RT Target Performance Benchmarks for Network Published Shared Variables
Overview
Contents
Introduction
Network-published shared variables transfer single-point data over a network and are effective in a wide variety of application spaces such as embedded controls and monitoring. Shared variables use a service called the Shared Variable Engine (SVE) to implement the NI Publish-Subscribe Protocol, which manages the transfer of shared variable data between writers and subscribers. For more detailed information on NI-PSP and the shared variable architecture, see the Using the LabVIEW Shared Variable whitepaper.
Before architecting a distributed real-time application that uses network-published shared variables, it is important to understand which RT targets are suitable for the desired usage. Network communication can be a processor intensive task, particularly when sending and receiving large quantities of data at high rates. CPU time is a limited resource that is highly dependent on hardware specifications. In an application that uses shared variables, both the thread running the SVE and the thread(s) accessing the shared variables require processor time. It is recommended to carefully budget CPU time in real-time applications to avoid overloading the processor, which may result in poor performance or application crashes.
The data presented in this document is intended to serve as a guide for making informed decisions related to application architecture and scalability when using network-published shared variables on RT targets. Performance will vary in each application depending on several factors that will be discussed throughout this document.
Test Methodology
National Instruments designed a benchmarking utility that captures performance profiles for RT targets while they run a lightweight, object-oriented application designed to access large quantities of shared variables at high rates. The following figure highlights the architecture of the benchmarking utility. The main components are a test supervisor application that runs on the Windows host computer and Device Under Test (DUT) application that runs on the RT target.
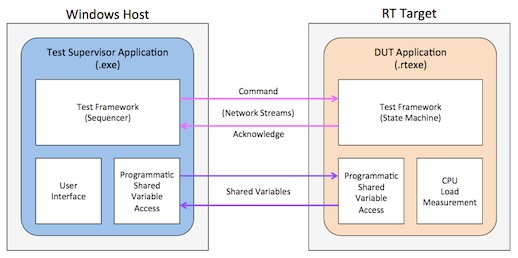
Test Supervisor Application
A Windows PC is responsible for supervising and coordinating the benchmarking of the DUT. The primary responsibilities of the test supervisor application include:
- Configuring the DUT for testing
- Managing deployment of shared variables
- Issuing commands to the DUT application
- Acting as a shared variable accessor during a benchmark
- Receiving, analyzing and logging data from the DUT application
DUT Application
The DUT application runs on any RT target. The application is a lightweight, object-oriented and utilizes a state machine architecture. The primary responsibilities of the DUT application include:
- Waiting for and executing instructions sent by the test supervisor
- Hosting shared variables
- Programmatically opening, writing and closing shared variables
- Acquiring CPU performance data during a benchmark
- Sending data back to test supervisor
The benchmarking utility generates a performance profile by executing a series of tests that sweep across a range of shared variable quantities and update frequencies. During each test, the DUT writes to shared variables hosted locally while the test supervisor access those shared variables at the same frequency. While the shared variable communication is executing, a parallel thread in the DUT application collects CPU usage information using the NI System Configuration API.
Summary of Test Conditions
These tests were executed in a controlled environment which used the following conditions across all tests:
- Private Gigabit Network
Benchmark data was executed with the test supervisor and DUT on a gigabit LAN with zero non-test traffic. - Lightweight DUT Application
To obtain performance profiles that accurately describe how shared variables affect performance, a lightweight DUT application was designed to minimize processor utilization from any functions other than shared variable access. - Maximum Library Size
Though several thousand variables were deployed in some tests, the maximum library size was limited to 500 variables. It is good programming practice to separate large numbers of shared variable into multiple libraries. - Double-Precision Floating-Point Data Type
All benchmarking tests were executed using shared variables of the largest non-custom data type native to LabVIEW. - Single Shared Variable Accessor
Only a single client application accessed shared variables hosted on the target. - Access via LabVIEW Shared Variable API
Both the DUT application and test supervisor application accessed the shared variables using the LabVIEW Shared Variable API.
Results
National Instruments ran the benchmark utility on several RT targets within the CompactRIO and PXI product lines, including value, mainstream and high-performance targets. The benchmarking utility builds a performance profile which relates CPU Load to the number of shared variable updates per second.
Shared Variable Updates per Second = # of Shared Variables * Update Rate (Hz)
The relationship between CPU load and shared variable updates per second are shown for each target in the following figures.
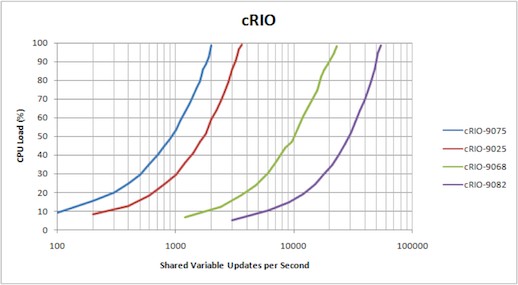
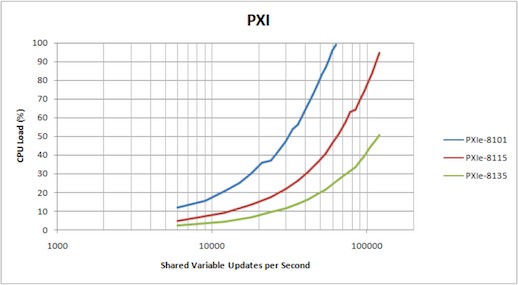
The data is presented on a logarithmic plot in order to effectively compare RT targets against one another. Upon further analysis, it is evident that CPU performance is linearly dependent on the number of shared variable updates per second where the slope of the linear relationship is highly dependent on the processor of the DUT. RT targets with faster clocked processors or multiple cores can achieve a greater number of updates per second while consuming less CPU time. The relationship can be described by the following equation.
CPU Load (%) = Shared Variable Updates per Second * Hardware Constant
Hardware constant represents the CPU Load for a single shared variable update and is specific to each target. The hardware constants for each target tested can be found in the table below.
| Target | Hardware Constant |
|---|---|
| cRIO-9075 | 5.704E-02 |
| cRIO-9025 | 2.949E-02 |
| cRIO-9068 | 4.915E-03 |
| cRIO-9082 | 1.718E-03 |
| PXIe-8101 | 1.644E-03 |
| PXIe-8115 | 7.670E-04 |
| PXIe-8135 | 4.003E-04 |
Conclusions
The load on an RT targets CPU due to shared variable access can be reasonably estimated using the equations provided in the results section. You can use the data in this document to make informed design decisions when architecting a system that relies on shared variables. However, expectations for performance should be adjusted based on several application specific factors, which is why you should execute application-specific benchmarks to determine if shared variables meet your use case.
Factors that will affect performance include, but are not limited to:
- Network Traffic
The data presented in this document was obtained from RT targets on a controlled private gigabit network. Expect a decrease in performance if targets are located on a busy network. - Application Size & Function
The DUT application used in these tests was designed to use a minimum amount of CPU time outside of shared variable access. This is not typical for an embedded application, be sure to wisely budget CPU time for each function. - Number of Shared Variable Accessors
Performance may also be affected if multiple clients are accessing the same shared variable engine. National Instruments recommends executing application-specific benchmarks in this situation. - Shared Variable Data Type
Double-precision floating-point is the largest non-custom data type native to LabVIEW. For smaller data types it may be possible to achieve a greater number of updates per second. For large custom data types, expect to achieve a lower number of updates per second.
Alternative Data Transfer Methods
If shared variables are not suitable for your application needs, consider the following alternative data transfer methods:
- Network Streams
Network streams implement a unidirectional, point-to-point buffered communication model and are optimized for lossless, high-throughput network communication. Learn more about network streams in the Lossless Communication with Network Streams: Components, Architecture & Performance whitepaper. - TCP/IP & UDP
TCP and UDP are the low level protocols underneath most Ethernet communication standards. If shared variables, network streams or any of the other various networking abstractions are not sufficient for your application, consider working directly on the low level protocol. Learn more about TCP and UDP in the LabVIEW help documentation for Using LabVIEW with TCP/IP and UDP.
The CompactRIO Developers Guide also contains a section on Best Practices for Network Communication. This document discusses advantages and disadvantages of various network communication methods and architectures.