Stratégies de programmation pour le traitement multicœur : Parallélisme des tâches

Contenu
- Parallélisme des tâches
- Parallélisme des tâches dans LabVIEW
- Exemple d’application du parallélisme des tâches
- Ressources supplémentaires sur la programmation multicœur
Jusqu’à récemment, les progrès du matériel informatique ont permis d’augmenter considérablement la vitesse d’exécution des logiciels, sans grand effort de la part des développeurs de logiciels. Cette augmentation de la vitesse des processeurs s’est traduite par une accélération instantanée de la vitesse d’exécution des logiciels. La situation commence toutefois à évoluer, car la vitesse des processeurs atteint désormais des sommets et les fabricants de processeurs utilisent de nouvelles techniques pour augmenter la puissance de traitement. L’introduction des processeurs multicœurs constitue un nouveau défi pour les développeurs de logiciels, qui doivent désormais maîtriser les techniques de programmation nécessaires pour tirer parti du potentiel de traitement multicœur. Le parallélisme des tâches compte parmi ces techniques de programmation.
Parallélisme des tâches
Le parallélisme des tâches consiste simplement en l’exécution simultanée de tâches indépendantes dans un logiciel. Prenons l’exemple d’un processeur à cœur unique qui exécute simultanément un navigateur web et un programme de traitement de texte. Bien que ces applications s’exécutent sur des threads distincts, elles partagent en fin de compte le même processeur. Passons maintenant à un deuxième scénario dans lequel les deux mêmes programmes s’exécutent sur un processeur double cœur. Ces deux applications peuvent fonctionner indépendamment l’une de l’autre sur la machine double cœur. Bien qu’elles partagent certaines ressources qui les empêchent de fonctionner de manière totalement indépendante, la machine double cœur peut gérer les deux tâches parallèles de manière plus efficace.
Le parallélisme inhérent à la programmation par flux de données fait de l’environnement de développement graphique LabVIEW de National Instruments le langage de programmation idéal pour utiliser les techniques de programmation parallèle. Les langages textuels traditionnels présentent une syntaxe séquentielle et sont donc difficiles à visualiser et à organiser sous une forme parallèle. En revanche, la création d’une application multithread est intuitive et simple dans NI LabVIEW.
Parallélisme des tâches dans LabVIEW
Le paradigme de programmation graphique LabVIEW facilite la programmation parallèle, même pour les utilisateurs novices. Deux tâches distinctes qui ne dépendent pas l’une de l’autre pour les données s’exécutent en parallèle sans nécessiter de programmation supplémentaire.
La Figure 1 présente une routine simple d’acquisition de données. La section supérieure du code consiste en une tâche d’entrée de tension analogique et le code inférieur est une tâche de sortie numérique.
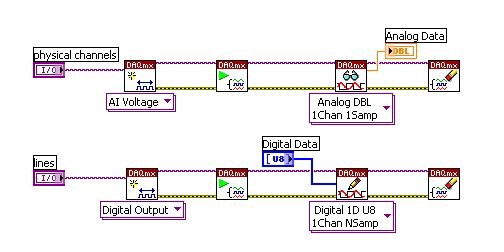
Figure 1 : Dans LabVIEW, deux sections de code sans dépendances de données s’exécutent indépendamment en parallèle.
Ces deux tâches indépendantes d’acquisition de données doivent partager le même processeur dans un scénario monocœur. Sur un processeur multicœur, chaque thread peut s’exécuter sur son propre processeur, ce qui améliore considérablement la vitesse d’exécution.
Lorsque l’on utilise le parallélisme des données dans une application, il est important de s’assurer que les deux tâches n’ont pas de ressources partagées qui pourraient créer un goulot d’étranglement, comme dans le code de la Figure 2.
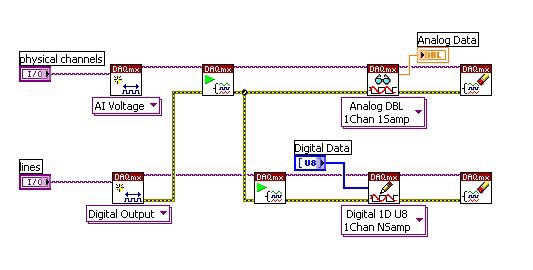
Figure 2 : Si une tâche dépend d’une autre pour les données, les deux tâches ne peuvent pas fonctionner indépendamment.
Dans ce programme, les deux tâches partagent des données ; la tâche numérique est obligée d’attendre que la tâche analogique ait commencé. Bien que ce code semble être parallèle, il ne l’est pas vraiment, car les deux tâches partagent des données. Il est important d’être conscient de cette subtilité lors de la programmation d’applications utilisant le parallélisme des tâches.
Exemple d’application du parallélisme des tâches
Chez Eaton Corporation, une équipe de développeurs, dont la seule mission est d’affiner les systèmes de test et de mesure utilisés dans la division R&D des camions d’Eaton, a exploité les performances du traitement multicœur et l’architecture multithread de LabVIEW en vue de quadrupler (et plus) le nombre de voies fonctionnant dans les systèmes d’Eaton et atteindre un déterminisme en temps réel. Cette application LabVIEW comprend trois boucles asynchrones effectuant les tâches parallèles d’acquisition, de contrôle des tests et d’interface utilisateur. Avant de mettre en œuvre cette solution, l’équipe ne pouvait répondre à ses exigences de test qu’en divisant la charge de travail de manière séquentielle ou en utilisant plusieurs ordinateurs de bureau monocœur afin d’exécuter l’application. En utilisant des ordinateurs de bureau standard et prêts à l’emploi, elle a pu minimiser la consommation d’énergie, la puissance thermique et la durée des tests, et donc réduire les coûts globaux.
Grâce au parallélisme des tâches et à d’autres techniques de programmation, les développeurs de logiciels peuvent tirer pleinement parti de la puissance offerte par le traitement multicœur. Les développeurs qui connaissent et comprennent ces techniques sont en mesure de préparer des applications pour les futures tendances informatiques. La nature parallèle inhérente à l’environnement de programmation graphique LabVIEW leur permet de créer efficacement les applications de demain.