NI LabVIEW에서 멀티코어 프로세서를 사용하기 위해 자동화된 테스트 어플리케이션 최적화하기
개요
멀티코어 프로그래밍 기초 백서 시리즈

멀티코어 프로그래밍 기초 백서 시리즈
LabVIEW는 자동화된 테스트 어플리케이션을 위해 고유하고 사용하기 쉬운 그래픽 프로그래밍 환경을 제공합니다. 그러나 LabVIEW는 멀티 코어 프로세서에서 실행 속도를 높이는 코드를 다양한 CPU 코어에 동적으로 할당할 수 있습니다. 병렬 프로그래밍 기법을 활용하기 위해 LabVIEW 어플리케이션을 최적화하는 방법을 살펴보십시오.
내용
- 멀티스레드 프로그래밍의 과제
- 병렬 테스트 알고리즘 구현
- 사용자 정의 병렬 테스트 알고리즘 설정
- HIL (Hardware-in-the-Loop) 사용 분야 최적화
- 결론
- 멀티코어 프로그래밍 관련 추가 자료
멀티스레드 프로그래밍의 과제
최근까지 프로세서 기술이 혁신되면서 더 높은 클럭 속도로 작동하는 CPU가 컴퓨터에 탑재되었습니다. 그러나 클럭 속도가 이론적인 물리적 한계에 가까워지면서 기업들은 프로세싱 코어가 여러 개인 새로운 프로세서를 개발하고 있습니다. 자동화된 테스트 어플리케이션을 개발하는 엔지니어는 이러한 새로운 멀티코어 프로세서와 함께 병렬 프로그래밍 기법을 사용하여 성능과 처리량을 극대화할 수 있습니다. Edward Lee 박사는 캘리포니아 주립대학교 버클리캠퍼스의 전기 및 컴퓨터 공학 교수로 병렬 처리의 이점에 대해 설명합니다.
“많은 기술자가 무어의 법칙을 해결하는 방법으로 병렬 컴퓨터 아키텍처를 꼽고 있습니다. 컴퓨팅 성능을 계속해서 발전시키려면 프로그램에서 이러한 병렬 처리가 활용될 수 있어야 할 것입니다.”
또한 업계 전문가는 프로그래밍 어플리케이션에서 멀티코어 프로세서를 활용하는 것이 매우 어렵다는 점을 잘 이해하고 있습니다. Microsoft, Inc.의 창립자인 Bill Gates는 이렇게 설명합니다.
“병렬로 작동하는 프로세서의 성능을 최대한 활용하려면 소프트웨어에서 동시성 문제를 해결할 수 있어야 합니다. 그러나 멀티스레드 코드를 작성해 본 개발자라면 누구나 알고 있듯, 이는 프로그래밍에서 가장 어려운 작업 중 하나입니다.”
다행히 NI LabVIEW 소프트웨어에서는 주어진 어플리케이션에 여러 스레드를 다이나믹하게 할당 가능한 병렬 알고리즘을 생성하기 위한 직관적인 API가 내장된 이상적인 멀티코어 프로세서 프로그래밍 환경을 제공합니다. 실제로 멀티코어 프로세서를 사용하면 자동화된 테스트 어플리케이션을 최적화하여 성능을 극대화할 수 있습니다.
또한 PXI Express 모듈형 인스트루먼트는 PCI Express 버스의 높은 데이터 전송 속도를 활용하기 때문에 이러한 이점이 더욱 향상됩니다. 멀티코어 프로세서와 PXI Express 인스트루먼트의 이점을 활용하는 두 가지 구체적인 사용 분야는 멀티채널 신호 분석과 인라인 처리(Hardware in the Loop)입니다. 이 기술 백서에서는 다양한 병렬 프로그래밍 기법을 평가하고 각 기법에서 얻을 수 있는 성능상 이점에 대해 설명합니다.
병렬 테스트 알고리즘 구현
병렬 처리의 이점이 활용되는 일반적인 자동화 테스트 어플리케이션 중 하나는 다중 채널 신호 분석입니다. 주파수 분석은 프로세서를 집중적으로 사용하는 작업이기 때문에 테스트 코드를 병렬로 실행하여 각 채널의 신호 처리를 여러 프로세서 코어에 분산하는 방식으로 실행 속도를 높일 수 있습니다. 프로그래머 입장에서 보면 테스트 알고리즘의 구조를 약간만 변경하면 이러한 이점을 얻을 수 있습니다.
예를 들어, 고속 디지타이저의 2개 채널에서 다채널 주파수 분석(빠른 푸리에 변환 즉, FFT)을 위해 알고리즘 2개의 실행 시간을 비교합니다. NI PXIe-5122 14비트 고속 디지타이저는 채널 2개를 사용하여 최대 샘플 속도 (100MS/s)로 신호를 수집합니다. 먼저, LabVIEW에서 이 작업을 위한 기존의 순차적 프로그래밍 모델을 살펴보겠습니다.
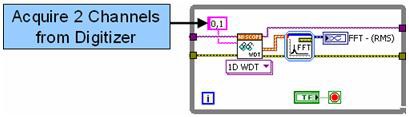
그림 1. LabVIEW 코드에서 순차적으로 실행할 경우
그림 1에서 볼 수 있듯 2개 채널의 주파수는 FFT 익스프레스 VI 내에서 분석되며, 여기서는 각 채널을 직렬로 분석합니다. 위 그림에서 보여주는 알고리즘은 멀티코어 프로세서에서도 효율적으로 실행될 수 있지만, 각 채널을 병렬로 처리하면 알고리즘 성능을 높일 수 있습니다.
알고리즘을 프로파일링하면 FFT를 완료하는 데 걸리는 시간이 고속 디지타이저에서 수집하는 것보다 훨씬 더 길다는 것을 알 수 있습니다. 각 채널을 한 번에 하나씩 가져오고 FFT 2개를 병렬로 수행하면 처리 시간을 크게 줄일 수 있습니다. 병렬 방식을 사용하는 새로운 LabVIEW 블록다이어그램은 그림 2를 참조하십시오.
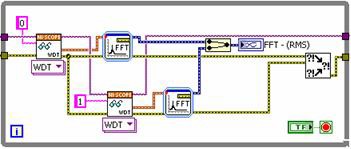
그림 2. LabVIEW 코드에서 병렬로 실행할 경우
디지타이저에서 각 채널을 순차적으로 가져옵니다. 2개 채널을 모두 고유한 인스트루먼트에서 가져오면 이러한 작업을 완전히 병렬로 수행할 수 있습니다. 그러나 FFT는 프로세서를 집약적으로 사용하기 때문에 신호 처리를 병렬로 실행하여 성능을 향상시킬 수 있습니다. 그 결과 전체 실행 시간이 단축됩니다. 그림 3은 두 구현의 실행 시간을 보여줍니다.
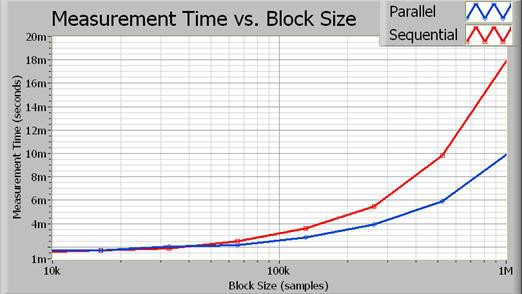
그림 3. 블록 크기가 커지면 병렬 실행을 통해 단축되는 처리 시간이 점점 더 확실하게 드러납니다.
실제로 병렬 알고리즘은 블록 크기가 클수록 성능이 2배 향상됩니다. 그림 4는 수집 크기(샘플 수)의 작용에 따른 정확한 성능 증가율을 보여줍니다.
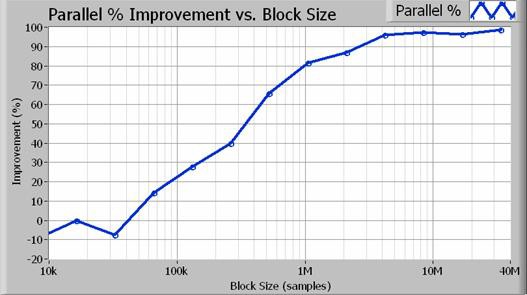
그림 4. 블록 크기가 100만 샘플(100Hz 분해능 대역폭)보다 큰 경우 병렬 방식을 사용하면 성능이 80% 이상 향상됩니다.
LabVIEW를 사용하여 각 스레드를 다이나믹하게 할당할 수 있기 때문에 멀티코어 프로세서에 대해 자동화된 테스트 어플리케이션의 성능을 손쉽게 개선할 수 있습니다. 이때 멀티스레딩을 활성화하기 위해 특별한 코드를 생성하지 않아도 됩니다. 대신, 프로그래밍을 최소한으로 조정하여 병렬 테스트 어플리케이션에서 멀티코어 프로세서의 이점을 활용할 수 있습니다.
사용자 정의 병렬 테스트 알고리즘 설정
병렬 신호 처리 알고리즘은 LabVIEW에서 프로세서를 여러 코어 간에 나눠 사용하는 데 도움이 됩니다. 그림 5는 CPU가 알고리즘의 각 부분을 처리하는 순서를 보여줍니다.
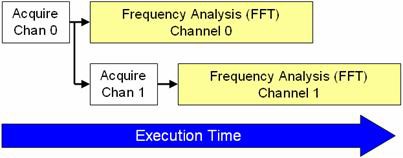
그림 5. LabVIEW는 수집된 데이터의 많은 부분을 병렬로 처리할 수 있어 실행 시간이 단축됩니다.
병렬로 처리하려면 LabVIEW에서 각 신호 처리 서브루틴을 복사(또는 복제)해야 합니다. 기본적으로 많은 LabVIEW 신호 처리 알고리즘이 "재호출 실행"이 가능하도록 설정되어 있습니다. 즉, LabVIEW에서는 별도의 스레드와 메모리 공간을 포함하여 각 서브루틴의 고유한 인스턴스를 다이나믹하게 할당할 수 있습니다. 따라서 사용자 정의 서브루틴을 재호출 방식으로 작동하도록 설정해야 합니다. LabVIEW에서 간단한 설정 단계 하나만 수행하면 이와 같이 설정할 수 있습니다. 이 프로퍼티를 설정하려면 파일 >> VI 프로퍼티를 선택하고 실행 항목을 선택합니다. 그런 다음 그림 6과 같이 재호출 실행 플래그를 선택합니다.
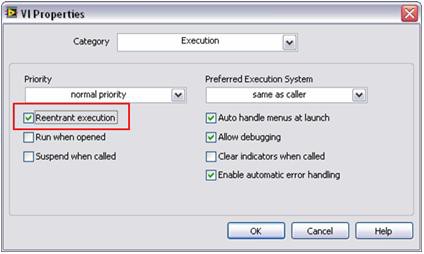
그림 6. 이 간단한 단계를 수행하면 표준 LabVIEW 분석 기능처럼 다양한 사용자 정의 서브루틴을 병렬로 실행할 수 있습니다.
이제 간단한 프로그래밍 기법을 사용하여 멀티코어 프로세서에서 자동화된 테스트 어플리케이션의 성능을 향상시킬 수 있습니다.
HIL (Hardware-in-the-Loop) 사용 분야 최적화
병렬 신호 처리 기법의 이점이 활용되는 두 번째 사용 분야는 동시 입력 및 출력에 인스트루먼트를 여러 개 사용하는 것입니다. 일반적으로 이러한 사용 분야를 HIL (Hardware-in-the-loop) 또는 인라인 처리 사용 분야라고 합니다. 이 경우 고속 디지타이저 또는 고속 디지털 I/O 모듈을 사용하여 신호를 수집할 수 있습니다. 소프트웨어에서 디지털 신호 처리 알고리즘을 수행합니다. 마지막으로 다른 모듈형 인스트루먼트에서 결과가 생성됩니다. 그림 7은 일반적인 블록다이어그램을 보여줍니다.

그림 7. 이 다이어그램은 일반적인 HIL (Hardware-in-the-loop) 사용 분야의 단계를 보여줍니다.
일반적인 HIL 사용 분야에는 인라인 디지털 신호 처리(필터링 및 보간 등), 센서 시뮬레이션, 사용자 정의 구성요소 에뮬레이션이 포함됩니다. 인라인 디지털 신호 처리 사용 분야에서 몇 가지 기법을 사용하여 처리량을 극대화할 수 있습니다.
일반적으로 단일 루프 구조와 큐가 있는 파이프라인 멀티루프 구조와 같은 두 가지 기본 프로그래밍 구조를 사용할 수 있습니다. 단일 루프 구조는 간단히 구현할 수 있고 크기가 작은 블록에서 지연 시간이 짧습니다. 반대로 멀티루프 아키텍처는 멀티코어 프로세서를 더 잘 활용하기 때문에 처리량이 훨씬 많습니다.
기존의 단일 루프 방식을 사용하면 고속 디지타이저 읽기 함수, 신호 처리 알고리즘, 고속 디지털 I/O 쓰기 함수를 순차적으로 배치할 수 있습니다. 그림 8의 블록다이어그램에서 볼 수 있듯, 각 서브루틴은 LabVIEW 프로그래밍 모델의 결정에 따라 연속적으로 실행되어야 합니다.
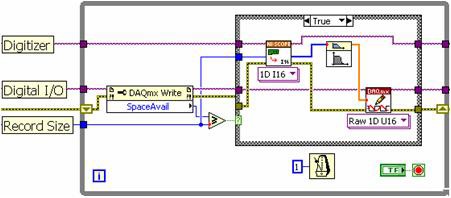
그림 8. LabVIEW 단일 루프 방식에서는 각 서브루틴이 직렬로 실행되어야 합니다.
단일 루프 구조에는 몇 가지 제한이 있습니다. 각 단계가 직렬로 수행되기 때문에 프로세서에서는 데이터를 처리하는 동안 인스트루먼트 I/O를 수행할 수 없습니다. 이 방식을 사용하면 프로세서가 한 번에 함수를 하나만 실행하기 때문에 멀티코어 CPU를 효율적으로 사용할 수 없습니다. 수집 속도가 낮을 때는 단일 루프 구조로 충분하지만 데이터 처리량을 늘리려면 멀티루프 방식이 필요합니다.
멀티루프 아키텍처는 큐 구조를 사용하여 각 While 루프 간에 데이터를 전달합니다. 그림 9는 큐 구조가 있는 While 루프 간 프로그래밍을 보여줍니다.
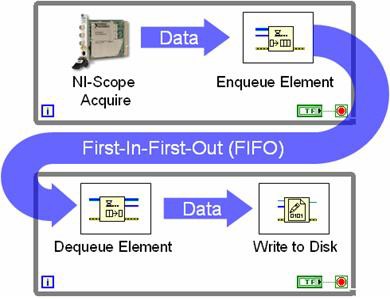
그림 9. 큐 구조를 사용하면 여러 루프가 데이터를 공유할 수 있습니다.
그림 9는 일반적으로 생산자-소비자 루프 구조를 나타냅니다. 이 경우 고속 디지타이저는 하나의 루프에서 데이터를 수집하고 반복될 때마다 새로운 데이터 세트를 FIFO에 전달합니다. 소비자 루프는 큐 상태를 간단히 모니터링하고 사용할 수 있게 되었을 때 각 데이터 세트를 디스크에 씁니다. 큐 사용은 루프 2개가 서로 독립적으로 실행된다는 점이 중요합니다. 위의 예에서 고속 디지타이저는 데이터를 디스크에 쓸 때 지연이 발생해도 계속해서 데이터를 수집합니다. 그 사이 추가 샘플은 FIFO에 저장됩니다. 일반적으로 생산자-소비자 파이프라인 방식은 프로세서를 보다 효율적으로 사용하여 데이터 처리량을 늘립니다. LabVIEW는 각 코어에 프로세서 스레드를 다이나믹하게 할당하기 때문에 이러한 이점은 멀티코어 프로세서에서 더욱 두드러지게 나타납니다.
인라인 신호 처리 사용 분야의 경우 독립적인 While 루프 3개와 큐 구조 2개를 사용하여 루프 간에 데이터를 전달할 수 있습니다. 이 시나리오에서는 루프 하나가 인스트루먼트에서 데이터를 수집하고, 두 번째 루프는 신호 처리를 전담하며 세 번째 루프가 두 번째 인스트루먼트에 데이터를 씁니다.
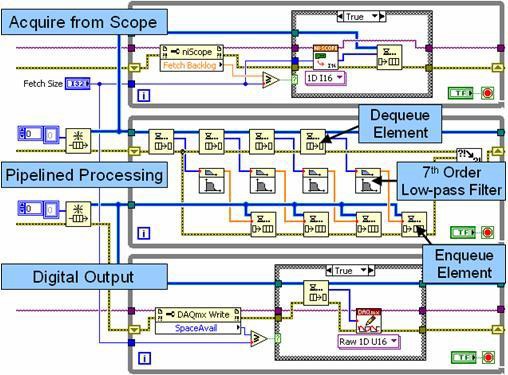
그림 10. 이 블록다이어그램은 여러 루프와 큐 구조가 있는 파이프라인 신호 처리를 보여줍니다.
그림 10에서 맨 위 루프는 고속 디지타이저에서 데이터를 수집하여 첫 번째 큐 구조위 (FIFO)에 전달하는 생산자 루프입니다. 중간 루프는 생산자 겸 소비자로 작동합니다. 반복할 때마다 중간 루프는 큐 구조에서 여러 데이터 세트를 언로드(소비)하고 파이프라인 방식으로 독립적으로 처리합니다. 이 파이프라인 방식은 데이터 세트를 최대 4개까지 독립적으로 처리하여 멀티코어 프로세서의 성능을 개선합니다. 중간 루프는 처리된 데이터를 두 번째 큐 구조로 전달하여 생산자의 역할도 수행합니다. 마지막으로, 맨 아래 루프는 처리된 데이터를 고속 디지털 I/O 모듈에 씁니다.
병렬 처리 알고리즘은 멀티코어 CPU의 프로세서 사용량을 높입니다. 실제로 전체 처리량은 프로세서 사용률과 버스 전송 속도, 이 두 가지 요소에 따라 달라집니다. 일반적으로 CPU와 데이터 버스는 큰 데이터 블록을 처리할 때 가장 효율적입니다. 또한 전송 시간이 더 빠른 PXI Express 인스트루먼트를 사용하면 데이터 전송 시간을 더욱 단축할 수 있습니다.
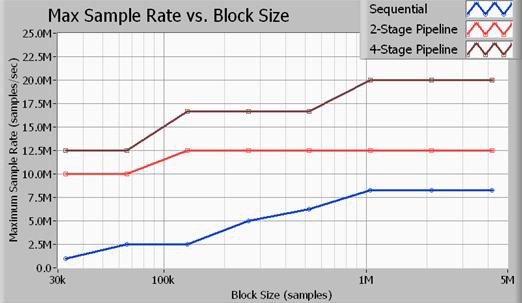
그림 11. 멀티루프 구조의 처리량은 단일 루프 구조보다 훨씬 많습니다.
그림 11은 수집 크기(샘플 수)에 따른 샘플 속도 기준 최대 처리량을 보여줍니다. 여기 표시된 벤치마크는 모두 16비트 샘플에서 수행되었습니다. 또한 사용된 신호 처리 알고리즘은 컷오프가 0.45x 샘플 속도인 7차 버터워스 저역 통과 필터입니다. 데이터에서 볼 수 있듯이 4단계 파이프라인(멀티루프) 방식을 사용하면 데이터 처리량이 극대화됩니다. 2단계 신호 처리 방식은 단일 루프 방법(순차적)보다 성능은 우수하지만, 4단계 방식만큼 프로세서를 효율적으로 사용하지 못합니다. 위 그림에 표시된 샘플 속도는 NI PXIe-5122 고속 디지타이저와 NI PXIe-6537 고속 디지털 I/O 모듈의 입력 및 출력의 최대 샘플 속도입니다. 총 버스 대역폭이 80MB/s일 때, 20MS/s에서 어플리케이션 버스는 입력의 경우 40MB/s, 출력의 경우 40MB/s의 속도로 데이터를 전송합니다.
또한 파이프라인 처리 방식에서는 입력과 출력 사이에 지연 시간이 발생한다는 점을 고려해야 합니다. 지연 시간은 블록 크기와 샘플 속도 등 여러 요소에 따라 달라집니다. 아래 표 1과 2는 단일 루프와 4단계 멀티루프 아키텍처에서 블록 크기와 최대 샘플 속도에 따라 측정된 지연 시간을 비교한 것입니다.
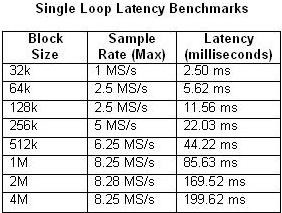
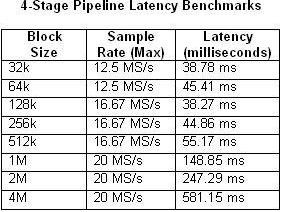
표 1 및 2. 단일 루프와 4단계 파이프라인 벤치마크의 지연 시간을 보여주는 표입니다.
예상대로 CPU 사용량이 100%에 가까워지면 지연 시간이 늘어납니다. 이는 4단계 파이프라인의 예에서 샘플 속도가 20MS/s일 때 특히 분명히 나타납니다. 이와 대조적으로 CPU 사용량은 단일 루프 예에서 50%를 겨우 넘습니다.
결론
PXI 및 PXI Express 모듈형 인스트루먼트와 같은 PC 기반 인스트루먼트는 멀티코어 프로세서 기술의 발전과 빨라진 데이터 버스 속도의 이점을 크게 누릴 수 있습니다. 새 CPU는 프로세싱 코어를 여러 개 추가하여 성능을 개선하기 때문에 CPU 효율성을 최대화하려면 병렬 또는 파이프라인 처리 구조가 필요합니다. 다행히 LabVIEW는 프로세싱 태스크를 개별 프로세싱 코어 여러 개에 다이나믹하게 할당하여 이러한 프로그래밍 문제를 해결합니다. 그림과 같이 병렬 처리를 활용하도록 LabVIEW 알고리즘을 구성하면 성능을 크게 향상시킬 수 있습니다.