Utilisation de la variable partagée LabVIEW
Aperçu
LabVIEW donne accès à une grande variété de technologies pour créer des applications distribuées. La variable partagée simplifie la programmation nécessaire à de telles applications. Cet article fournit une introduction à la variable partagée et inclut une discussion de ses fonctionnalités et de ses performances.
En utilisant la variable partagée, vous pouvez partager des données entre des boucles sur un seul diagramme ou entre des VIs à travers le réseau. Contrairement à de nombreuses autres méthodes de partage de données existantes dans LabVIEW, telles que UDP/TCP, les files d’attente LabVIEW et les FIFO Real-Time, vous configurez généralement la variable partagée au moment de l’édition à l’aide des boîtes de dialogue de propriétés, et vous n’avez pas besoin d’inclure le code de configuration dans votre application.
Vous pouvez créer deux types de variables partagées : à un processus et publiée sur le réseau. Cet article présente en détail les variables partagées à un processus et les variables partagées publiées sur le réseau.
Contenu
- Création de variables partagées
- Variable partagée à un processus
- Variable partagée publiée sur réseau
- Le moteur de variables partagées
- Performance
- Tests de performance
Création de variables partagées
Un projet LabVIEW doit être ouvert pour créer une variable partagée. Depuis l’Explorateur de projet cliquez avec le bouton droit sur une cible, une bibliothèque de projet ou un dossier dans une bibliothèque de projet et sélectionnez Nouveau » Variable (New » Variable) dans le menu local pour afficher la boîte de dialogue Propriétés de la variable partagée (Shared Variable Properties). Sélectionnez parmi les options de configuration de variables partagées et cliquez sur le bouton OK.
Si vous cliquez avec le bouton droit sur une cible ou un dossier qui ne se trouve pas dans une bibliothèque de projet et sélectionnez Nouveau » Variable (New » Variable) dans le menu local pour créer une variable partagée, LabVIEW crée une nouvelle bibliothèque de projet et place la variable partagée à l’intérieur. Reportez-vous à la section Durée de vie des variables partagées pour plus d’informations sur les variables et les bibliothèques.
La Figure 1 montre la boîte de dialogue Propriétés de la variable partagée pour une variable partagée à un processus. Le module LabVIEW Real-Time et le module LabVIEW Datalogging and Supervisory Control (DSC) fournissent des fonctionnalités supplémentaires et des propriétés configurables aux variables partagées. Dans cet exemple, bien que le module LabVIEW Real-Time et le module LabVIEW DSC soient installés, vous pouvez utiliser les fonctionnalités ajoutées par le module LabVIEW DSC uniquement pour les variables partagées publiées sur le réseau.
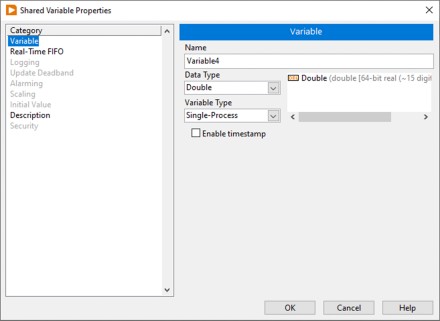
Figure 1. Propriétés de la variable partagée à un processus
Type de données
Vous pouvez sélectionner parmi un grand nombre de types de données standard pour une nouvelle variable partagée. En plus de ces types de données standard, vous pouvez spécifier un type de données personnalisé en sélectionnant Personnalisé (Custom) dans la liste déroulante Type de données (Data Type) et en accédant à une commande personnalisée. Cependant, certaines fonctionnalités telles que la mise à l’échelle et les FIFO Real-Time ne fonctionneront pas avec certains types de données personnalisés. De plus, si le module LabVIEW DSC est installé, l’alarme est limitée aux notifications de mauvais état lors de l’utilisation de types de données personnalisés.
Après avoir configuré les propriétés de la variable partagée et cliqué sur le bouton OK, la variable partagée apparaît dans la fenêtre de votre Explorateur de projet (Project Explorer) sous la bibliothèque ou la cible sélectionnée, comme illustré en Figure 2.
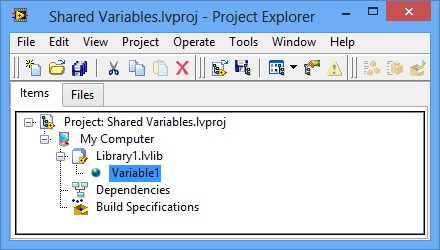
Figure 2. Variable partagée dans le projet
La cible à laquelle appartient la variable partagée est la cible à partir de laquelle LabVIEW déploie et héberge la variable partagée. Reportez-vous à la section Déploiement et hébergement pour plus d’informations sur le déploiement et l’hébergement de variables partagées.
Références de variables
Après avoir ajouté une variable partagée à un projet LabVIEW, vous pouvez faire glisser la variable partagée vers le diagramme d’un VI pour lire ou écrire la variable partagée, comme illustré en Figure 3. Les nœuds de lecture et d’écriture du diagramme sont appelés nœuds de variable partagée.
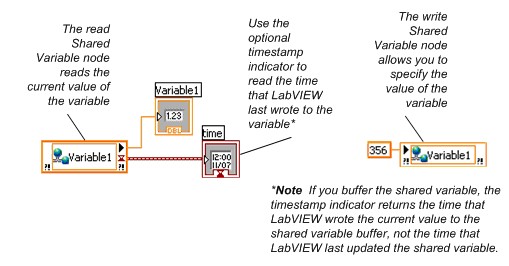
Figure 3. Lecture et écriture de variables partagées à l’aide de nœuds Variable partagée
Vous pouvez définir un nœud Variable partagée comme absolu ou relatif à la cible selon comment vous souhaitez que le nœud se connecte à la variable. Un nœud Variable partagée absolu se connecte à la variable partagée qui se trouve sur la cible sur laquelle vous avez créé la variable. Un nœud Variable partagée relatif à la cible se connecte à la variable partagée qui se trouve sur la cible sur laquelle vous exécutez le VI qui contient le nœud.
Si vous déplacez un VI qui contient un nœud Variable partagée relatif à la cible vers une nouvelle cible, vous devez également déplacer la variable partagée vers la nouvelle cible. Utilisez des nœuds Variable partagée relatifs à la cible si vous avez l’intention de déplacer les VIs et les variables vers d’autres cibles.
Les nœuds Variable partagée sont absolus par défaut. Cliquez avec le bouton droit sur un nœud et sélectionnez Mode de référence » Relatif à la cible (Reference Mode » Target Relative) ou Mode de référence » Absolu (Reference Mode » Absolute) pour modifier la façon dont le nœud Variable partagée se connecte à la variable partagée.
Vous pouvez cliquer avec le bouton droit sur une variable partagée dans la fenêtre Explorateur de projet (Project Explorer) et modifier les propriétés de la variable partagée à tout moment. Le projet LabVIEW propage les nouveaux paramètres à toutes les références de variables partagées en mémoire. Lorsque vous enregistrez la bibliothèque de variables, ces modifications sont également appliquées à la définition des variables stockée sur le disque.
Variable partagée à un processus
Utilisez des variables à un processus pour transférer des données entre deux emplacements différents sur le même VI qui ne peuvent pas être connectés par des câbles, tels que des boucles parallèles sur le même VI, ou deux VI différents au sein de la même instance d’application. L’implémentation sous-jacente de la variable partagée à un processus est similaire à celle de la variable globale LabVIEW. Le principal avantage des variables partagées à un processus par rapport aux variables globales traditionnelles est la possibilité de convertir une variable partagée à un processus en une variable partagée publiée sur le réseau à laquelle tout nœud d’un réseau peut accéder.
Variables partagées à un seul processus et LabVIEW Real-Time
Afin de maintenir le déterminisme, une application en temps réel nécessite l’utilisation d’un mécanisme déterministe non bloquant pour transférer des données de sections déterministes du code, telles que des boucles cadencées de priorité plus élevée et des VIs à priorité critique, vers des sections non déterministes du code. Lorsque vous installez le module LabVIEW Real-Time, vous pouvez configurer une variable partagée pour utiliser des FIFO Real-Time en activant la fonction FIFO Real-Time à partir de la boîte de dialogue Propriétés de la variable partagée (Shared Variable Properties). NI recommande d’utiliser des FIFO Real-Time pour transférer des données entre une boucle à priorité critique et une boucle de priorité inférieure. Vous pouvez éviter d’utiliser les VIs FIFO Real-Time de bas niveau en activant FIFO Real-Time sur une variable partagée à un processus.
LabVIEW crée un FIFO Real-Time lorsque le VI est réservé pour exécution (lorsque le VI de niveau supérieur dans l’application commence à s’exécuter dans la plupart des cas), donc aucune considération particulière de la première exécution du nœud Variable partagée est nécessaire.
Remarque : Dans les versions héritées de LabVIEW (antérieures à 8.6), LabVIEW crée un FIFO Real-Time la première fois qu’un nœud Variable partagée tente d’écrire ou de lire à partir d’une variable partagée. Ce comportement entraîne un temps d’exécution légèrement plus long pour la première utilisation de chaque variable partagée par rapport aux utilisations suivantes. Si une application nécessite un cadencement extrêmement précis, incluez des itérations « de préchauffage » initiales dans la boucle à priorité critique pour tenir compte de cette fluctuation des temps d’accès, ou lisez la variable au moins une fois en dehors de la boucle à priorité critique.
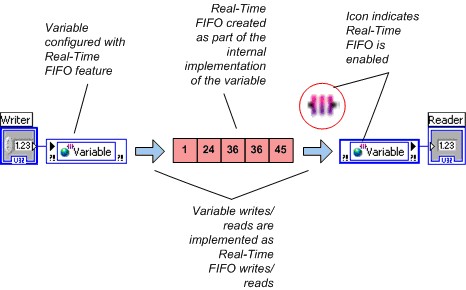
Figure 4. Variables partagées compatibles avec FIFO Real-Time
LabVIEW crée un FIFO Real-Time unique pour chaque variable partagée à un processus, même si la variable partagée a plusieurs scripteurs ou lecteurs. Pour garantir l’intégrité des données, plusieurs scripteurs se bloquent, tout comme plusieurs lecteurs. Cependant, un lecteur ne bloque pas un scripteur et un scripteur ne bloque pas un lecteur. NI recommande d’éviter plusieurs scripteurs ou plusieurs lecteurs de variables partagées à un processus utilisées dans les boucles à priorité critique.
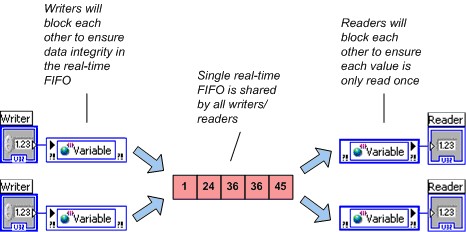
Figure 5. Plusieurs scripteurs et lecteurs partageant une seule FIFO
En activant le FIFO Real-Time, vous pouvez sélectionner entre deux types légèrement différents de variables compatibles FIFO : le buffer à élément unique et le buffer multi-éléments. Une distinction entre ces deux types de buffers est que la FIFO à élément unique ne signale pas les avertissements sur les conditions de débordement ou de sous-flux. Une deuxième distinction est la valeur que LabVIEW renvoie lorsque plusieurs scripteurs lisent un buffer vide. Plusieurs lecteurs de la FIFO à élément unique reçoivent la même valeur, et le FIFO à élément unique renvoie la même valeur jusqu’à ce qu’un scripteur écrive à nouveau dans cette variable. Plusieurs lecteurs d’un FIFO multi-éléments vides obtiennent chacun la dernière valeur qu’ils lisent dans le buffer ou la valeur par défaut pour le type de données de la variable s’ils n’ont pas lu la variable auparavant. Ce comportement est illustré ci-dessous.
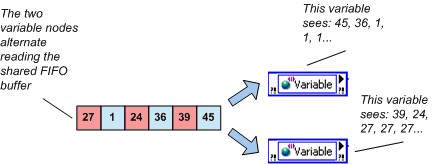
Figure 6. Comportement de dernière lecture et variable partagée FIFO Real-Time multi-éléments
Si une application nécessite que chaque lecteur reçoive chaque point de données écrit dans une variable partagée FIFO multi-éléments, utilisez une variable partagée distincte pour chaque lecteur.
Variable partagée publiée sur réseau
À l’aide de la variable partagée publiée sur réseau, vous pouvez écrire et lire à partir de variables partagées sur un réseau Ethernet. L’implémentation de la mise en réseau est entièrement gérée par la variable publiée sur réseau.
En plus de rendre vos données disponibles sur le réseau, la variable partagée publiée sur réseau ajoute de nombreuses fonctionnalités non disponibles avec la variable partagée à un processus. Pour fournir cette fonctionnalité supplémentaire, l’implémentation interne de la variable partagée publiée sur réseau est considérablement plus complexe que celle de la variable partagée à un processus. Les sections suivantes traitent des aspects de cette implémentation et proposent des recommandations pour obtenir les meilleures performances de variable partagée publiée sur réseau.
NI-PSP
Le protocole NI Publish and Subscribe (NI-PSP) est un protocole réseau optimisé pour être le transport des variables partagées réseau. Le protocole de niveau le plus bas sous NI-PSP est TCP/IP et il a été soigneusement réglé en vue des performances à la fois sur les systèmes bureau et les cibles RT de NI (voir ci-dessous pour obtenir les tests comparatifs).
Principes de fonctionnement de LogosXT
La Figure 7 illustre la pile logicielle de la variable partagée réseau. Il est important de comprendre cela, car la théorie du fonctionnement en jeu ici est particulière au niveau de la pile appelée LogosXT. LogosXT est la couche de la pile chargée d’optimiser le débit de la variable partagée.
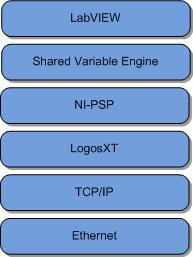
Figure 7. Pile réseau variable partagée
La Figure 8 montre les principaux composants de l’algorithme de transmission LogosXT. En substance, c’est très simple. Il y a deux acteurs importants :
- Un buffer de transmission de 8 kilo-octets (Ko)
- Un thread de temporisation de 10 millisecondes (ms)
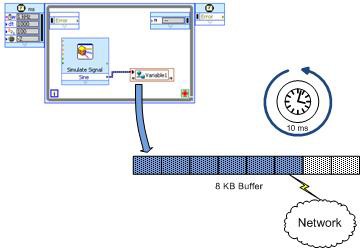
Figure 8. Acteurs LogosXT. Le buffer sera transmis s’il est plein ou après 10 ms.
Ces chiffres ont été obtenus en profilant soigneusement différentes tailles et durées de paquets pour optimiser le débit de données. L’algorithme est le suivant :
- SI le buffer de transmission est rempli à pleine capacité (8 Ko) avant le déclenchement du temporisateur de 10 ms, les données de ce buffer sont envoyées immédiatement à TCP sur le même thread qui a lancé l’écriture. Dans le cas de la variable partagée, le thread sera le thread du moteur de variable partagée.
- SI 10 ms s’écoulent sans que le buffer ne se remplisse jamais à pleine capacité, les données seront envoyées sur le thread du temporisateur.
Informations importantes : Il existe un buffer de transmission pour toutes les connexions entre deux extrémités distinctes. Autrement dit, toutes les variables représentant les connexions entre deux machines différentes partageront un buffer. Ne confondez pas ce buffer de transmission avec la propriété Bufférisation (Buffering) des variables partagées. Ce buffer de transmission est un buffer de très bas niveau qui multiplexe les variables en une seule connexion TCP et optimise le débit du réseau.
Il est important de comprendre la fonctionnalité de cette couche de la pile réseau, car elle a des effets secondaires sur le code de votre diagramme LabVIEW. L’algorithme attend 10 ms car il est toujours plus efficace que le débit envoie autant que possible en une seule opération d’envoi. Chaque opération de réseau a une surcharge fixe à la fois en temps et en taille de paquet. Si nous envoyons de nombreux petits paquets (que nous appelons N paquets) contenant un total de B octets, nous payons la surcharge du réseau N fois. Si, à la place, nous envoyons un gros paquet contenant B octets, nous ne payons la surcharge fixe qu’une seule fois et le débit global est beaucoup plus élevé.
Cet algorithme fonctionne très bien si vous voulez diffuser des données depuis ou vers une cible au débit le plus élevé possible. Si, d’autre part vous voulez envoyer de petits paquets de manière non fréquente, par exemple envoyer des commandes à une cible pour effectuer une opération telle que l’ouverture d’un relais (1 octet de données booléennes), mais vous voulez qu’il y arrive aussi rapidement que possible, alors vous devez optimiser ce que l’on appelle la latence.
S'il est plus important d'optimiser la latence dans votre application, vous devrez utiliser la fonction Flush Shared Variable Data.vi. Ce VI force les buffers de transmission dans LogosXT à être vidés via le moteur de variables partagées et à travers le réseau. Cela réduira considérablement la latence.
Remarque : Dans LabVIEW 8.5, il n'y avait pas de crochet pour forcer LogosXT à vider son buffer, et Vider les données des variables partagées.vi n'existait pas. Au lieu de cela, il était pratiquement garanti qu’il y aurait au moins 10 ms de latence dans le système pendant que le programme attendait que le buffer de transmission soit rempli avant de finalement chronométrer toutes les 10 ms et d’envoyer les données qu’il avait.
Cependant, comme indiqué ci-dessus, toutes les variables partagées connectant une machine à une autre machine partagent le même buffer de transmission, en appelant Vider les données des variables partagées (Flush Shared Variable Data), vous allez affecter de nombreuses variables partagées sur votre système. Si vous avez d’autres variables qui dépendent d’un débit élevé, vous les affecterez négativement en appelant Flush Shared Variable Data.vi (Figure 9).
Figure 9. Flush Shared Variable Data.vi
Déploiement et hébergement
Vous devez déployer des variables partagées publiées sur réseau vers un moteur de variables partagées (MVP) qui héberge les valeurs des variables partagées réseau. Lorsque vous écrivez sur un nœud Variable partagée, LabVIEW envoie la nouvelle valeur au MVP qui a déployé et héberge la variable. La boucle de traitement MVP publie ensuite la valeur afin que les adhérents obtiennent la valeur mise à jour. La Figure 10 illustre ce processus. Pour utiliser la terminologie client/serveur, le MVP est le serveur d’une variable partagée et toutes les références sont les clients, qu’ils écrivent ou lisent à partir de la variable. Le client MVP fait partie de l’implémentation de chaque nœud Variable partagée, et dans cet article, les termes client et adhérent sont interchangeables.
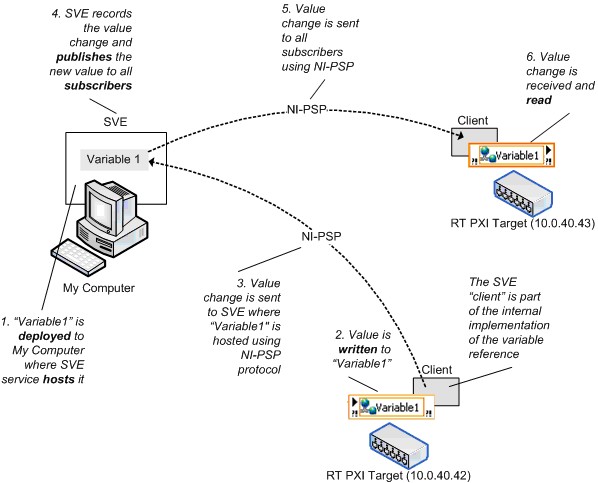
Figure 10. Moteur de variable partagée et modifications de la valeur de la variable partagée réseau
Variables publiées sur réseau et LabVIEW Real-Time
Vous pouvez activer les FIFO Real-Time avec une variable partagée publiée sur réseau, mais les variables partagées publiées sur réseau compatibles FIFO ont une différence de comportement importante par rapport aux variables partagées à un processus en temps réel, compatibles FIFO. Rappelez-vous qu’avec la variable partagée à un processus, tous les scripteurs et lecteurs partagent un FIFO Real-Time unique ; ce n’est pas le cas avec la variable partagée publiée sur réseau. Chaque lecteur d’une variable partagée publiée sur réseau obtient son propre FIFO Real-Time dans les cas à élément unique et multi-éléments, comme indiqué ci-dessous.
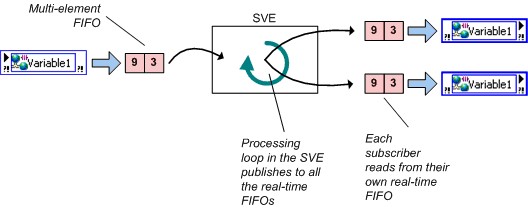
Figure 11. Variable publiée sur réseau compatible avec FIFO Real-Time
Bufférisation réseau
Vous pouvez utiliser la bufférisation avec la variable partagée publiée sur réseau. Vous pouvez configurer la bufférisation dans la boîte de dialogue Propriétés de la variable partagée (Shared Variable Properties), comme illustré en Figure 12.
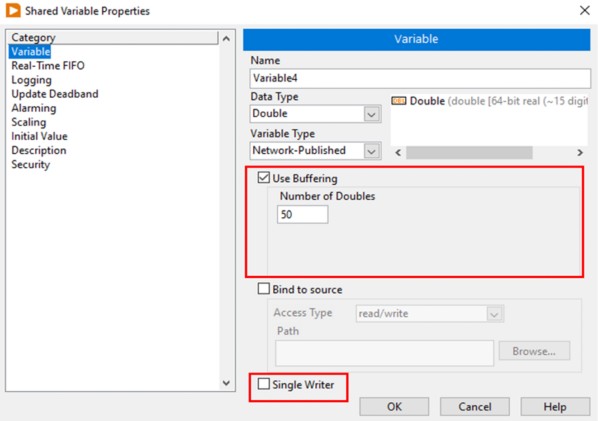
Figure 12. Activation de la bufférisation sur une variable partagée publiée sur réseau
Lorsque la bufférisation est activée, vous pouvez spécifier la taille du buffer en unités du type de données, dans ce cas, doubles.
Avec la bufférisation, vous pouvez tenir compte des fluctuations temporaires entre les taux de lecture/écriture d’une variable. Les lecteurs qui lisent parfois une variable plus lentement que le scripteur peuvent manquer certaines mises à jour. Si l’application peut parfois tolérer des points de données manquants, le taux de lecture plus lent n’affecte pas l’application et vous n’avez pas besoin d’activer la bufférisation tampon. Cependant, si le lecteur doit recevoir chaque mise à jour, activez la bufférisation. Vous pouvez définir la taille du buffer sur la page Variable de la boîte de dialogue Propriétés de la variable partagée (Shared Variable Properties), afin de pouvoir décider du nombre de mises à jour que l’application conserve avant de commencer à remplacer les anciennes données.
Lorsque vous configurez un buffer réseau dans la boîte de dialogue ci-dessus, vous configurez en fait la taille de deux buffers différents. Le buffer côté serveur, décrit comme buffer à l’intérieur de la zone intitulée Moteur de variables partagées (MVP) (Shared Variable Engine [SVE]) dans la Figure 13 ci-dessous, est automatiquement créé et configurée pour être de la même taille que le buffer côté client, plus sur ce buffer en une minute. Le buffer côté client est probablement celui auquel vous pensez logiquement lorsque vous configurez votre variable partagée pour que la bufférisation soit activée. Le buffer côté client (représenté sur le côté droit de la Figure 13) est le buffer chargé de maintenir la file d’attente des valeurs précédentes. C’est ce buffer qui isole vos variables partagées des fluctuations de la vitesse de la boucle ou du trafic réseau.
Contrairement à la variable à un processus en temps réel compatible FIFO pour laquelle tous les scripteurs et lecteurs partagent le même FIFO Real-Time, chaque lecteur d’une variable partagée publiée sur réseau obtient son propre buffer afin que les lecteurs n’interagissent pas entre eux.
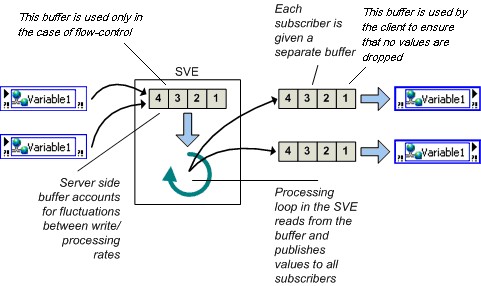
Figure 13. Bufférisation
La bufférisation n’est utile que dans les situations où les taux de lecture/écriture ont des fluctuations temporaires. Si l’application s’exécute pendant une période indéfinie, les lecteurs qui lisent toujours à un rythme plus lent qu’un scripteur perdent éventuellement des données, quelle que soit la taille du buffer que vous spécifiez. Étant donné que la bufférisation alloue un buffer pour chaque adhérent, pour éviter une utilisation inutile de la mémoire, utilisez la bufférisation uniquement lorsque cela est nécessaire.
Bufférisation réseau et temps réel
Si vous activez à la fois la bufférisation réseau et le FIFO Real-Time, l’implémentation de la variable partagée comprend à la fois un buffer réseau et un FIFO Real-Time. Rappelez-vous que si le FIFO Real-Time est activé, un nouveau FIFO Real-Time est créé pour chaque scripteur et lecteur, ce qui signifie que plusieurs scripteurs et lecteurs ne se bloqueront pas.
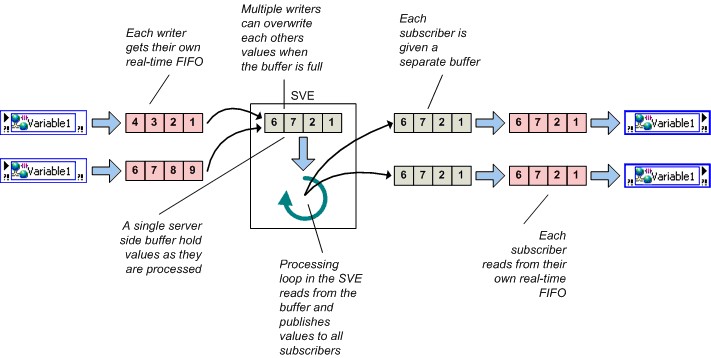
Figure 14. Bufférisation réseau et FIFO Real-Time
Bien que vous puissiez définir les tailles de ces deux buffers indépendamment, NI vous recommande dans la plupart des cas de conserver la même taille. Si vous activez le FIFO Real-Time, LabVIEW crée un nouveau FIFO Real-Time pour chaque scripteur et lecteur. Par conséquent, plusieurs scripteurs et lecteurs ne se bloquent pas.
Durée de vie du buffer
LabVIEW crée des buffers réseau et FIFO Real-Time lors d’une première écriture ou lecture, selon l’emplacement des buffers.
- Les buffers côté serveur sont créés lorsqu’un scripteur écrit pour la première fois dans une variable partagée.
- Les buffers côté client sont créés lorsqu’un abonnement est établi.
Ceux-ci sont créés lorsque le VI contenant le nœud Variable partagée démarre. Si un scripteur écrit des données dans une variable partagée avant qu’un lecteur donné ne s’abonne à cette variable, les valeurs de données initiales ne sont pas disponibles pour l’adhérent.
Remarque : Avant LabVIEW 8.6, les buffers étaient créés lors de la première exécution d’un nœud de lecture ou d’écriture de variable partagée.
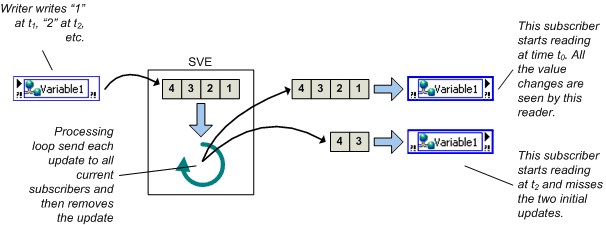
Figure 15. Durée de vie du buffer
Débordement/sous-flux du buffer
La variable partagée publiée sur réseau signale les conditions de débordement et de sous-flux du buffer réseau. Le FIFO Real-Time dans toutes les versions indiquera un débordement/sous-flux FIFO en renvoyant des erreurs.
Remarque : L'ancienne version de LabVIEW ne rapporte pas les conditions de dépassement ou de débordement négatif du buffer réseau. Une application dans LabVIEW 8.0 ou 8.0.1 peut vérifier les débordements de buffer réseau de deux manières. Étant donné que la résolution d’horodatage de la variable partagée est de 1 ms, vous pouvez comparer l’horodatage d’une variable partagée à l’horodatage de lecture suivant pour détecter les débordements du buffer lorsque vous mettez à jour la variable à moins de 1 kHz. Ou le lecteur peut utiliser un numéro de séquence regroupé avec les données pour remarquer les débordements/sous-flux du buffer. Vous ne pouvez pas utiliser la seconde approche avec des variables partagées utilisées dans une boucle à priorité critique si le type de données est un tableau, car les variables partagées compatibles FIFO Real-Time ne prennent pas en charge le type de données Commande personnalisée (cluster) si l’un des éléments du cluster est un tableau.
Durée de vie de la variable partagée
Comme mentionné précédemment, toutes les variables partagées font partie d’une bibliothèque de projet. Le MVP enregistre les bibliothèques de projet et les variables partagées que ces bibliothèques contiennent chaque fois que LabVIEW a besoin d’une de ces variables. Par défaut, le MVP déploie et publie une bibliothèque de variables partagées dès que vous exécutez un VI qui fait référence à l’une des variables contenues. Parce que le MVP déploie la bibliothèque entière qui possède une variable partagée, le MVP publie toutes les variables partagées dans la bibliothèque, qu’un VI en cours d’exécution les mette toutes en référence ou non. Vous pouvez déployer n’importe quelle bibliothèque de projet manuellement à tout moment en cliquant avec le bouton droit sur la bibliothèque dans la fenêtre Explorateur de projets (Project Explorer).
L’arrêt du VI ou le redémarrage de la machine qui héberge la variable partagée ne rend pas la variable indisponible pour le réseau. Si vous devez supprimer la variable partagée du réseau, vous devez explicitement annuler le déploiement de la bibliothèque dont la variable fait partie dans la fenêtre Explorateur de projets (Project Explorer). Vous pouvez également sélectionner Outils » Gestionnaire de systèmes distribués pour annuler le déploiement de variables partagées ou de bibliothèques de projets entières de variables.
Remarque : Les versions hérités de Labview utilisent le gestionnaire de variables ( Tools»Shared Variable»Variable Manager ) et non le Gestionnaire de systèmes distribués pour contrôler le déploiement de variables partagées.
Liaison des données de la face-avant
Une fonction supplémentaire disponible uniquement pour les variables partagées publiées sur réseau est la liaison de données de la face-avant. Faites glisser une variable partagée de la fenêtre de l’Explorateur de projet (Project Explorer) jusqu’à la face-avant d’un VI pour créer une commande liée à la variable partagée. Lorsque vous activez la liaison de données pour une commande, la modification de la valeur de la commande modifie la valeur de la variable partagée à laquelle la commande est liée. Durant l’exécution d’un VI, si la connexion au MVP se passe bien, un petit indicateur vert s’affiche à côté de l’objet de la face-avant du VI, comme illustré en Figure 16.

Figure 16. Liaison d’une commande de la face-avant à une variable partagée
Vous pouvez accéder et modifier la liaison de toute commande ou tout indicateur sur la page Liaison de données (Data Binding) de la boîte de dialogue Propriétés (Properties). Lorsque vous utilisez le module LabVIEW Real-Time ou le module LabVIEW DSC, vous pouvez sélectionner Outils » Variable partagée » Configuration en masse des liaisons à la face-avant (Tools » Shared Variable » Front Panel Binding Mass Configuration) pour afficher la boîte de dialogue Configuration en masse des liaisons à la face-avant (Front Panel Binding Mass Configuration) et créer une interface opérateur qui lie de nombreux indicateurs et commandes aux variables partagées.
NI ne recommande pas d’utiliser la liaison de données de la face-avant pour les applications qui s’exécutent sur LabVIEW Real-Time car la face-avant peut ne pas être présente.
Accès de programmation
Comme indiqué ci-dessus, vous pouvez créer, configurer et déployer des variables partagées de manière interactive à l’aide du projet LabVIEW, et vous pouvez lire et écrire dans des variables partagées à l’aide du nœud Variable partagée sur le diagramme ou via la liaison de données de la face-avant. Dans LabVIEW 2009 et versions ultérieures, vous disposez également d’un accès de programmation à toutes ces fonctionnalités.
Utilisez VI Serveur pour créer des bibliothèques de projets et des variables partagées de programmation dans des applications où vous devez créer un grand nombre de variables partagées. De plus, le module LabVIEW DSC fournit un ensemble complet de VIs pour créer et éditer des variables partagées et des bibliothèques de projets de programmation, ainsi que pour gérer le MVP. Vous pouvez créer des bibliothèques de variables partagées de programmation uniquement sur les systèmes Windows. Cependant, vous pouvez déployer ces nouvelles bibliothèques de programmation sur des systèmes Windows ou LabVIEW Real-Time.
Utilisez l’API Variable partagée de programmation dans les applications où vous devez modifier dynamiquement la variable partagée qu’un VI lit et écrit, ou lorsque vous devez lire et écrire un grand nombre de variables. Vous pouvez modifier une variable partagée dynamiquement en créant l’URL par programmation.
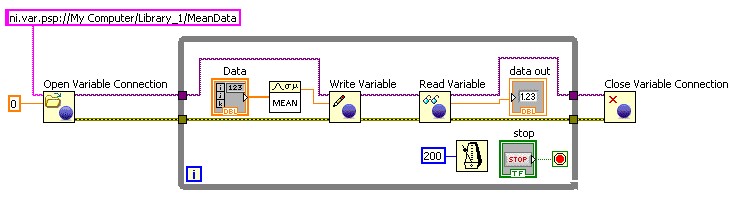
Figure 17. Utilisation de l’API Variable partagée de programmation pour lire et écrire des variables partagées
De plus, avec la bibliothèque de variables réseau introduite dans NI LabWindows/CVI 8.1 et NI Measurement Studio 8.1, vous pouvez lire et écrire dans des variables partagées en ANSI C, Visual Basic .NET ou Visual C#.
Le moteur de variables partagées
Le MVP est un framework logiciel qui permet à une variable partagée publiée sur réseau d’envoyer des valeurs via le réseau. Sous Windows, LabVIEW configure le MVP en tant que service et lance le MVP au démarrage du système. Sur une cible en temps réel, le MVP est un composant de démarrage installable qui se charge au démarrage du système.
Pour utiliser des variables partagées publiées sur réseau, un MVP doit être exécuté sur au moins un des nœuds du système distribué. N’importe quel nœud du réseau peut lire ou écrire sur des variables partagées que le MVP publie. Comme le montre le Tableau 1, les nœuds peuvent référencer une variable sans que le MVP soit installé. Vous pouvez également avoir plusieurs MVP installés sur plusieurs systèmes simultanément si vous devez déployer des variables partagées dans différents emplacements en fonction des exigences de l’application.
Recommandations pour l’emplacement d’hébergement de variables partagées
Vous devez prendre en compte un certain nombre de facteurs lorsque vous décidez à partir de quel périphérique de calcul déployer et héberger les variables partagées publiées sur réseau que vous utilisez dans un système distribué.
Le périphérique de calcul est-il compatible avec le MVP ?
Le Tableau suivant résume les plates-formes pour lesquelles le MVP est disponible et indique les plates-formes qui peuvent utiliser des variables partagées publiées sur réseau via des nœuds de référence ou l’API DataSocket. NI nécessite 32 Mo de RAM et recommande 64 Mo pour le MVP sur toutes les plates-formes applicables.
Notez que l’hébergement de variables partagées n’est toujours pas pris en charge sous Linux ni Macintosh.
L’application nécessite-t-elle des fonctions d’enregistrement de données et de supervision?
Si vous souhaitez utiliser les fonctionnalités du module LabVIEW DSC, vous devez héberger les variables partagées sous Windows. Le module LabVIEW DSC ajoute les fonctionnalités suivantes aux variables partagées publiées sur réseau :
· Enregistrement historique dans la base de données Citadel de NI.
· Alarmes en réseau et enregistrement des alarmes.
· Mise à l’échelle.
· Sécurité basée sur l’utilisateur.
· Valeur initiale.
· Possibilité de créer des serveurs d’E/S personnalisés.
· Intégration de la structure d’événements LabVIEW avec la variable partagée.
· VIs LabVIEW pour contrôler par programmation tous les aspects des variables partagées et le moteur de variables partagées. Ces VIs sont particulièrement utiles pour gérer un grand nombre de variables partagées.
Le périphérique de calcul dispose-t-il de ressources de processeur et de mémoire adéquates ?
Le MVP est un processus supplémentaire qui nécessite à la fois des ressources de traitement et de mémoire. Afin d’obtenir des performances optimales dans un système distribué, installez le MVP sur des machines disposant du maximum de mémoire et de capacités de traitement.
Quel système est toujours en ligne ?
Si vous créez une application distribuée dans laquelle certains des systèmes peuvent se déconnecter périodiquement, hébergez le MVP sur un système toujours en ligne.
Fonctionnalités supplémentaires du moteur de variables partagées
La Figure 18 illustre les nombreuses responsabilités du MVP. En plus de gérer les variables partagées publiées en réseau, le MVP est responsable de :
· Collecter les données reçues des serveurs d’E/S.
· Servir des données via les serveurs OPC et PSP aux adhérents.
· Fournir des services de mise à l’échelle, d’alarmes et d’enregistrement pour toute variable partagée avec ces services configurés. Ces services sont disponibles uniquement avec le module LabVIEW DSC.
· Surveiller les conditions d’alarme et les réponses en conséquence.
Serveurs d’E/S
Les serveurs d'E/S sont des plug-ins du moteur de variables partagées (MVP) qui permettent aux programmes de publier des données via le MVP. NI-DAQmx inclut un serveur d'E/S capable de publier automatiquement les voies virtuelles globales NI-DAQmx sur le MVP, remplaçant ainsi le serveur OPC DAQ traditionnel et l'accès à distance aux appareils (RDA). NI-DAQmx peut installer le MVP indépendamment, même si LabVIEW n'est pas installé.
Puisque le MVP agit comme un serveur OPC DA, la combinaison du MVP et du serveur d'E/S NI-DAQmx fonctionne comme un serveur OPC DA pour les données NI-DAQmx. Le LabVIEW OPC UA Toolkit est nécessaire pour la prise en charge d'OPC UA.
Avec le module LabVIEW DSC, les utilisateurs peuvent créer des serveurs d'E/S personnalisés pour des protocoles et des sources de données supplémentaires.
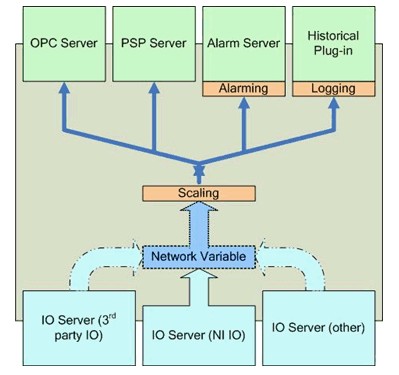
Figure 18. Moteur de variables partagées (MVP)
OPC
Le MVP est compatible avec la version 3.0 et peut agir comme un serveur OPC sur les machines Windows. Tout client OPC peut écrire ou lire à partir d’une variable partagée hébergée sur une machine Windows. Lorsque vous installez le module LabVIEW DSC sur une machine Windows, le MVP peut également agir comme un client OPC. Vous pouvez lier des variables partagées qu’une machine Windows héberge aux éléments de données OPC avec DSC et en écrivant ou en lisant la variable dans l’élément de données OPC.
Comme OPC est une technologie basée sur COM, une API Windows, les cibles en temps réel ne fonctionnent pas directement avec OPC. Comme le montre la Figure 19, vous pouvez toujours accéder aux éléments de données OPC à partir d’une cible en temps réel en hébergeant les variables partagées sur une machine Windows.
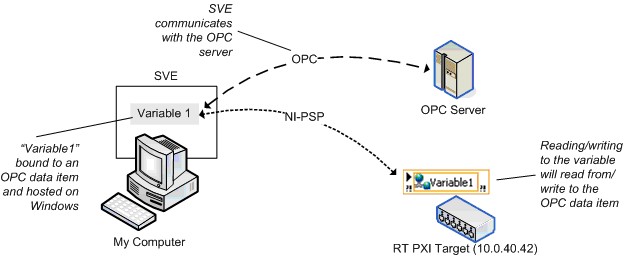
Figure 19. Liaison à un élément de données OPC
Performance
Cette section fournit des instructions générales pour la création d’applications hautes performances à l’aide de la variable partagée.
Étant donné que la variable partagée à un processus a une implémentation similaire aux variables globales LabVIEW et aux FIFO Real-Time, NI n’a pas de recommandations particulières pour obtenir de bonnes performances pour les variables partagées à un processus. Les sections suivantes se concentrent sur la variable partagée publiée sur réseau.
Partage du processeur
La variable partagée publiée sur réseau simplifie les diagrammes LabVIEW en masquant de nombreux détails d’implémentation de la programmation réseau. Les applications se composent de VIs LabVIEW ainsi que du MVP et du code client MVP. Afin d’obtenir les meilleures performances de variable partagée, développez l’application de sorte qu’elle abandonne régulièrement le processeur pour que les threads MVP s’exécutent. Une façon d’y parvenir consiste à placer des attentes dans les boucles de traitement et à s’assurer que l’application n’utilise pas de boucles non cadencées. La durée exacte que vous devez attendre dépend de l’application, du processeur et du réseau. Chaque application nécessite un certain niveau de réglage empirique afin d’obtenir les meilleures performances.
Considérations pour l’emplacement du MVP
La section Recommandations pour l’emplacement d’hébergement de variables partagées a abordé un certain nombre de facteurs que vous devez prendre en compte lorsque vous décidez où installer le MVP. La Figure 20 montre un autre facteur qui peut avoir un impact important sur les performances de la variable partagée. Cet exemple implique une cible en temps réel, mais les principes de base s’appliquent également aux systèmes en temps non réel. La Figure 20 montre une utilisation inefficace des variables partagées publiées sur réseau : vous générez des données sur une cible en temps réel et devez enregistrer les données traitées localement et les surveiller à partir d’une machine distante. Étant donné que les adhérents aux variables doivent recevoir des données du MVP, la latence entre l’écriture dans la boucle à priorité élevée et la lecture dans la boucle à priorité normale est importante et implique deux trajets sur le réseau.
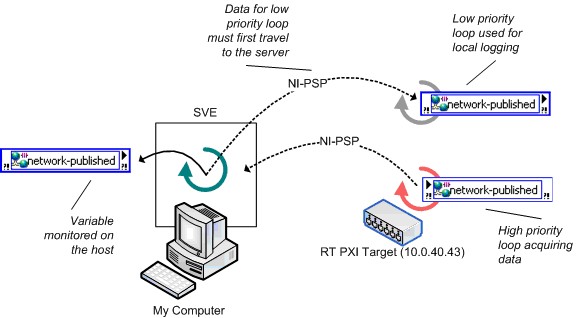
Figure 20. Utilisation inefficace des variables publiées sur réseau en temps réel
La Figure 21 montre une meilleure architecture pour cette application. L’application utilise une variable partagée à un processus pour transférer des données entre la boucle à priorité élevée et la boucle à faible priorité, ce qui réduit considérablement la latence. La boucle à faible priorité enregistre les données et écrit la mise à jour dans une variable partagée publiée sur réseau pour l’adhérent sur l’hôte.
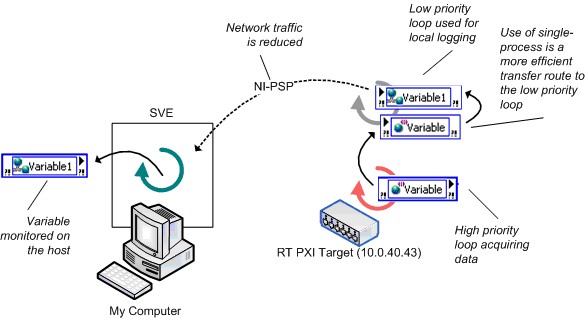
Figure 21. Utilisation efficace des variables publiées sur réseau en temps réel
Tests de performance
Cette section compare les performances de la variable partagée à d’autres méthodes de partage de données applicables dans LabVIEW, telles que la variable globale LabVIEW, les FIFO Real-Time et TCP/IP. Le tableau suivant résume les tests abordés présentés dans les sections suivantes.
Test | Description | Emplacement du MVP | Annotations |
|---|---|---|---|
T1 | Variable partagée à un processus versus variable globale | N/A | Établir des taux de lecture/écriture maximums. |
T2 | Variables partagées à un processus et FIFO Real-Timeversus Vis FIFO Real-Time | N/A | Établir des taux de lecture/écriture maximums lors de l’utilisation de FIFO Real-Time. Déterminer le taux durable le plus élevé auquel vous pouvez écrire sur une variable partagée ou un FIFO Real-Time dans une boucle cadencée et lire simultanément les données à partir d’une boucle à priorité normale. |
T3. | Variable partagée publiée sur réseau avec FIFO Real-Time versus FIFO Real-Time à 2 boucles avec TCP | PXI exécutant LV RT | Établir la fréquence maximale de données à point unique pouvant être diffusées sur le réseau. Variable partagée : le VI de lecture est toujours sur l’hôte.RT-FIFO + TCP : similaire au T2 avec l’ajout de communication TCP. /Mise en réseau IP. |
T4 | Encombrements de la variable partagée publiée sur réseau | Cible série RT | Établir l’utilisation de la mémoire des variables partagées après le déploiement. |
T5 | Comparaison entre les variables partagées publiées sur réseau 8.2 et les variables 8.5 – streaming | Cible série RT | Comparaison de la nouvelle implémentation 8.5 de NI-PSP à l’implémentation 8.20 et antérieure. Ce test de performance mesure le débit d’une application transférant en continu des données waveform d’un périphérique cRIO vers un hôte de bureau. |
T6 | Comparaison entre les variables partagées publiées sur réseau 8.2 et les variables 8.5 – grand nombre de voies | Cible série RT | Comparaison de la nouvelle implémentation 8.5 de NI-PSP à l’implémentation 8.20 et antérieure. Ce test de performance mesure le débit d’une application à grand nombre de voies sur un périphérique cRIO. |
Tableau 2. Présentation du test de performance
Les sections suivantes décrivent le code créé par NI pour chacun des tests de performance, suivi des résultats réels du test. La section Méthodologie et configuration décrit plus en détail la méthodologie choisie pour chaque test et la configuration détaillée utilisée pour le matériel et les logiciels sur lesquels le test a été exécuté.
Variable partagée à un processus versus Variables globales LabVIEW
La variable partagée à un processus est similaire à la variable globale LabVIEW. En fait, l’implémentation de la variable partagée à un processus est un LabVIEW global avec fonctionnalité d’horodatage ajoutée.
Pour comparer les performances de la variable partagée à un processus à la variable globale LabVIEW, NI a créé des VIs de test pour mesurer le nombre de fois que le VI peut lire et écrire dans une variable globale LabVIEW ou une variable partagée à un processus chaque seconde. La Figure 22 montre le test de lecture de variable partagée à un processus. Le test d’écriture de variable partagée à un processus et les tests de lecture/écriture globaux de LabVIEW suivent le même modèle.
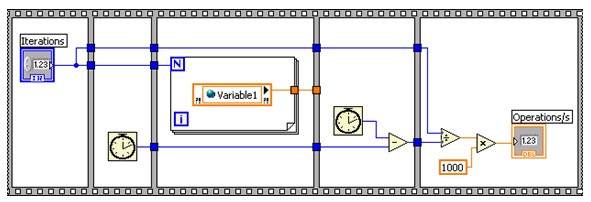
Figure 22. VI de test de lecture de variable partagée à un processus
Le test de lecture/écriture combiné comprend également du code pour valider que chaque point écrit peut également être lu dans la même itération de la boucle sans corruption de données.
Résultats du test T1
La Figure 23 montre les résultats du test T1. Les résultats montrent que les performances de lecture d’une variable partagée à un processus sont inférieures aux performances de lecture d’une variable globale LabVIEW. Les performances d’écriture, et donc les performances de lecture/écriture, de la variable partagée à un processus sont légèrement inférieures à celles de la variable globale LabVIEW. Les performances des variables partagées à un processus seront affectées par l’activation et la désactivation de la fonctionnalité d’horodatage, il est donc recommandé de désactiver l’horodatage s’il n’est pas utile.
La section Méthodologie et configuration explique la méthodologie de benchmarking spécifique et les détails de configuration de cet ensemble de tests.
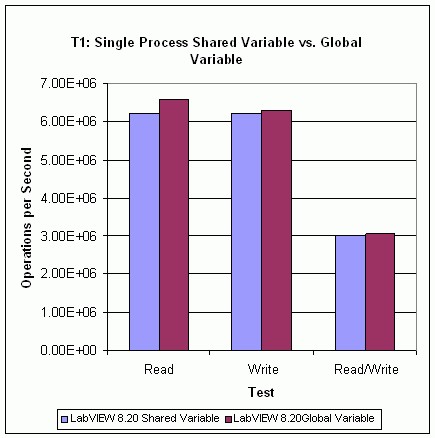
Figure 23. Performances de variables partagées à un processus versus performances de variables globales
Variable partagée à un processus versus FIFO Real-Time
NI a évalué le débit durable pour comparer les performances de la variable partagée à un processus compatible FIFO aux VIs FIFO Real-Time traditionnels. Le test examine également l’effet de la taille des données transférées, ou charge utile, pour chacune des deux implémentations FIFO Real-Time.
Les tests consistent en une boucle à priorité critique (TCL) générant des données et une boucle à priorité normale (NPL) consommant les données. NI a déterminé l’effet de la taille de la charge utile en parcourant une gamme de types de données scalaires et du tableau à double précision. Le type scalaire détermine le débit lorsque la charge utile est un double et les types de tableaux déterminent le débit pour le reste des charges utiles. Le test enregistre le débit durable maximal en déterminant la vitesse durable maximale à laquelle vous pouvez exécuter les deux boucles sans perte de données.
La Figure 24 montre un diagramme simplifié du test FIFO Real-Time qui omet une grande partie du code nécessaire pour créer et détruire les FIFO. Notez que depuis LabVIEW 8.20, une nouvelle fonction FIFO a été introduite pour remplacer les sous-VIs FIFO illustrés ici. Les fonctions FIFO ont été utilisées pour les données présentées dans ce document et fonctionnent mieux que leurs prédécesseurs sous-VI 8.0.x.
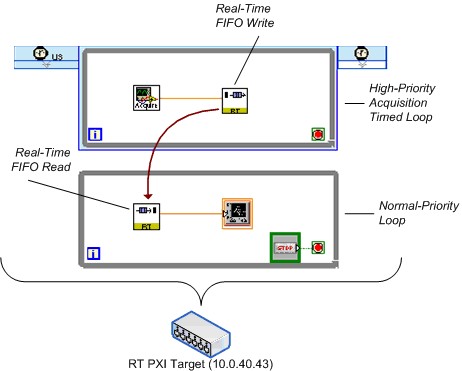
Figure 24. VI de benchmarking FIFO Real-Time simplifié
Une version équivalente du test utilise la variable partagée à un processus. La Figure 25 montre une représentation simplifiée de ce diagramme.
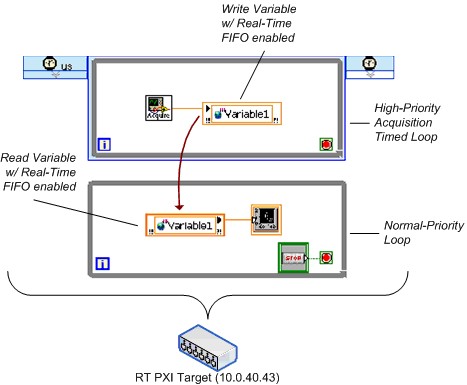
Figure 25. VI de benchmarking de variables partagées à un processus compatible FIFO simplifié
Résultats du test T2
Les Figures 26 et 27 montrent les résultats du test T2, comparant les performances de la variable partagée à un processus compatible FIFO aux fonctions FIFO Real-Time. Les résultats indiquent que l’utilisation de la variable partagée à un processus est légèrement plus lente que l’utilisation des FIFO Real-Time.
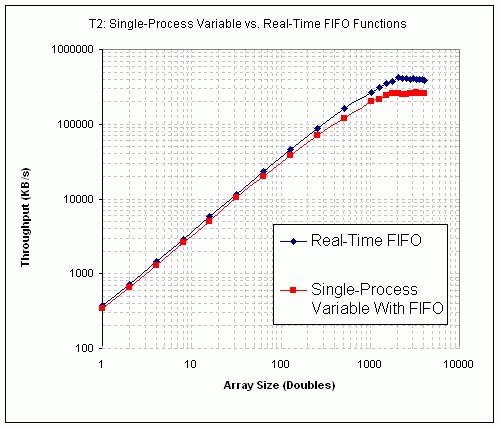
Figure 26. Performances de variables partagées à un processus versus performances VI FIFO Real-Time (PXI)
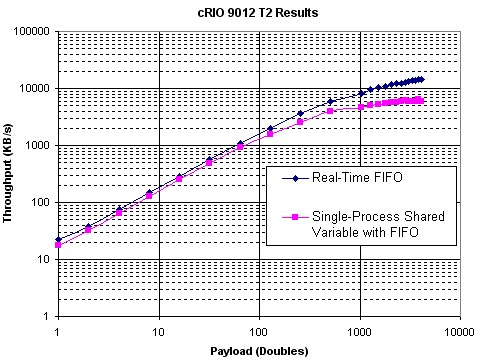
Figure 27. Performances de variables partagées à un processus versus Performances VI FIFO Real-Time (cRIO 9012)
Variables partagées publiées sur réseau versus FIFO Real-Time et TCP/IP
Grâce à la flexibilité de la variable partagée, vous pouvez publier une variable partagée à un processus rapidement sur le réseau avec seulement quelques modifications de configuration. Pour les applications en temps réel en particulier, effectuer la même transformation dans les versions antérieures de LabVIEW nécessite l’introduction d’une grande quantité de code pour lire les FIFO Real-Time sur le contrôleur de la série RT, puis envoyer les données sur le réseau à l’aide de l’un des nombreux protocoles de mise en réseau disponibles. Pour comparer les performances de ces deux approches différentes, NI a de nouveau créé des VIs de test pour mesurer le débit durable de chacune sans perte de données sur une gamme de charges utiles.
Pour l’approche « prévariable », le VI de test utilise des FIFO Real-Time et TCP/IP. Un TCL génère des données et les place dans un FIFO Real-Time ; un NPL lit les données du FIFO et les envoie sur le réseau en utilisant TCP/IP. Un PC hôte reçoit les données et valide qu’aucune perte de données ne se produit.
La Figure 28 montre un diagramme simplifié du test FIFO Real-Time et TCP/IP. Encore une fois, ce diagramme simplifie considérablement le VI de test réel.
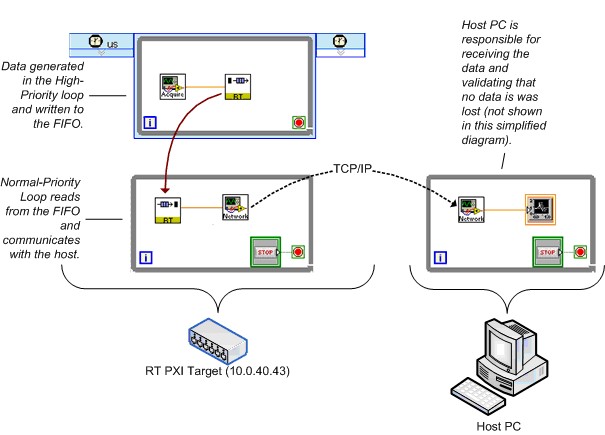
Figure 28 : VI de benchmarking FIFO Real-Time et TCP/IP simplifié
NI a créé une version équivalente du test en utilisant la variable partagée publiée sur réseau. La Figure 29 montre un diagramme simplifié.
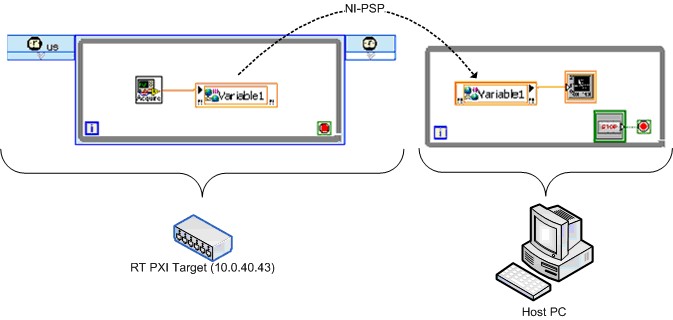
Figure 29. VI de benchmarking de la variable partagée publiée sur réseau compatible FIFO Real-Time simplifié
Résultats du test T3
Cette section contient les résultats du test T3, comparant les performances de la variable partagée publiée sur réseau compatible FIFO Real-Time à celle d’un code équivalent reposant sur des VIs FIFO Real-Time et des primitives LabVIEW TCP/IP. La Figure 30 montre les résultats lorsque la cible LabVIEW Real-Time est un contrôleur PXI série RT intégré.
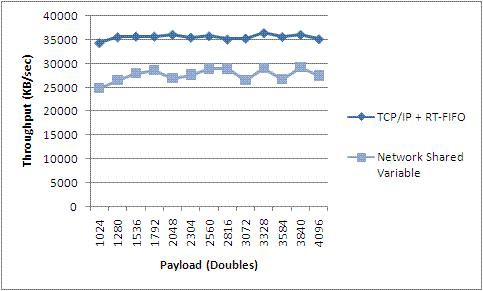
Figure 30. Performances de la variable partagée publiée sur réseau versus Performances VI FIFO Real-Time et TCP (PXI)
Les résultats T3 indiquent que le débit des variables partagées publiées sur réseau approche celui du TCP et que les deux sont cohérents sur des tailles de charge utile modérées à grandes. La variable partagée facilite votre travail de programmation, mais cela ne va pas sans coût. Il convient de noter, cependant, que si une implémentation TCP naïve est utilisée, il pourrait être facile de sous-performer les variables partagées, en particulier avec la nouvelle implémentation 8.5 de NI-PSP.
Résultats du test T4
Encombrement de la mémoire de la variable partagée publiée sur réseau
Veuillez noter qu’aucune modification significative de l’encombrement de la variable n’a été apportée dans LabVIEW 8.5. Par conséquent, ce test n’a pas été réexécuté.
Il est difficile de déterminer l’encombrement de la mémoire de la variable partagée, car la mémoire utilisée par la variable partagée dépend de la configuration. Les variables partagées publiées sur réseau avec bufférisation, par exemple, allouent la mémoire de manière dynamique selon les besoins du programme. La configuration d’une variable partagée pour utiliser des FIFO Real-Time augmente également l’utilisation de la mémoire, car en plus des buffers réseau, LabVIEW crée des buffers pour le FIFO. Par conséquent, les résultats du test dans cet article ne fournissent qu’une mesure de base de la mémoire.
La Figure 31 montre la mémoire que le MVP utilise après que LabVIEW y ait déployé 500 et 1 000 variables partagées des types spécifiés. Le graphique montre que le type de variable n’affecte pas significativement l’utilisation de la mémoire des variables partagées déployées. Veuillez noter qu’il s’agit de variables non bufférisées.
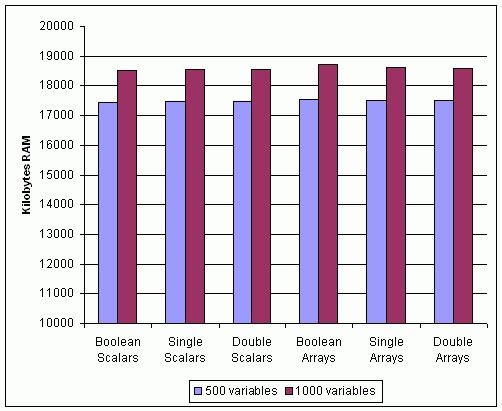
Figure 31. Utilisation de la mémoire des variables partagées publiées sur réseau avec différents types de données
La Figure 32 montre l’utilisation de la mémoire en fonction du nombre de variables partagées déployées. Ce test utilise un seul type de variable, un tableau booléen vide. L’utilisation de la mémoire augmente linéairement avec le nombre de variables.
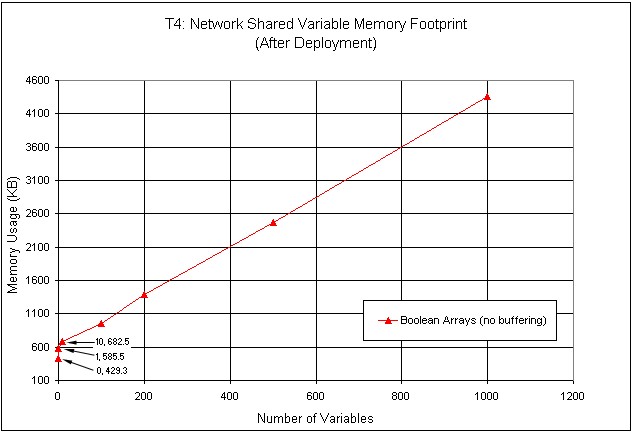
Figure 32. Utilisation de la mémoire de variables partagées de différentes tailles
Résultats du test T5
Comparaison entre les variables partagées publiées sur réseau 8.2 et les variables 8.5 – streaming
Dans LabVIEW 8.5, nous avons réimplémenté la couche inférieure du protocole réseau utilisé pour transporter des données variables partagées. Elle offre des performances nettement meilleures.
Dans ce cas, nous avons hébergé une seule variable de type Waveform des doubles sur un cRIO 9012. Nous avons généré toutes les données, puis en boucle serrée, nous avons transféré les données à l’hôte qui les a lues à partir d’un autre nœud Variable partagée waveform aussi vite que possible.
Vous pouvez voir sur la Figure 30 que les performances se sont améliorées dans LabVIEW 8.5 de plus de 600 % pour ce cas d’utilisation.
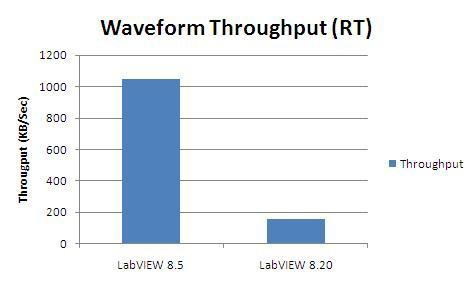
Figure 33. Comparaison du débit des waveforms entre LabVIEW 8.5 et LabVIEW 8.20 (et versions antérieures)
Résultats du test T6
Comparaison entre les variables partagées publiées sur réseau 8.2 et les variables 8.5 – streaming
Dans ce test, nous avons utilisé les deux mêmes cibles que dans le test T5, mais au lieu de transférer une seule variable, nous avons changé le type de données en double et varié le nombre de variables partagées de 1 à 1 000, tout en mesurant le débit au cours de la procédure. Encore une fois, toutes les variables étaient hébergées sur le cRIO 9012, des données d’incrémentation y étaient également générées et transmises à l’hôte où elles étaient lues.
La Figure 34 montre à nouveau une augmentation significative des performances de LabVIEW 8.20 à LabVIEW 8.5. Cependant, le débit est nettement inférieur dans le cas de nombreuses variables plus petites que pour une seule grande variable comme dans le test T5. Cela est dû au fait que chaque variable est associée à une quantité fixe de temps système. Lorsque de nombreuses variables sont utilisées, ce temps système est multiplié par le nombre de variables et devient tout à fait perceptible.
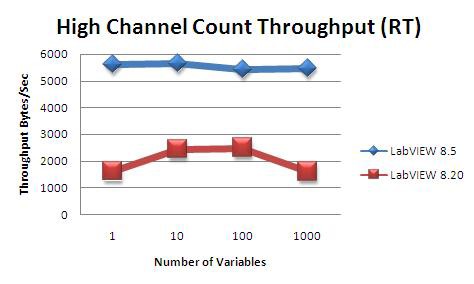
Figure 34. Comparaison du débit d’un grand nombre de voies entre LabVIEW 8.5 et LabVIEW 8.20 (et versions antérieures)
Méthodologie et configuration
Cette section fournit des informations détaillées concernant le processus de benchmarking pour tous les ensembles de tests mentionnés précédemment.
Méthodologie et considérations pour T1
Le test T1 utilise un modèle de benchmarking simple pour déterminer les taux de lecture et d’écriture grâce à un moyennage simple sur un grand nombre d’itérations. Chaque test a exécuté un total de 500 millions d’itérations pour des temps d’exécution totaux de l’ordre d’une minute, synchronisées avec une résolution en millisecondes.
Configuration logicielle/matérielle pour T1
Matériel hôte
- Dell Precision 450
- Processeurs Dual Intel Xeon 2,4 GHz de classe Pentium
- 1 Go de DRAM
Logiciel hôte
- Windows XP SP2
- LabVIEW 8.20
Méthodologie et considérations pour T2
Le test T2 mesure le débit en indiquant le débit de communication durable maximal entre les tâches exécutées selon différentes priorités. Une boucle cadencée exécutée avec une résolution en microsecondes contient le producteur de données. Le consommateur des données est une boucle libre, de priorité normale, qui lit depuis le FIFO Real-Time ou la variable partagée à un processus jusqu’à ce qu’elle soit vide, répétant ce processus jusqu’à ce qu’un certain laps de temps s’écoule sans erreurs. Le résultat du test n’est valide que si toutes les affirmations suivantes sont vraies :
- Aucun débordement du buffer
- L’intégrité des données est préservée : aucune perte de données ne s’est produite et le consommateur reçoit les données dans l’ordre où elles ont été envoyées
- La boucle cadencée est capable de suivre le rythme après une période de préchauffage spécifiée de 1 s
La boucle réceptrice de la variable partagée à un processus effectue des vérifications d’intégrité des données simples, telles que la garantie que le nombre attendu de points de données a été reçu et que le modèle de message reçu ne manque pas de valeurs intermédiaires.
NI a configuré les tailles du buffer pour que les buffers FIFO Real-Time et FIFO à variable partagée soient à 100 éléments de profondeur pour toutes les variations de test et les types de données impliqués.
Configuration logicielle/matérielle pour T2
Matériel PXI
- Contrôleur NI série PXI-8196 RT
- Processeur 2,0 GHz de classe Pentium
- 256 Mo de DRAM
- Broadcom 57xx (adaptateur Ethernet intégré 1 Go/s)
Logiciel PXI
- Module LabVIEW 8.20 Real-Time
- Moteur de variables réseau 1.2.0
- Support client variable 1.2.0
- Driver Broadcom 57xx Go Ethernet 2.1 configuré en mode d’interrogation
Matériel CompactRIO
- Contrôleur NI cRIO 9012
- Processeur de 400 MHz
- 64 Mo de DRAM
Logiciel CompactRIO
- Module LabVIEW 8.20 Real-Time
- Moteur de variables réseau 1.2.0
- Support client variable 1.2.0
Méthodologie et considérations pour T3
Le test T3 mesure directement le débit en enregistrant la quantité de données transmises sur le réseau et la durée globale du test. Une boucle cadencée exécutée avec une résolution en microsecondes contient le producteur de données, qui est responsable de l’écriture d’un modèle de données spécifique dans les VIs FIFO Real-Time ou variable partagée publiée sur réseau.
Pour le cas des variables partagées publiées sur réseau, un NPL s’exécute sur le système hôte et lit à partir de la variable dans une boucle While qui s’exécute librement. Pour le test VI FIFO Real-Time, le NPL s’exécute sur le système en temps réel, vérifiant l’état du FIFO à un débit donné, lisant toutes les données disponibles et les envoyant sur le réseau à l’aide de TCP. Les résultats du test montrent l’effet d’avoir cette période d’interrogation définie sur 1 ou 10 ms.
Le résultat du test n’est valide que si toutes les affirmations suivantes sont vraies :
- Aucun débordement de buffer ne se produit, ni FIFO ni réseau
- L’intégrité des données est préservée : aucune perte de données ne s’est produite et le consommateur reçoit les données dans l’ordre où elles ont été envoyées
- La boucle cadencée dans le VI TCL est capable de suivre le rythme après une période de préchauffage spécifiée de 1 s
Après avoir lu chaque point de données, le NPL pour le test de variable réseau vérifie l’exactitude du modèle de données. Pour le test FIFO Real-Time, le TCL est responsable de la validation en fonction du débordement FIFO Real-Time.
Pour éviter la perte de données, NI a configuré les tailles du buffer pour qu’elles ne soient pas inférieures au rapport entre les périodes de boucle NPL et TCL, avec une limite inférieure de 100 éléments comme taille minimale pour les buffers FIFO Real-Time.
Configuration logicielle/matérielle pour T3
Matériel hôte
- Intel Core 2 Duo 1,8 GHz
- 2 Go de DRAM
- Intel PRO/1000 (adaptateur Ethernet 1 Go/s)
Logiciel hôte
- Windows Vista 64
- LabVIEW 8
Configuration réseau
Réseau commuté 1 Go/s
Matériel PXI
- Contrôleur NI PXI-8196 RT
- Processeur 2,0 GHz de classe Pentium
- 256 Mo de DRAM
- Broadcom 57xx (adaptateur Ethernet intégré 1 Go/s)
Logiciel PXI
- Module LabVIEW 8.5 Real-Time
- Moteur de variables réseau 1.2.0
- Support client variable 1.2.0
- Driver Broadcom 57xx Go Ethernet 2.1
Méthodologie et considérations pour T4
Dans le test T4, NI a utilisé des variables partagées non bufférisées publiées sur réseau avec les types de données suivants : double, simple, booléen, double tableau, tableau unique et tableau booléen.
Configuration logicielle/matérielle pour T4
Matériel PXI
- Contrôleur NI PXI-8196 RT
- Processeur 2,0 GHz de classe Pentium
- 256 Mo de DRAM
- Broadcom 57xx (adaptateur Ethernet intégré 1 Go/s)
Logiciel PXI
- Module LabVIEW Real-Time 8.0
- Moteur de variables réseau 1.0.0
- Support client variable 1.0.0
- Driver Broadcom 57xx Go Ethernet 1.0.1.3.0
Méthodologie et considérations pour T5 et T6
Dans les tests T5 et T6, NI a utilisé des variables partagées non bufférisées publiées sur réseau du type de données Waveform de doubles.
Configuration logicielle/matérielle pour T5 et T6
Matériel hôte
- Intel Core 2 Duo 1,8 GHz 64 bits
- 2 Go de RAM
- Ethernet Gigabit
Logiciel hôte
- Windows Vista 64
- LabVIEW 8.20 et LabVIEW 8.5
Matériel CompactRIO
- cRIO 9012
- 64 Mo de RAM
Logiciel CompactRIO
- LabVIEW RT 8.20 et LabVIEW RT 8.5
- Moteur de variables réseau 1.2 (avec LabVIEW 8.20) et 1.4 (avec LabVIEW 8.5)
- Support client variable 1.0 (avec LabVIEW 8.20) et 1.4 (avec LabVIEW 8.5)
| PC Windows | Mac OS | Linux | PXI Real-Time | CompactRIO | PC commerciaux avec LabVIEW Real-Time ETS | Système Compact Vision | Compact FieldPoint | |
|---|---|---|---|---|---|---|---|---|
| SVE | — | — | ||||||
| Nœuds de référence | — | — | ||||||
| API DataSocket avec PSP |