NI does not actively maintain this document.
This content provides support for older products and technology, so you may notice outdated links or obsolete information about operating systems or other relevant products.

본 기술백서를 통해 현재 멀티코어 프로그래머들이 직면하고 있는 문제를 살펴보십시오. 특히 본 문서에서는 소프트웨어 아키텍처에 적용될 수 있는 멀티코어 패턴에 대해 살펴봅니다.
프로그램 패턴은 여러 저서에서 자세히 설명되어 있습니다. 따라서 본 문서에서는 하이 레벨에서 다음의 개념을 소개하며 LabVIEW에 어떻게 적용되는지 살펴봅니다.
1. 태스크 병렬
2. 데이터 병렬
3. 파이프라이닝
4. 구조화된 격자
소프트웨어 아키텍처 측면에서 어플리케이션 문제에 가장 적합한 병렬 패턴을 통합하십시오. 적합한 패턴을 선택하기 이전에 어플리케이션 특성과 하드웨어 아키텍처를 고려하십시오.
또한, 다양한 LabVIEW 구조는 위에서 열거된 패턴에서 조명됩니다. (일반 while 루프, 피드백 노드, 시프트 레지스터, timed 루프, 루프 병렬)
태스크 병렬은 병렬 프로그래밍의 가장 단순한 형태로써, 어플리케이션은 각각 독립적인 고유한 태스크로 나뉘어지며 개별 프로세서에서 실행됩니다. 두 개의 루프 (루프 A와 루프 b)가 있는 프로그램을 생각해보십시오. 루프 A는 신호 처리 루틴을 수행하며 루프 b는 사용자 인터페이스에 업데이트를 수행합니다. 이것이 태스크 병렬로써, 멀티스레드 어플리케이션이 여러 CPU를 활용하기 위해 개별 스레드에서 두 개의 루프를 실행합니다.
LabVIEW의 블록 다이어그램에서 코드가 병렬 부분을 가지고 있으면 태스크 병렬이 이루어집니다. LabVIEW의 장점은 코드에서 병렬을 "확인"할 수 있다는 점이고, 병렬을 위해 개별 고유 태스크를 편리하게 분리할 수 있다는 것입니다. 또한, LabVIEW는 어플리케이션을 자동 멀티스레딩 작업하므로 스레드 관리 또는 스레드간 동기화를 걱정할 필요가 없습니다.
대형의 배열 또는 행렬을 서브세트로 나누고 작업을 수행하여 결과를 통합함으로써 대형 데이터 세트에 데이터 병렬을 적용할 수 있습니다.
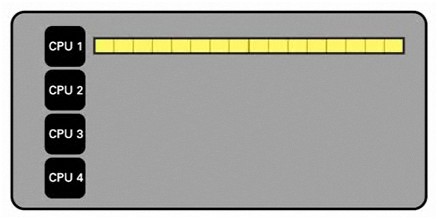
우선 단일 CPU가 전체 데이터 세트를 처리하는 시퀀스적인 실행을 생각해봅시다.
그림 - 단일 CPU 처리
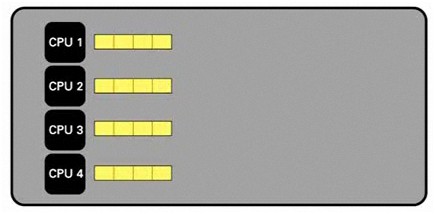
네 가지 부분으로 나뉘어지는 동일한 데이터 세트의 다음 예제를 생각해봅시다. 본 데이터 세트를 사용가능한 코어에 보내면 대폭 증대된 속도를 얻을 수 있습니다.
그림 - 여러 CPU 처리
컨트롤 시스템과 같은 리얼타임 고성능 연산 (HPC) 어플리케이션에서 일반적이며 효율적인 전략은 매우 큰 규모의 행렬-벡터 곱셈을 병렬로 실행하는 것입니다. 일반적으로 행렬은 고정되어 있으며, 행렬을 미리 분해할 수 있습니다. 센서로 수집된 측정은 루프별로 벡터를 제공합니다. 예를 들어, 액추에이터를 컨트롤하기 위해 행렬-벡터의 결과를 사용할 수 있습니다.
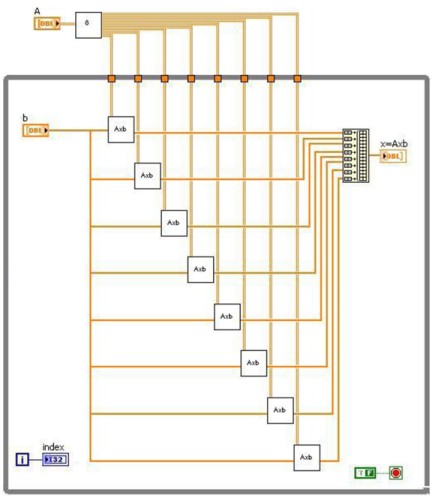
다음 블록 다이어그램은 8개의 코어에 분산된 행렬-벡터 곱셈입니다.
그림 - LabVIEW에서 행렬 벡터 곱셈
블록 다이어그램은 왼쪽에서 오른쪽으로 실행되며, 다음 단계를 수행합니다.
1. while 루프에 입력 전에 행렬 A 분리
2. 행렬 A의 각 부분을 벡터 b와 곱셈
3. 최종 결과 x=Axb 생성하는 벡터를 통합
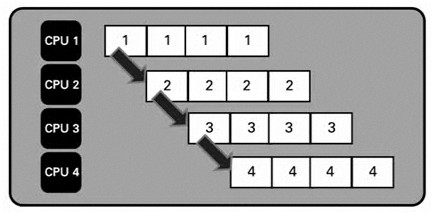
파이프라이닝은 조립 라인과 유사합니다. 스트리밍 어플리케이션에서 본 방식 사용을 고려하십시오. CPU 집약 알고리즘을 반드시 시퀀스로 변경해야 하며, 이 때 각 단계에는 상당한 시간이 걸립니다.
그림 - 알고리즘의 시퀀스적 단계
조립 라인과 마찬가지로 각 단계는 하나의 유닛 작업에 집중합니다. 각 결과는 다음 단계로 이동되며 마지막 단계까지 이릅니다.
멀티코어 CPU에서 실행되는 어플리케이션에 파이프라이닝 전략을 적용하기 위해, 알고리즘을 대략적으로 동일한 작업 유닛이 있고 개별 코어에서 각 단계를 실행하는 단계로 나누십시오. 알고리즘은 데이터의 여러 세트 또는 연속적으로 스트리밍하는 데이터에서 반복됩니다.
그림 - 파이프라이닝 방식
여기서 중요한 점은 각 반복은 전체 프로세스에서 가장 긴 개별 단계 만큼 시간이 걸리므로 알고리즘을 동일한 시간이 걸리는 단계로 나누는 것입니다. 예를 들어, 단계 2는 완성에 1분이 소요되고 단계 1, 3, 4는 각 10초가 소요된다면 전체 반복 잔업 완성에 1분이 소요되는 것입니다.
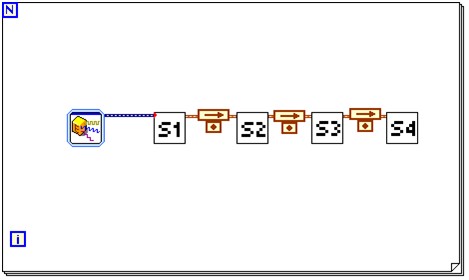
그림 4의 LabVIEW 블록 다이어그램은 파이프라이닝 방식의 예입니다. for 루프는 시퀀스로 실행되어야 하는 알고리즘의 함수를 표현하는 S1, S2, S3, S4로 구성됩니다. LabVIEW는 구조화된 데이터흐름 언어이므로, 각 함수의 출력은 와이어를 통해 다음 입력으로 보냅니다.
그림 - LabVIEW의 파이프라이닝 방식
피드백 노드는 작은 점 위의 화살표로 나타납니다. 피드백 노드는 함수의 분리를 개별 파이프라인 단계로 나타냅니다. 동일한 코드의 파이프라인되지 않은 버전은 비슷한 모습이지만 피드백 노드가 없습니다. 본 기술을 사용하는 일반적인 예로는 FFT가 한 번에 한 단계씩 조작이 요구되는 스트리밍 어플리케이션이 있습니다.
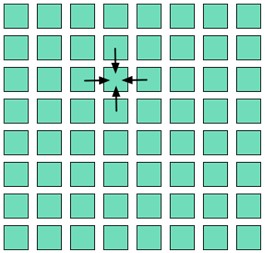
물리적 모델이 포함되는 여러 연산은 구조화된 격자 패턴을 사용합니다. 본 패턴에서 2D, 또는ND, (격자의 반복)을 계산하며, 각 업데이트된 격자값은 그림 8에서와 같이 그 주변의 함수입니다.
그림 - 구조화된 격자 방식
구조화된 격자의 병렬 버전에서, 격자를 하위 격자로 나누고 각 하위 격자를 개별적으로 연산합니다. 작업자간의 통신은 경계의 폭일 뿐입니다. 병렬 효율성은 영역-경계선 비입니다.
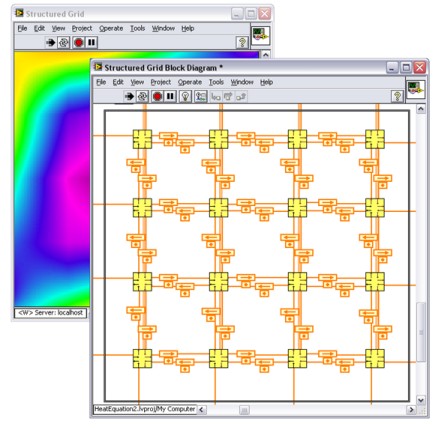
예를 들어, 다음 그림의 블록 다이어그램은 경계 조건이 지속적으로 변경되는 열 공식을 풀 수 있습니다.
그림 - LabVIEW에서 구조화된 격자 방식
16개의 시각 아이콘은 특정 격자 크기의 라플라스 방정식을 푸는 태스크를 표시하며, 여기서 라플라스 방정식은 열 공식을 푸는 하나의 방식입니다. 16개의 태스크는 16개의 코어를 나타냅니다. 루프의 각 반복마다 코어는 주변 조건을 교환하며, 프로세스가 글로벌 솔루션을 구축합니다. 피드백 노드는 작은 점 위의 화살표로 표현되며, 요소간의 데이터 교환을 나타냅니다. 이같은 블록 다이어그램을 1-, 2-, 3-, 4- 또는 8-코어 컴퓨터로 맵핑할 수도 있습니다. 더 많은 수의 코어가 있는 컴퓨터가 사용가능해짐에 따라 유사한 방식을 사용할 수 있습니다.
While 루프는 다양한 프로그래밍 패턴 (태스크 병렬성, 데이터 병렬성, 파이프라이닝 또는 구조화된 격자)에서 사용되는 기본적인 구조입니다. 패턴에 따라 일반적인 while 루프가 충분할 수도 있고, 또 다른 경우 특수한 유형의 while 루프 (timed 루프 등)가 적합할 수도 있습니다.
위에서 설명된 파이프라이닝 방식의 경우, 시프트 레지스터나 피드백 노드가 사용되어야 합니다. (동작은 본 경우 동일합니다.)
루프에 병렬을 사용하면, 내재적으로 병렬을 이룰 수 있도록 코드를 수행하는 병렬 "worker"의 개수를 프로그램적으로 설정할 수 있습니다. (다시 말해, 코드는 복합성을 추상화하며 각 다른 작업자를 각기 다른 코어로 맵핑합니다.) 병렬 실행을 극대화하기 위해 각 프로세서 코어에 대한 작업자를 생성하십시오.
병렬 For 루프는 하나의 반복에서 다음 반복까지 의존성 없이 루프에서 계속 반복적으로 실행해야 하는 집약적인 작업을 위한 방식입니다. 그러나, 만약 의존성이 있다면, 병렬 For 루프는 사용되어서는 안됩니다. 그 이유는 의존성은 알고리즘이 시퀀스별로 수행되어야 함을 의미하기 때문입니다. 본 경우, 파이프라이닝과 같은 다른 기술을 사용하여 병렬성을 구현해야 합니다.
timed 루프는 while 루프처럼 동작하지만, 멀티코어 하드웨어 구성에 기반하여 성능을 최적화할 수 있는 특별한 특성이 있습니다. 예를 들어, 멀티스레드를 활용하는 일반 while 루프와는 달리, timed 루프 내의 모든 코드는 단일 스레드에서 실행합니다. 이는 직관적인 것과 상반되어 보일 수 있으며, 단일 스레드 실행이 멀티 코어 시스템에서 왜 바람직한지에 대해 의문을 제기할 수도 있습니다. 특히, 이는 리얼타임 시스템에서 유용한 특성이며, 캐시 최적화가 중요한 경우 더욱 그러합니다. 단일 스레드에서 실행하는 것 이외에도, 루프는 스레드를 특정 CPU에 지정하기 위한 매커니즘인 프로세서 연계 (processor affinity)를 설정합니다. (따라서 캐시 최적화가 이루어짐)
일반 while 루프 (데이터 병렬과 파이프라이닝) 내에서 잘 작동하는 병렬 패턴이 timed 루프에서 작동하지 않는다는 사실을 명심해야 합니다. 그 이유는 단일 스레드에서는 병렬성이 이루어지지 않기 때문입니다. 그 대신, 기술은 여러 timed 루프를 사용하여 실행됩니다. 예를 들어, 파이프라이닝한 하나의 timed 루프는 FIFO를 통해 루프간 데이터 전송이 있는 파이프라인에서 고유한 단계를 표현합니다.
큐는 여러 루프간 데이터를 동기화하는 데 중요합니다. 예를 들어, 생산자/소비자 아키텍처를 실행하는 데 사용됩니다. 생산자/소비자 아키텍처는 병렬 프로그래밍에만 사용되는 것이 아니라 범용 프로그래밍 아키텍처에 주로 사용되는 개념이므로 본 문서에서는 따로 다루지 않습니다. 그러나 본 아키텍처는 멀티코어 CPU에서 작동하며, 이는 루프와 큐의 통합을 통해 가능한 일입니다.
리얼타임이 RT FIFO 사용을 요구하는 경우, 큐는 루프간 데이터를 공유하기 위한 결정성있는 매커니즘이 아니라는 점을 기억하십시오.
LabVIEW Real-Time에 특정한 기능으로써, CPU는 CPU Pool VI를 사용하여 특정 스레드 풀을 위해 "보존"됩니다. 이것은 캐시를 최적화하기 위한 또 다른 매커니즘입니다.
예를 들어, 어플리케이션이 쿼드 코어 시스템에서 실행된다고 생각해봅시다. 여기서 어플리케이션은 가능한한 신속하게 반복적으로 데이터를 실행됩니다. 데이터 세트가 실제로 CPU 캐시에 적합하다고 가정한다면 이같은 유형의 작업은 캐시에서 실행하기에 이상적입니다. 사실상, 캐시에서 작업을 실행하는 것은 코드를 병렬화하고 4개의 모든 CPI를 활용하는 것보다 더욱 효율적일 수 있습니다. 따라서, OS가 4개 (0-3)의 모든 CPU에서 병렬 태스크를 스케쥴하는 대신, 개발자들은 OS 스케쥴러 (CPU 0 및 2)에 대해 단 2개의 CPU만을 보존하도록 선택할 수 있습니다.(아마, 쿼드 코어에는 CPU 0과 1 사이에 대형의 공유 캐시가 있을 것이며, CPU 2-3간에 또 다른 대형 공유 캐시가 있을 것입니다.) CPU를 보존함으로써 개발자들은 데이터가 캐시에 있음을 보장하며, 또한 두 개의 대형 공유되는 캐시가 작업에 완벽하게 사용될 수 있음을 보장할 수 있습니다.
CPU Information VI는 LabVIEW 어플리케이션이 실행되는 시스템에 특정한 정보를 제공합니다. 본 정보는 어플리케이션이 다양한 머신 (듀얼 코어, 쿼드 코어 또는 심지어 옥타 코어)에 배포되었을 경우 매우 유용합니다.
어플리케이션이 CPU Information VI를 사용하면 "# of logical processors" 와 같은 파라미터를 읽을 수 있으며, 주어진 머신의 결과에 기반한 본 결과를 사용하여 병렬 For 루프에 결과를 입력합니다.
예를 들어, 어플리케이션이 듀얼 코어 머신에서 실행되는 경우, # of logical processors = 2 이며, 따라서 병렬 For 루프를 위한 최적의 숫자 설정은 2가 됩니다. 이를 통해 코드는 내부 하드웨어에 더욱 편리하게 적응할 수 있습니다.
추적은 멀티코어 어플리케이션을 디버깅하기 위한 매우 유용한 방식이며, 데스크탑 또는 리얼타임 시스템 모두에서 수행됩니다. Desktop Execution Trace Toolkit과 Real-Time Execution Trace Toolkit에 대한 제품 문서를 참조하십시오.
결론적으로, 전문 프로그래머들은 주어진 어플리케이션에 적절하게 맵핑을 하는 프로그래밍 패턴을 사용해야 합니다. 본 문서에서 다룬 패턴에는 태스크 병렬, 데이터 병렬, 파이프라이닝 및 구조화된 격자가 있습니다.
본 문서에 설명된 패턴을 더욱 효율적으로 활용하기 위해서, LabVIEW 개발자들은 각기 다른 구조, VI, 디버깅 도구를 통합하여 최적의 성능을 구현할 수 있습니다.