Développement et personnalisation de modèles de processus TestStand
Aperçu
Ce document décrit les pratiques exemplaires pour personnaliser le modèle de processus. Ce document est particulièrement utile pour ceux qui ont une connaissance pratique du développement de base de modèles de processus. Pour vous familiariser avec ces concepts, reportez-vous au document Théorie des modèles de processus pour un savoir comment TestStand utilise les modèles de processus.
Contenu
- Rôle des modèles de processus dans un système de tests
- Composants du modèle de processus
- Personnalisation d’un modèle de processus
- Modification du comportement du modèle existant
- Modification des structures de données du modèle de processus
- Définition d’un comportement personnalisé pour une station de test particulières
- Mise à niveau des modèles de processus personnalisés vers des versions ultérieures de TestStand
- Consultation des autres sections de la série d’architecture avancée
Rôle des modèles de processus dans un système de tests
La création d’un test complet pour un produit nécessite plus que la simple exécution d’un ensemble de cas de test. En général, le système de test doit effectuer une série d’opérations avant, pendant et après l’exécution de la séquence qui effectue les tests. Les opérations courantes qui définissent le processus de tests incluent l’identification de l’UUT, la notification à l’opérateur de l’état de réussite/échec, l’enregistrement des résultats et la génération d’un rapport de test. On appelle modèle de processus l’ensemble de ces opérations et leur flux d’exécution. Dans TestStand, la couche de modèle de processus est implémentée dans des fichiers de séquence et est distincte du moteur TestStand. Cette modularité vous permet de personnaliser les modèles de processus sans affecter l’exécutif de test lui-même.
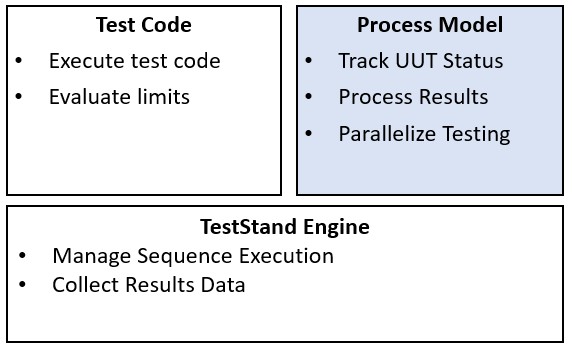
Les modèles de processus fournissent une couche supplémentaire, distincte de l’exécutif de test et du code de test, pour implémenter la fonctionnalité de test commune
Les modèles de processus distinguent TestStand de la plupart des responsables de test locaux. En règle générale, ces applications n’ont pas le concept de modèle de processus et la séquence de test ou l’exécutif de test lui-même fournit le mécanisme pour les tâches de test courantes. Aucune de ces approches n’est idéale :
- Si le code de test est responsable de ces opérations courantes, chaque nouvel ensemble de tests créé devra répéter ce code.
- Si des opérations communes sont implémentées directement dans l’exécutif de test, la modification des opérations de test communes nécessite des mises à jour de l’ensemble de l’exécutif de test.
L’utilisation d’un modèle de processus pour effectuer des tâches courantes permet une modularité et une réutilisabilité accrues, car vous pouvez apporter des modifications aux opérations courantes dans un seul emplacement, tout en les séparant de l’exécutif de test sous-jacent.
Les modèles de processus TestStand sont encore plus modulaires grâce à l’architecture plug-in. Les modèles de processus appellent des fichiers de séquence de plug-in pour implémenter le traitement des résultats, comme la génération de rapports et l’enregistrement de bases de données. Vous pouvez modifier ces plug-ins ou créer les vôtres pour étendre les fonctionnalités du modèle de processus sans modifier les modèles de processus eux-mêmes.
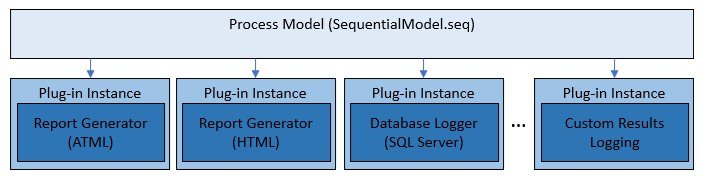
Le modèle de processus appelle des plug-ins pour effectuer le traitement des résultats, y compris la génération de rapports et la journalisation de bases de données. Vous pouvez également créer des plug-ins personnalisés pour implémenter des mécanismes d’enregistrement personnalisés
Vous pouvez utiliser les modèles de processus TestStand pour créer une application de test extrêmement puissante et flexible. L’implémentation modulaire du modèle de processus minimise la quantité de modifications de code que vous devez apporter lors de la mise à jour des fonctionnalités de l’infrastructure. L’utilisation de l’architecture de modèle de processus TestStand pour développer un système de test complet peut faire gagner du temps ainsi que des coûts de développement et de maintenance.
Composants du modèle de processus
Dans TestStand, les modèles de processus sont implémentés sous forme de fichiers de séquence avec l’option de modèle de processus activée, ce qui leur permet de contenir des types supplémentaires de séquences spécifiques au modèle. Le type de fichier de séquence est configuré dans l’onglet Avancé (Advanced) des propriétés du fichier de séquence. Ces types de séquence ont chacun un comportement particulier :
- Les points d’entrée d’exécution permettent aux utilisateurs d’exécuter des tests en utilisant la séquence de modèle de processus souhaitée.
- Les points d’entrée de configuration fournissent une interface utilisateur permettant aux utilisateurs de configurer les paramètres du modèle de processus et de stocker ces paramètres.
- Les callbacks de modèles permettent au fichier de séquence de test de remplacer le comportement du modèle de processus.
Utilisez l’onglet Modèle (Model) de la boîte de dialogue Propriétés de séquence (Sequence Properties) pour configurer les types de séquences qu’un fichier de modèle de processus peut contenir.
Séquences de points d’entrée d’exécution
Les points d’entrée d’exécution permettent aux utilisateurs d’exécuter leur code de test via le modèle de processus. Le modèle de processus TestStand par défaut fournit deux points d’entrée d’exécution, des UUT de test et un passage unique. Chacun de ces points d’entrée est implémenté dans une séquence dans le fichier de séquence du modèle de processus. Dans l’éditeur de séquence, le menu Exécuter (Execute) répertorie les points d’entrée d’exécution lorsque la fenêtre active contient un fichier de séquence utilisant le modèle de processus.
Le modèle de processus séquentiel utilise les points d’entrée d’exécution des UUT à passage unique (Single Pass) et Test. Les deux points d’entrée d’exécution appellent la séquence MainSequence du fichier de séquence client pour exécuter des tests pour une UUT à la fois. Les points d’entrée partagent également d’autres actions, telles que la génération de rapports de test et le stockage des résultats de données dans une base de données.
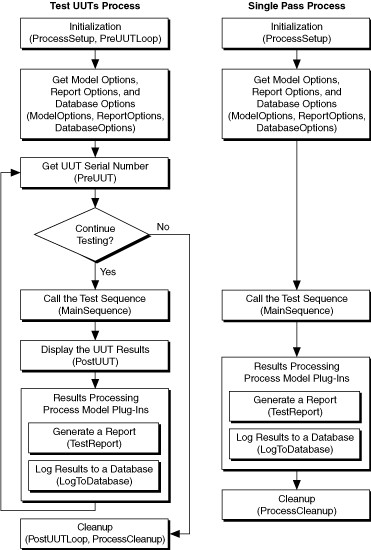
Flux de point d’entrée d’exécution UUT à passage unique et test dans un modèle de processus séquentiel
L’expression du nom du point d’entrée est le nom qui apparaît dans l’éditeur de séquence ou dans une interface utilisateur lors de l’utilisation du point d’entrée. Utilisez le champ Expression du nom du point d’entrée (Entry Point Name Expression) de l’onglet Modèle (Model) de la boîte de dialogue Propriétés de la séquence (Sequence Properties) pour modifier cette valeur. Le champ Expression du nom du point d’entrée (Entry Point Name Expression) est visible uniquement lorsque la séquence que vous sélectionnez est un point d’entrée d’exécution. Une valeur par défaut, telle que ResStr("MODEL", "TEST_UUTS"), utilise la fonction ResStr, qui comprend la localisation TestStand. Remplacez la valeur par une autre valeur localisée ou utilisez une expression de chaîne constante qui décrit le point d’entrée du point de vue d’un utilisateur.
L’utilisation de chaînes de localisation au lieu d’une constante vous permet d’apporter des modifications à la valeur de la chaîne sans qu’il soit nécessaire de modifier le modèle de processus lui-même. Pour plus d’informations sur l’utilisation des chaînes de ressources TestStand pour la localisation, reportez-vous au tutoriel Localiser TestStand dans différentes langues.
Point d’entrée de configuration
Les points d’entrée de configuration permettent aux utilisateurs de configurer les paramètres du modèle de processus. Les modèles par défaut contiennent les points d’entrée Options du modèle (Model Options) et Traitement des résultats (Result Processing). À l’instar des points d’entrée d’exécution, les points d’entrée de configuration sont implémentés dans une séquence dans le fichier de modèle de processus et sont répertoriés dans le menu Configurer (Configure) de l’éditeur de séquence. Pour enregistrer les paramètres, les points d’entrée du modèle écrivent des données dans des fichiers de configuration dans le répertoire de configuration TestStand.
Callback de modèles
Les callbacks de modèle permettent aux développeurs de tests de personnaliser certains aspects du modèle de processus pour leur test particulier, sans apporter de modifications au modèle de processus lui-même. Le modèle de processus définit des séquences de callbacks que les points d’entrée appellent à différents moments de l’exécution. Par exemple, le point d’entrée Test UUT appelle la séquence de callbacks PreUUT avant de commencer le test pour demander à l’utilisateur un numéro de série. Si un développeur de test nécessite une modification spécifique de cette fonctionnalité, il peut remplacer le callback dans son fichier de séquence de test. Dans ce cas, lorsque le modèle appelle la séquence PreUUT, la séquence du fichier de séquence de test est appelée à la place de la séquence PreUUT dans le fichier de modèle de processus.
Pour une description détaillée des callbacks de modèle de processus, reportez-vous au document Utilisation des callbacks dans NI TestStand.
Le fichier de séquence de test peut remplacer les séquences de callbacks dans le modèle de processus pour définir un comportement personnalisé
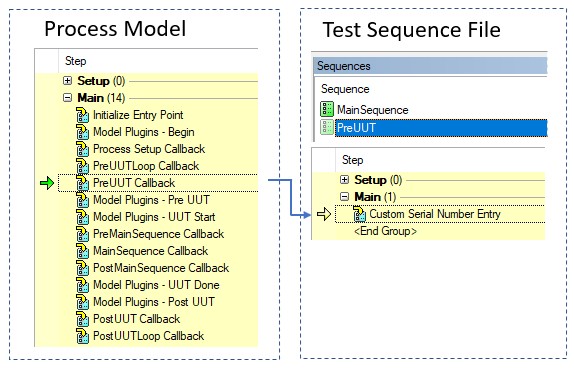
Plug-ins de modèle de processus
Les modèles de processus par défaut utilisent une architecture de plug-in pour implémenter le traitement des résultats, y compris la génération de rapports et l’enregistrement de bases de données. Chaque plug-in est implémenté dans un fichier de séquence distinct qui contient des séquences de points d’entrée de plug-in appelées à divers points dans les principaux points d’entrée du modèle de processus. Les modèles de processus fournissent également une boîte de dialogue de configuration de plug-in qui permet aux développeurs de tests de configurer les plug-ins actifs et de configurer les paramètres de plug-in.
Pour plus d’informations sur l’architecture de plug-ins de modèle de processus TestStand, reportez-vous à la rubrique d’aide Architecture de plug-ins de modèle de processus.
Callbacks de moteur supplémentaires
Les fichiers de séquence de modèle de processus fournissent des callbacks de moteur supplémentaires qui ne sont pas disponibles dans les fichiers de séquence standard. Ces callbacks, qui ont le préfixe « ProcessModel », ne s’exécutent que pour les étapes du fichier de séquence client actuel du modèle de processus où vous les définissez. Par exemple, le callback ProcessModelPostStep s’exécute après chaque étape qui s’exécute dans la séquence de test, mais ne s’exécute pas après les étapes du modèle de processus lui-même.
Une application courante pour ces rappels est la gestion des erreurs personnalisée. En règle générale, les développeurs de tests souhaitent extraire autant d’informations que possible des erreurs et veulent contrôler le comportement du système en cas d’erreurs. Dans d’autres cas d’utilisation, les environnements entièrement automatiques sous-traités nécessitent généralement des entrées de démarrage/d’arrêt et des sorties de lumière rouge/verte au moyen d’un journal approprié pour la mise au point afin de suivre l’activité précédente du système et tester les erreurs.
Vous pouvez utiliser les callbacks ProcessModelPostStepFailure et ProcessModelPostStepRuntimeError Engine définis au niveau du modèle de processus pour gérer de manière générique les erreurs de tous les fichiers de séquence client sans nécessiter d’effort supplémentaire de la part du programmeur de séquence de test. Ces callbacks s’exécutent si une erreur se produit dans le fichier de séquence client.
Personnalisation d’un modèle de processus
Dans de nombreux cas, vous devrez peut-être étendre ou modifier les fonctionnalités des modèles de processus livrés avec TestStand. Les modifications courantes apportées aux modèles de processus comprennent les modifications apportées aux rapports, aux stratégies de relance de test, à la gestion et à l’enregistrement des erreurs, aux routines d’étalonnage des stations et aux mécanismes de sélection UUT.
Ajout de nouvelles fonctionnalités à l’aide de plug-ins de modèle de processus
Les modèles de processus par défaut utilisent des plug-ins pour implémenter la fonctionnalité de traitement des résultats, y compris la génération de rapports et l’enregistrement de bases de données. Cependant, les plug-ins ne sont pas limités au seul traitement des résultats. Si vous devez ajouter des fonctionnalités au modèle de processus, vous pouvez créer un plug-in pour implémenter cette fonctionnalité sans modifier les modèles de processus eux-mêmes. Cette approche présente de nombreux avantages :
- Vous pouvez facilement intégrer vos plug-ins aux modèles séquentiels, par lots et en parallèle, au lieu d’implémenter des modifications pour chacun.
- Vous n’aurez pas besoin de maintenir et de déployer un modèle de processus personnalisé.
- Vous pouvez intégrer des personnalisations aux futures modifications des modèles de processus.
- Les plug-ins peuvent être partagés sans qu’il soit nécessaire d’intégrer les modifications du code du modèle de processus.
Par défaut, les utilisateurs doivent créer des instances de plug-ins pour que le modèle les exécute. Cette approche d’inclusion est souhaitable si la nouvelle fonctionnalité que vous ajoutez n’est requise que dans certains cas. Si la fonctionnalité doit toujours s’exécuter, comme le code dans le modèle de processus lui-même, vous pouvez utiliser un module complémentaire de plug-in de modèle de processus. Les modules complémentaires de plug-in sont implémentés de la même manière que les plug-ins standard, mais sont enregistrés dans le sous-dossier de suppléments du répertoire plug-ins. Ils n’apparaissent pas dans la boîte de dialogue de configuration du plug-in et sont toujours exécutés.
Création de nouveaux plug-ins
Vous pouvez développer des plug-ins personnalisés pour étendre le modèle de plusieurs manières en plus du traitement personnalisé des résultats. L’étalonnage des stations de test est un exemple de fonctionnalité que vous pouvez ajouter aux modèles de processus via un plug-in personnalisé. Vous devrez peut-être confirmer la validité de l’étalonnage de la station avant d’exécuter les fichiers de séquence de test sur une station de test. Ces routines vérifient généralement que l’équipement de test est étalonné selon une date d’expiration. L’expiration de l’étalonnage déclenche une condition d’erreur, avertit l’opérateur et empêche l’exécution du test.
En implémentant la fonctionnalité dans un plug-in de modèle personnalisé, vous pouvez autoriser les utilisateurs à désactiver l’étalonnage si nécessaire et fournir une interface de configuration aux développeurs de tests via la boîte de dialogue de traitement des résultats. Reportez-vous à la rubrique relative à la création de plug-ins de modèle de processus pour obtenir des informations sur l’implémentation.
Modification du comportement du modèle existant
Pour modifier le comportement implémenté directement dans le modèle de processus, tel que le suivi du numéro de série UUT, il est nécessaire d’apporter des modifications directement au modèle. Utilisez une copie du modèle de processus comme point de départ pour développer de nouveaux modèles de processus ou pour personnaliser des modèles de processus existants afin de pouvoir réutiliser de grandes quantités de logique affinée déjà implémentée dans le modèle de processus par défaut.
Avant de modifier les modèles de processus, créez une copie de l’ensemble du répertoire de modèles, situé dans <TestStand>/Components/Models, à l’emplacement correspondant dans le répertoire public TestStand, <TestStand Public>/Components/Models. Ne modifiez que les fichiers de l’emplacement public TestStand.
Modification des points d’entrée du modèle
Dans de nombreux cas, vous souhaiterez peut-être personnaliser le flux d’exécution du point d’entrée d’exécution. Par exemple, vous pouvez souhaiter que le système de test relance automatiquement un test sur un UUT lorsque certains types d’échecs se produisent ou en limitant le nombre de tentatives par opérateur avant d’exiger l’intervention du superviseur pour déterminer la nécessité de nouveaux tests. Pour ces types de modifications, vous devrez modifier directement la séquence de points d’entrée pour ajouter une boucle et d’autres conditions. Lorsque vous apportez des modifications aux points d’entrée, assurez-vous de documenter les modifications que vous apportez pour faciliter la différenciation du comportement par défaut des personnalisations.
Permettre aux développeurs de tests de personnaliser le comportement du modèle
Lors de la personnalisation des modèles de processus, il est important de déterminer si un test spécifique peut nécessiter la modification ou la désactivation du comportement que vous définissez. Dans les cas où le développeur de test peut avoir besoin d’apporter des modifications, utilisez une séquence de callback existante ou nouvelle pour implémenter les modifications. Le développeur du test peut alors remplacer le callback s’il doit modifier le comportement que vous définissez.
La nouvelle fonctionnalité doit toujours être implémentée dans une séquence séparée, que vous appelez à partir des points d’entrée qui doivent l’implémenter. Vous pouvez implémenter une séquence dans le modèle de processus des manières suivantes en fonction du niveau de personnalisation que vous souhaitez fournir aux développeurs de tests :
- Vous souhaitez fournir aux développeurs de tests un moyen d’étendre le modèle à un certain moment de l’exécution : Implémentez un espace réservé sans fonctionnalité par défaut afin que le fichier de séquence client puisse insérer des fonctionnalités si nécessaire. Vous pouvez éventuellement transmettre des paramètres au callback lorsque vous l’appelez à partir du point d’entrée pour fournir des données pertinentes au développeur de test. Par exemple, ModifyReportHeader ne fournit pas d’implémentation par défaut, mais les paramètres qui contiennent des données liées au rapport sont transmis au rappel pour permettre aux développeurs de tests d’accéder au rapport et de le modifier.
- Vous souhaitez définir des fonctionnalités qui peuvent être personnalisées ou désactivées par les développeurs de tests : Implémentez le comportement par défaut afin que le callback client puisse appeler le callback de modèle pour exécuter l’implémentation par défaut du modèle de processus et que le callback client puisse implémenter des fonctionnalités supplémentaires. Par défaut, PostUUT implémente des bannières pour afficher le résultat de la séquence de test. Un fichier de séquence client peut implémenter des comportements PostUUT personnalisés et conserver la bannière en remplaçant le callback et en appelant toujours l’implémentation du modèle de processus. Vous pouvez utiliser l’option Copier l’étape (Copy Step) et les paramètres locaux (Locals) lors de la création d’une séquence de remplacement dans les propriétés de la séquence pour spécifier que le contenu de la séquence doit être copié lorsqu’un développeur de test remplace le callback.
- Vous voulez empêcher les développeurs de tests de personnaliser la fonctionnalité du tout : Si vous définissez une fonctionnalité qui ne doit jamais être modifiée par les développeurs de tests, utilisez une séquence normale plutôt qu’un callback, qui ne peut pas être remplacée dans les fichiers de séquence client.
Personnalisation du comportement du plug-in de modèle existant
Il est courant pour les développeurs de framework de personnaliser le comportement de génération de rapports pour répondre aux exigences spécifiques de leur système de test. La personnalisation des rapports est traitée en détail dans le document Pratiques exemplaires de personnalisation et génération de rapports NI TestStand de la série d’architecture avancée. Ce document fournit plus d’informations sur la manière d’implémenter des personnalisations pour la génération de rapports dans l’architecture du modèle TestStand.
Modification des structures de données du modèle de processus
Les modèles de processus par défaut définissent des types de données pour stocker des informations sur les options UUT, la station et le modèle actuels. Dans certains cas, vous devrez peut-être stocker des données supplémentaires dans ces propriétés, le plus souvent les données UUT. Par exemple, le mécanisme de sélection par défaut TestStand UUT ne suit qu’un numéro de série, mais vous devrez peut-être également conserver le numéro de modèle.
NI vous recommande de ne pas modifier les types de données du modèle lorsque cela est possible, car ils sont référencés dans de nombreux fichiers TestStand et les mises à jour peuvent être difficiles à gérer. Cependant, les modèles de processus fournissent une propriété non structurée dans les types de données UUT et NI_StationInfo qui vous permet d’ajouter facilement des informations de suivi UUT supplémentaires sans qu’il soit nécessaire de modifier le type de données UUT. Vous pouvez créer une nouvelle propriété ModelNumber dans le conteneur UUT.AdditionalData pour stocker ces informations. L’exemple d’ajout de données personnalisées à un rapport fourni avec TestStand montre comment vous pouvez utiliser cette propriété pour ajouter des champs à cette propriété et les inclure dans le rapport de test. L’exemple implémente les mises à jour dans le fichier de séquence client à l’aide d’un callback, mais vous pouvez utiliser la même approche directement dans le modèle de processus.
Définition d’un comportement personnalisé pour une station de test particulières
Vous pouvez également remplacer un callback dans le fichier de séquence de modèle de processus en créant une séquence avec le même nom, mais des fonctionnalités différentes dans StationCallbacks.seq dans le répertoire <TestStand Public>\Components\Callbacks\Station. TestStand appelle les callbacks de modèle dans StationCallbacks.seq au lieu d’appeler le callback de nom similaire défini dans n’importe quel modèle. Un rappel dans un fichier client remplace le rappel de nom similaire dans le modèle et le fichier StationCallbacks.seq.
Mise à niveau des modèles de processus personnalisés vers des versions ultérieures de TestStand
Lorsque vous effectuez une mise à niveau vers une version plus récente de TestStand, vous devrez fusionner toutes les modifications apportées aux modèles de processus par défaut avec les modifications apportées par NI dans la nouvelle version. Pour ce faire, vérifiez d’abord les différences entre l’ancien et le nouveau modèle de processus par défaut à l’aide de l’outil de différence TestStand, situé dans Éditer » Comparer au fichier de séquence différentielle (Edit » Diff Sequence File Against) dans l’éditeur de séquence. Si toutes les modifications sont centralisées dans de nouvelles séquences dans les fichiers de modèle de processus, ou implémentées séparément dans des plug-ins, l’importation des personnalisations de modèle de processus dans la nouvelle version du modèle de processus sera relativement facile.
Si vous migrez des modèles que vous avez créés dans des versions de TestStand antérieures à 2012, des changements importants ont été apportés aux nouveaux modèles afin de mettre en œuvre l’architecture du plug-in. Reportez-vous à Migration des personnalisations de modèle de processus vers TestStand 2012 ou version ultérieure pour plus de détails sur la migration de vos modèles de processus dans ce cas.