向にある現在では、アプリケーション開発にパイプライン処理などの手法を取り入れることが重要です。
パイプライン処理で最高の性能向上を実現するには、個々のステージの平衡化を注意深く行い、あるステージが他のステージより大幅に長い時間かかることのないようにする必要があります。また、パイプラインステージ間のデータ転送を最小限にすると、複数のコアがメモリにアクセスすることで性能が低下するのを防ぐことができます。