From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
Lors de la création d’un programme de test avec TestStand, la principale fonctionnalité de test est implémentée dans des modules de code séparés. TestStand fournit des adaptateurs qui appellent des modules de code développés à l’aide de divers environnements de programmation et langages tels que LabVIEW, LabWindows™/CVI™, C#, VB .NET, C/C++ et ActiveX.
Ce document décrit les pratiques exemplaires à prendre en compte lors du développement de vos modules de code de système de test et à appeler à partir de votre séquence de test. Pour utiliser ce document, il est supposé que vous avez une connaissance pratique de base de TestStand, y compris comment créer une séquence de test de base. Si vous ne connaissez pas ces concepts, reportez-vous aux ressources de prise en main suivantes avant d’utiliser ce document :
Pour plus d’informations sur la façon d’implémenter des modules de code, reportez-vous aux rubriques d’aide de TestStand Types de pas intégrés et Adaptateurs de modules.
Avant de commencer à développer un système de test, envisagez de définir une approche générale pour les aspects suivants du système de test :
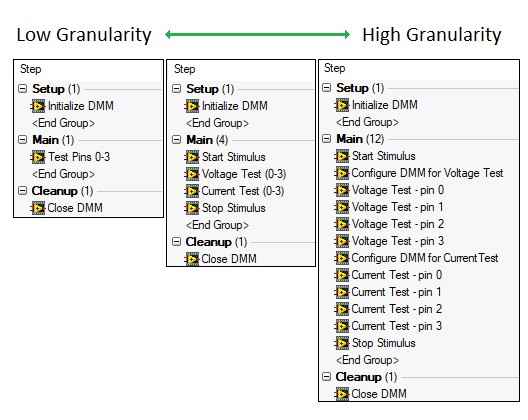
Lors de la conception d’un système de test, il est important de définir un niveau de granularité cohérent pour les modules de code. La granularité fait référence à l’étendue des fonctionnalités de chaque module de code dans un système de test. Une séquence de test avec une granularité faible appelle peu de modules de code qui exécutent chacun plus de fonctionnalités, tandis qu’une séquence avec une granularité élevée appelle de nombreux modules de code, chacun avec une portée plus petite.
| Faible granularité | Granularité élevée |
|
|
Vous devez viser un équilibre entre ces extrêmes, car chacun a ses propres avantages.
Implémentation d’un test simple utilisant différents niveaux de granularité
Pour maintenir une granularité cohérente dans votre système de test, créez un ensemble de normes pour le développement de modules de code, telles que :
Lorsque vous spécifiez le chemin d’un module de code dans un pas de test, vous pouvez choisir d’utiliser un chemin absolu ou relatif. Il est recommandé d’éviter les chemins absolus pour les raisons suivantes :
Lorsque vous spécifiez un chemin d’accès relatif, TestStand utilise une liste de répertoires de recherche pour résoudre le chemin d’accès. Ces répertoires de recherche contiennent généralement le répertoire du fichier de séquence actuel, les répertoires spécifiques à TestStand et les répertoires système.
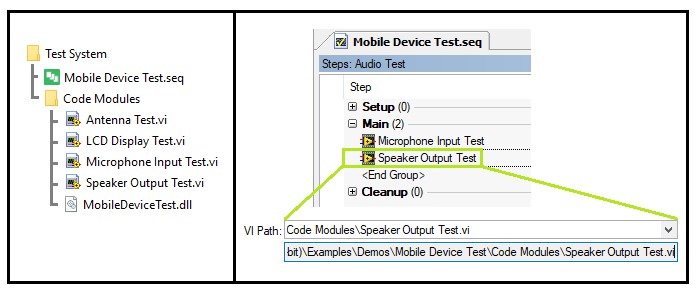
Il est important de définir une structure de fichiers pour vos séquences de tests et modules de codes avant de commencer le développement. Utilisez les conseils suivants pour définir une stratégie de stockage des fichiers de séquence et des modules de code.
Définissez une structure de répertoire où les modules de code sont dans un sous-répertoire du fichier de séquence.
Lors du déploiement du code de test à l’aide de l’utilitaire de déploiement TestStand, vous pouvez choisir des destinations précises pour les fichiers de séquence et pour les modules de code dépendants. S’il existe un chemin relatif entre les répertoires de destination du fichier de séquence et le module de code, l’utilitaire de déploiement TestStand met à jour le chemin dans le fichier de séquence pour pointer vers l’emplacement mis à jour. Dans la plupart des cas, il est préférable de faire correspondre la structure de répertoires de votre déploiement à celle du système de développement, afin de vous assurer que le déploiement est aussi similaire que possible au code de votre machine de développement.
Lors de la définition de la portée des modules de code pour votre système de test, il est important de définir une stratégie pour laquelle la fonctionnalité sera implémentée dans les modules de code par rapport au fichier de séquence. Les sections suivantes peuvent vous aider à déterminer l’endroit le plus approprié pour implémenter des fonctionnalités communes :
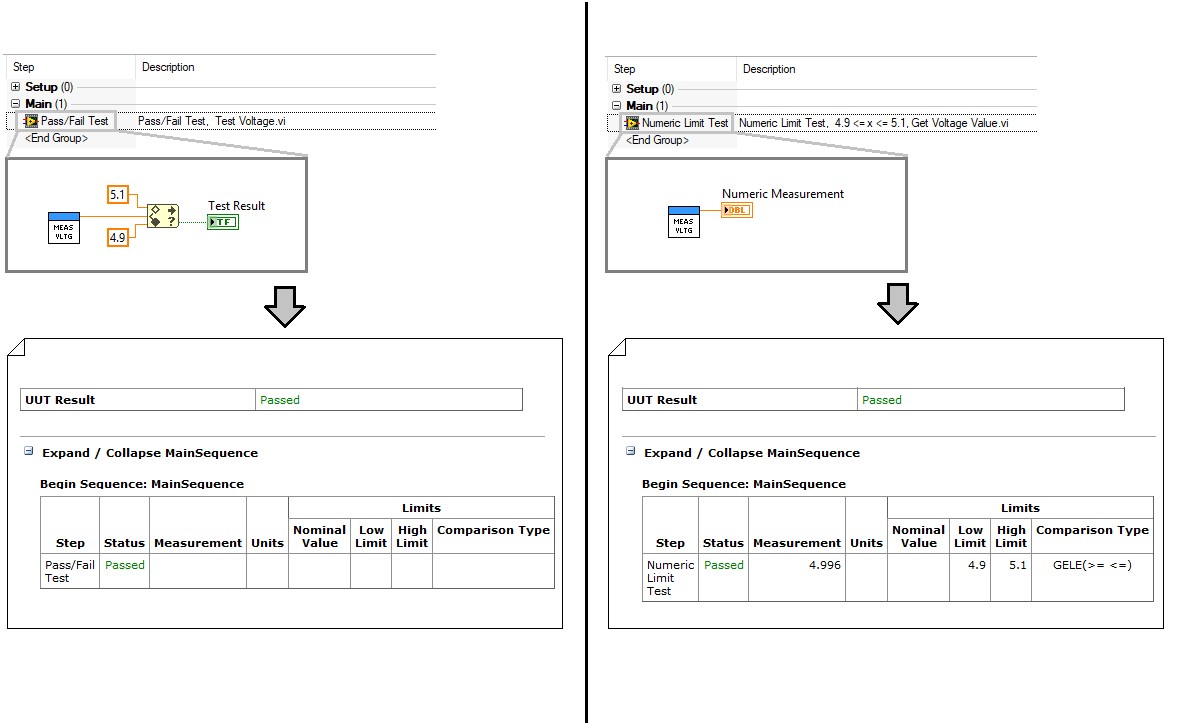
Idéalement, le module de code devrait contenir des fonctionnalités directement liées à l’obtention des mesures de test, et la séquence de test devrait traiter le résultat brut du test. Cette approche présente les avantages suivants :
Pour des mesures plus simples, le module de code peut renvoyer la valeur de mesure brute à la séquence pour traitement. Par exemple, si un pas de test mesure la tension sur une broche précise de l’unité sous test (UUT), le module de code doit renvoyer la valeur mesurée, plutôt que d’effectuer la vérification directement dans le module de code. Vous pouvez traiter cette valeur pour déterminer le résultat du test dans le fichier de séquence à l’aide d’un pas de test de limite numérique.
L’évaluation des limites dans le pas de test simplifie les modules de code et améliore la journalisation des résultats.
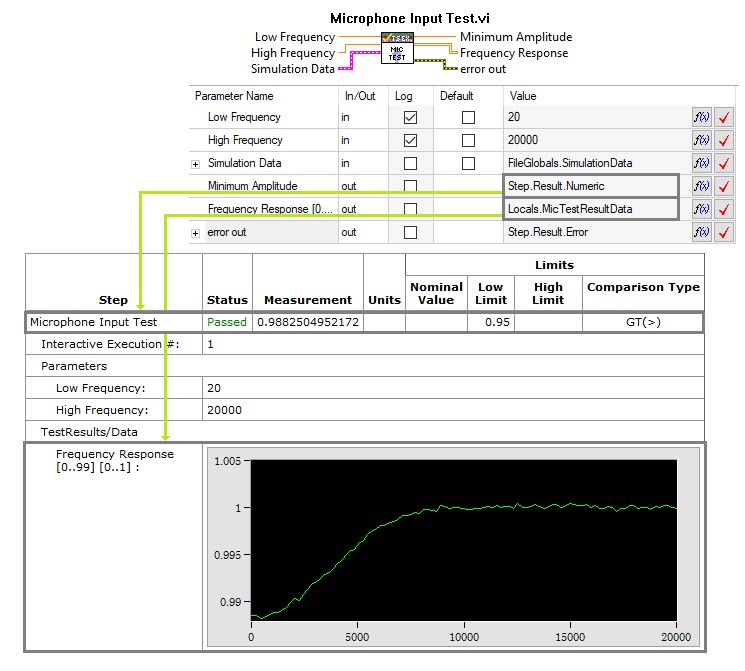
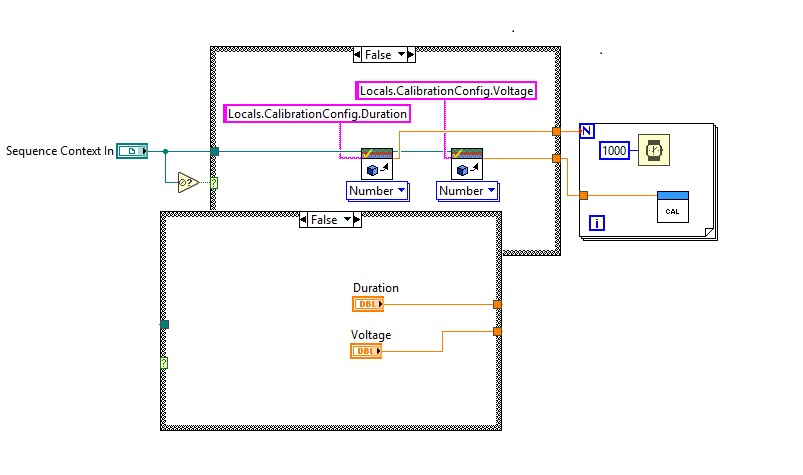
Cependant, en raison de la complexité de certains tests, il n’est pas toujours possible de traiter les résultats de test bruts dans le fichier de séquence. Pour des mesures plus complexes, un traitement supplémentaire des données de résultat est probablement nécessaire. Les données complexes peuvent être traitées en une seule chaîne ou un résultat numérique, qui peut ensuite être évalué dans TestStand à l’aide d’une comparaison de chaîne ou numérique. Par exemple, les résultats d’un test de balayage de fréquence sont complexes et ne peuvent pas être évalués directement, mais les données peuvent être traitées en un seul nombre représentant la valeur minimale. Dans ce cas, le module de code doit évaluer le résultat traité et renvoyer les données de fréquence dans un paramètre distinct pour la journalisation, comme indiqué dans l’exemple de test du périphérique mobile ci-dessous :
Pour des données plus complexes, traitez les données dans le module de code pour générer un résultat numérique ou de chaîne et utilisez un paramètre pour passer les données brutes pour la journalisation.
Si les données brutes sont très volumineuses, la transmission des données à TestStand peut avoir une incidence importante sur les performances. Dans ce cas, envisagez d’enregistrer les données directement dans un fichier TDMS et de les lier au fichier à partir du rapport de test. De cette manière, vous pouvez référencer les données du rapport sans avoir à les transmettre à TestStand. Reportez-vous à la section Inclure des hyperliens dans un rapport - Fichier TDMS pour plus d’informations sur cette approche.
Si le pas ne peut pas déterminer le résultat du test à l’aide des types d’évaluation disponibles dans les pas de test, envisagez de créer un nouveau type de pas de test avec des fonctionnalités supplémentaires pour gérer le type de test requis. Pour plus d’informations sur la création de types de pas de test personnalisés, reportez-vous à l’article Pratiques exemplaires pour le développement de types de pas de test personnalisés de cette série.
Pour de nombreux tests, l’UUT ou l’environnement de test doit être dans un certain état avant de pouvoir effectuer le test. Par exemple, une tension d’excitation peut être nécessaire pour prendre une mesure de température, ou une chambre chauffée doit être réglée sur une température spécifiée. Pour ces types de modules, utilisez des paramètres pour transmettre des valeurs d’entrée, telles que la tension d’excitation ou la température souhaitée. Cette possibilité offre plusieurs des mêmes avantages que le retour de données brutes dans des modules de code de test par rapport aux limites de traitement directement dans le code, comme expliqué dans la section précédente.
TestStand fournit une fonctionnalité intégrée pour la génération de rapports et l’enregistrement de la base de données en utilisant les résultats des pas de test. Pour cette raison, évitez d’implémenter tout type d’enregistrement de données directement dans les modules de code. À la place, assurez-vous que toutes les données que vous souhaitez enregistrer sont transmises en tant que paramètre et utilisez TestStand pour enregistrer les données. Certaines données, telles que les résultats des tests, les limites et les informations d’erreur, sont automatiquement enregistrées. Pour enregistrer d’autres données, vous pouvez utiliser la fonction de résultats supplémentaires pour spécifier des paramètres supplémentaires à inclure dans le rapport.
Pour plus d’informations sur l’ajout de résultats au rapport de test, reportez-vous à l’exemple Ajouter des données personnalisées à un rapport inclus avec TestStand.
Si vous avez des exigences précises pour la journalisation, envisagez de modifier ou de créer un plug-in de traitement des résultats. De cette manière, vous pourrez utiliser la collection de résultats TestStand intégrée pour collecter les résultats, tandis que vous pourrez déterminer comment les résultats sont traités et présentés. Reportez-vous à la section Création de plug-ins du document Pratiques exemplaires pour le développement et la personnalisation de modèles de processus TestStand pour plus d’informations
La meilleure approche pour implémenter les boucles peut être difficile à déterminer, car chaque approche a ses propres avantages et inconvénients. Utilisez les conseils suivants pour déterminer la stratégie la mieux adaptée à votre application :
Boucle interne dans le module de code
Boucle externe dans le fichier de séquence
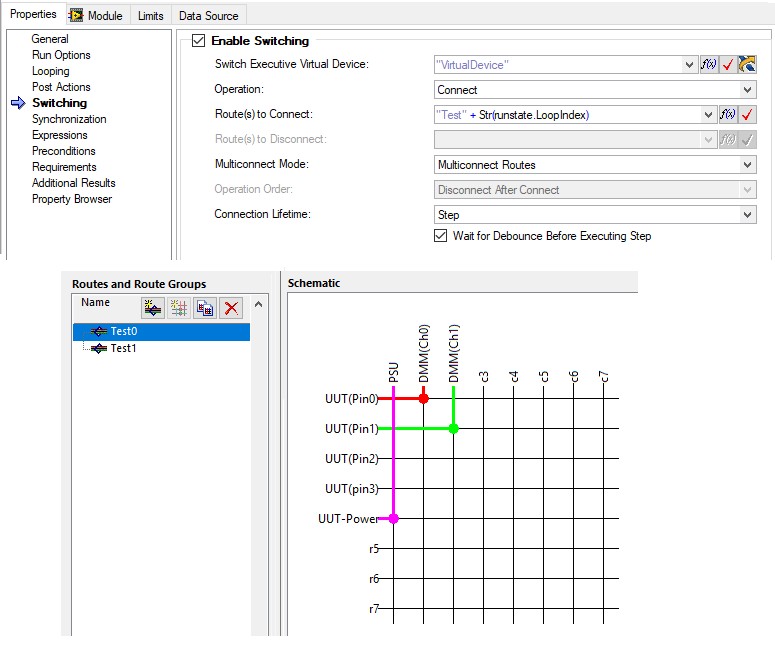
De nombreux systèmes de test utilisent la commutation pour permettre à un seul matériel de tester plusieurs sites. Les commutateurs vous permettent de contrôler par programme les broches d’une unité en cours de test (UUT) connectées à du matériel particulier via des routes prédéfinies.
Vous pouvez implémenter la commutation dans les modules de code TestStand des manières suivantes :
Lorsque vous utilisez du matériel NI Switch, vous pouvez utiliser NI Switch Executive pour définir rapidement des itinéraires. Si vous avez accès à NI Switch Executive, l’utilisation des paramètres de pas intégrés pour la commutation est généralement la meilleure approche et présente les avantages suivants :
Utilisez NI Switch Executive pour spécifier des itinéraires directement à partir des paramètres de pas TestStand, y compris la prise en charge de l’expression TestStand pour déterminer dynamiquement l’itinéraire à l’aide de l’indice de boucle actuel ou d’autres propriétés.
Pour éviter de maintenir des modules de code pour des tâches plus simples, vous pouvez utiliser le langage d’expression dans TestStand pour effectuer des calculs de base et une manipulation de tableau unidimensionnel. Des exigences de programmation plus avancées doivent être implémentées dans les modules de code, car les langages de programmation fournissent des fonctionnalités plus robustes qui conviennent mieux à ces tâches. Par exemple, la concaténation de tableaux multidimensionnels est beaucoup plus facile à réaliser avec la fonction native de tableau de construction LabVIEW qu’à travers le langage d’expression.
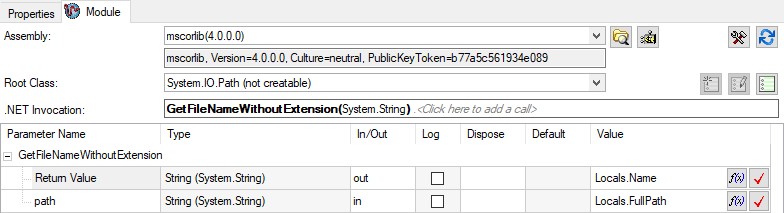
Dans certains cas, vous pouvez utiliser les classes natives fournies avec le framework .NET pour éviter de créer des expressions trop complexes. Par exemple, vous pouvez utiliser la classe System.IO.Path pour effectuer rapidement une manipulation de chemin sans créer de module de code.
Vous pouvez utiliser un pas .NET pour utiliser les méthodes du framework .NET sans avoir besoin d’un module de code.
Lors de l’implémentation de modules de code, de nombreuses décisions de conception auront une incidence sur la plupart des modules de code que vous créez. Cette section fournit des conseils pour les concepts suivants :
Il existe deux approches que vous pouvez utiliser pour accéder aux données TestStand dans un module de code :
Dans la plupart des cas, il est préférable d’utiliser des paramètres pour transmettre des données plutôt que l’API TestStand pour y accéder directement pour les raisons suivantes :
Lorsque cela est possible, utilisez les paramètres pour transmettre les données requises aux modules de code.
Cependant, l’utilisation de l’API pour accéder directement aux propriétés peut être utile dans les cas où le module de code accède dynamiquement à une variété de données, en fonction de l’état du pas. L’utilisation de paramètres du pas dans ce cas peut conduire à une longue liste de paramètres où seuls certains sont réellement utilisés dans diverses conditions.
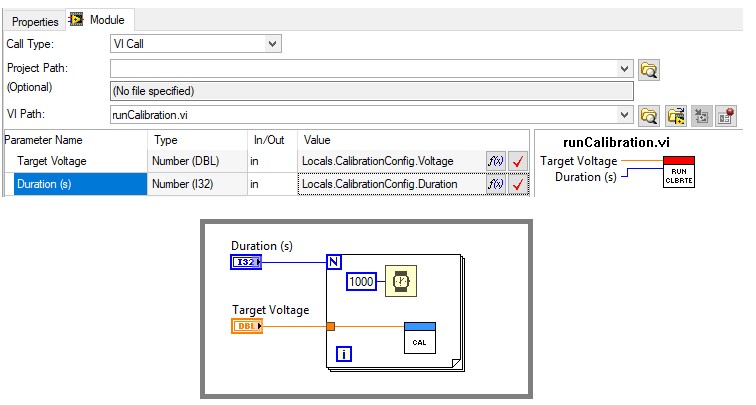
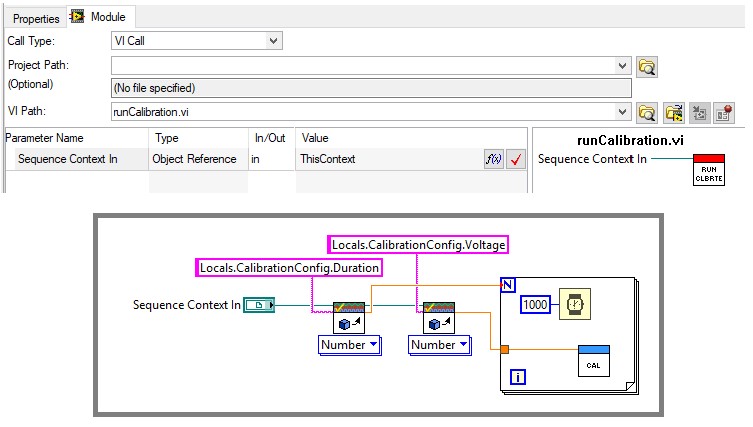
Si vous utilisez l’API TestStand dans un module de code, transmettez une référence à l’objet SequenceContext (ThisContext) en tant que paramètre. L’objet SequenceContext donne accès à tous les autres objets TestStand, y compris le moteur TestStand et le Runstate actuel. La référence de contexte de séquence est également nécessaire si vous utilisez le moniteur de terminaison ou les VIs de boîte de dialogue modale.
Utilisez SequenceContext pour accéder à l’API TestStand dans les modules de code, qui peut être utilisé pour accéder aux données par programmation.
Si vous réutilisez des modules de code en dehors de TestStand, gardez à l’esprit que toutes les opérations qui utilisent l’API TestStand ne seront disponibles que si le module est appelé à partir d’une séquence TestStand. Les données que le module obtient de TestStand via l’API ne seront pas disponibles. Vous pouvez définir un autre mécanisme pour obtenir des données de test dans les cas où le module de code est appelé en dehors de TestStand en vérifiant d’abord si la référence de contexte de séquence est nulle. Dans LabVIEW, vous pouvez utiliser la fonction Pas un nombre/chemin/refnum ? (Not A Number/Path/Refnum?), qui renvoie une valeur booléenne, comme le montre la figure 3.
Utilisez Pas un nombre/chemin/refnum ? (Not A Number/Path/Refnum?) pour vérifier la validité de la référence d’objet SequenceContext pour les modules de code utilisés en dehors de TestStand
Dans de nombreux cas, les modules de code peuvent produire de grandes quantités de données complexes à partir de mesures ou d’analyses. Évitez de stocker ce type de données dans des variables TestStand, car TestStand crée une copie des données lors de leur stockage. Ces copies peuvent réduire les performances d’exécution et/ou provoquer des erreurs de mémoire insuffisante. Utilisez les approches suivantes pour gérer des ensembles de données volumineux sans créer de copies inutiles :
Lorsqu’un utilisateur appuie sur le bouton Terminer (Terminate), TestStand arrête la séquence d’exécution et exécute tous les pas de nettoyage. Cependant, si l’exécution a appelé un module de code, le module doit terminer l’exécution et retourner le contrôle à TestStand avant que la séquence puisse se terminer. Si le temps d’exécution d’un module de code est supérieur à quelques secondes ou lorsque le module attend qu’une condition se produise, telle qu’une entrée utilisateur, il peut apparaître à l’utilisateur que la commande Terminer (Terminate) a été ignorée.
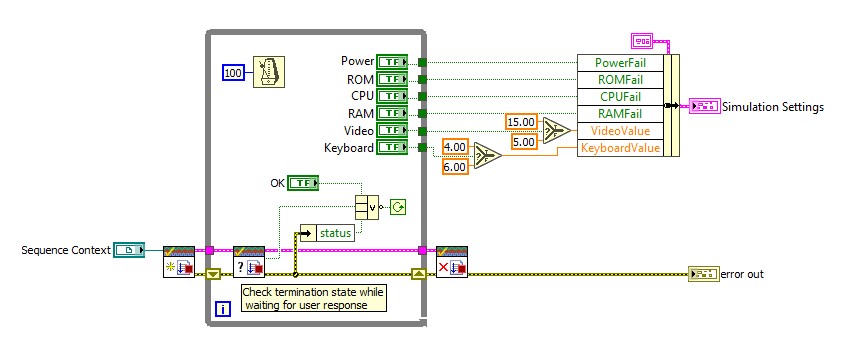
Pour résoudre ce problème, vous pouvez utiliser le moniteur de terminaison pour permettre aux modules de code de vérifier et de répondre à l’état de terminaison de l’exécution appelante. L’exemple d’expédition du test de la carte mère d’ordinateur utilise le moniteur de terminaison dans la boîte de dialogue de simulation, comme illustré ci-dessous. Si la séquence de test est terminée, le VI Vérifier l’état de terminaison renvoie FAUX et la boucle est arrêtée.
Reportez-vous aux exemples de moniteur de terminaison pour plus d’informations sur l’utilisation du moniteur de terminaison.
Une erreur dans un système de test est un comportement d’exécution inattendu qui empêche l’exécution du test. Lorsqu’un module de code génère une erreur, transférez de nouveau ces informations dans la séquence de test pour déterminer l’action à effectuer ensuite, comme terminer l’exécution, répéter le dernier test ou inviter l’opérateur de test.
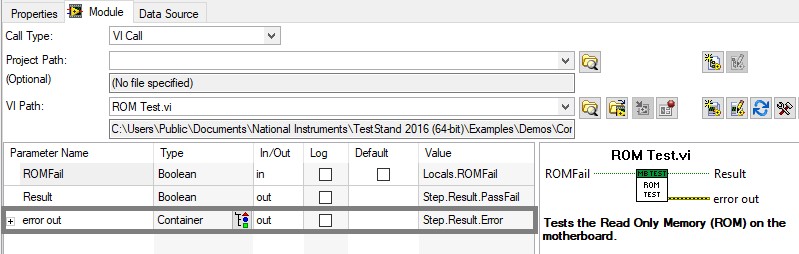
Pour fournir à TestStand les informations d’erreur des modules de code, utilisez le conteneur Result.Error du pas, comme illustré ci-dessous. TestStand vérifie automatiquement cette propriété après chaque pas pour déterminer si une erreur s’est produite. Vous n’avez pas besoin de transmettre les informations d’erreur de TestStand dans le module de code. Si le module de code renvoie une erreur à TestStand, l’exécution peut se ramifier à une autre partie de la séquence de test, par exemple au groupe de pas de test de nettoyage.
Vous pouvez utiliser le paramètre Erreur pendant l’exécution (On Run-Time Error), situé dans l’onglet Exécution (Execution) des options de station (Station Options) pour déterminer comment TestStand répond aux erreurs du pas. En règle générale, vous devez utiliser l’option Afficher la boîte de dialogue (Show Dialog Box) lors du développement de vos séquences pour faciliter le débogage, car cette option vous permet d’interrompre l’exécution et de vérifier l’état actuel de la séquence. Pour les systèmes déployés, envisagez d’utiliser les options Exécuter le nettoyage (Run Cleanup) ou Ignorer (Ignore) plutôt que d’exiger la saisie d’opérateurs de test. Les informations sur l’erreur sont automatiquement enregistrées dans les résultats du test qui peuvent être utilisés pour trouver la cause de l’erreur.
Transmettez les informations d’erreur au conteneur Step.Result.Error pour informer TestStand si une erreur du pas se produit.
Par défaut, TestStand charge tous les modules de code d’un fichier de séquence en mémoire lorsque vous exécutez une séquence dans le fichier et les garde chargés jusqu’à ce que vous fermiez le fichier de séquence. Avec ces paramètres, un retard initial peut se produire lorsque vous démarrez une séquence alors que les modules sont chargés. Cependant, les exécutions ultérieures du fichier de séquence sont plus rapides, car les modules restent en mémoire.
Vous pouvez configurer le moment où un module de code est chargé et déchargé dans l’onglet Options d’exécution (Run Options) du volet des paramètres du pas. En règle générale, les options de charge par défaut offrent les meilleures performances, mais dans certains cas, il peut être préférable de charger le module de code uniquement lorsqu’il est utilisé avec l’option Charger de façon dynamique (Load dynamically). Pour les modules de code qui ne sont pas appelés dans une exécution typique, tels que les diagnostics qui ne s’exécutent qu’après l’échec d’un test particulier, ils doivent être chargés dynamiquement, car dans la plupart des cas, ces modules n’ont pas du tout besoin d’être chargés.
Lorsque vous chargez dynamiquement des modules de code, sachez que TestStand ne signale pas de problèmes pour les modules de code jusqu’à ce qu’il charge le module de code, ce qui pourrait être vers la fin d’une longue exécution. Cependant, vous pouvez utiliser l’analyseur de séquence pour vérifier qu’il n’y a pas d’erreur dans une séquence avant de l’exécuter. L’analyseur vérifie les modules de code chargés statiquement et dynamiquement.
Pour les modules de code gourmands en mémoire, vous pouvez modifier l’option de déchargement par défaut pour réduire l’utilisation totale de la mémoire. Par exemple, définir le module sur Décharger après l’exécution du pas (Unload After Step Executes) ou Décharger après l’exécution de la séquence (Unload After Sequence Executes). Cependant, cette modification augmentera les temps d’exécution, car TestStand devra recharger le module pour chaque appel suivant. Lorsque cela est possible, une meilleure alternative consiste à utiliser la version 64 bits de TestStand et un système avec plus de mémoire physique pour obtenir les performances de test les plus rapides malgré des exigences d’utilisation de la mémoire élevées.
Si vos modules de code conservent des données partagées, telles que des variables statiques ou des variables globales fonctionnelles LabVIEW, la modification des options de déchargement peut entraîner des changements de comportement, car les données globales sont perdues lorsque les modules sont déchargés. Lors de la modification des options de déchargement, assurez-vous que toutes les données requises sont transmises à la séquence TestStand ou stockées dans un emplacement plus permanent pour éviter la perte de données.
Reportez-vous aux Pratiques exemplaires pour améliorer les performances du système NI TestStand pour plus d’informations sur les autres façons d’optimiser les performances d’un système de test.
Une utilisation courante des modules de code est l’interface avec le matériel de test pour configurer des stimuli et prendre des mesures de test. Les méthodes de communication avec le matériel comprennent :
• Utilisation d’un driver matériel, tel que NI-DAQmx, pour communiquer directement avec le matériel.
• Utilisation d’un driver d’instruments, qui envoie en interne des commandes à un instrument via le driver matériel VISA ou IVI.
La méthode de communication que vous utilisez dépend du type de matériel que vous utilisez. Pour l’un ou l’autre type de communication, vous ouvrirez une référence ou une session au driver avant d’effectuer des appels spécifiques au driver et fermerez le pointeur une fois l’interaction terminée.
Dans la plupart des cas, vous communiquerez avec le même matériel en plusieurs pas de test. Pour éviter un incidence sur les performances de l’ouverture et de la fermeture de la session d’instrument dans chaque module de code, il est important de réfléchir à la façon dont vous gérerez les références matérielles dans vos séquences de tests. Il existe deux approches courantes pour gérer les références matérielles :
Si vous utilisez un driver d’instruments ou communiquez directement avec des instruments à l’aide des drivers VISA ou IVI, utilisez Session Manager, sauf si vous avez un besoin précis de contrôler directement la durée de vie des sessions matérielles. Si vous utilisez un driver matériel tel que DAQmx, vous ne pouvez pas utiliser Session Manager et vous devez gérer les références manuellement.
Lorsque vous initialisez l’instrument, transmettez la référence de session en tant que paramètre de sortie à la séquence d’appel, puis stockez la référence dans une variable. Vous pouvez ensuite transmettre la variable comme entrée à chaque pas nécessitant un accès à l’instrument.
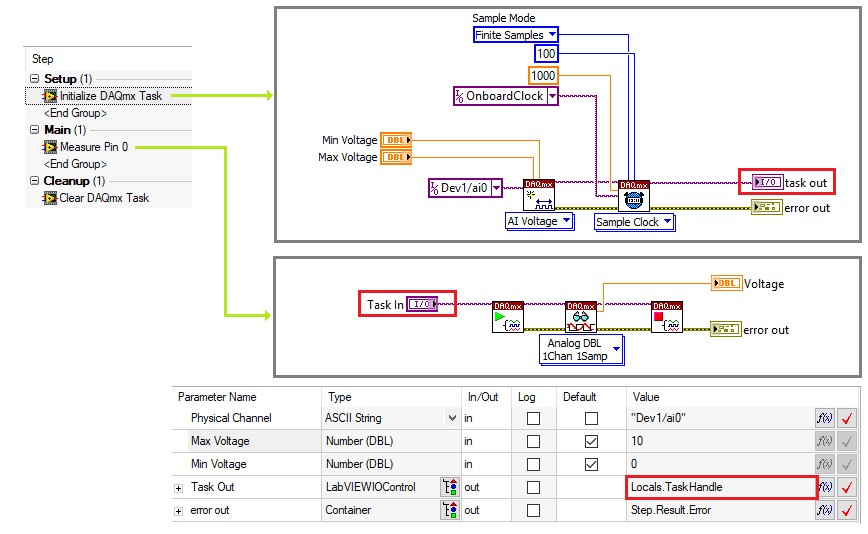
De nombreux drivers, notamment NI-DAQmx, VISA et la plupart des driver d’instruments, utilisent le type de données Référence d’E/S pour stocker les références de session. Utilisez le type de données LabviewIOControl dans TestStand pour stocker ces références.
Utilisez une variable avec le type LabVIEWIOControl pour passer des références matérielles, telles qu’une référence de tâche DAQ, entre les modules de code.
Lorsque vous transférez explicitement des pointeurs d’instruments entre TestStand et des modules de code, stockez la référence matérielle dans une variable locale. Si le matériel est utilisé sur plusieurs séquences, passez le pointeur en tant que paramètre de séquence à chaque séquence qui en a besoin. Évitez d’utiliser des variables globales pour stocker les références matérielles, car il peut être difficile de s’assurer que l’instrument a été initialisé avant d’utiliser la référence.
Utilisez le groupe de pas de test de configuration pour initialiser le matériel et le groupe de pas de test de nettoyage pour fermer les références matérielles pour les raisons suivantes :
Utilisez les groupes Configuration et nettoyage (Setup & Cleanup) pour initialiser et fermer les références matérielles.
Pour les pointeurs d’instruments VISA et IVI, vous pouvez utiliser Session Manager pour gérer automatiquement les références matérielles. L’utilisation de Session Manager offre de nombreux avantages, notamment :
Session Manager initialise automatiquement le pointeur après la création de la session et ferme automatiquement le pointeur lorsque la dernière référence à la session est libérée. Les modules de code et les séquences passent un nom logique, tel que « DMM1 », pour obtenir un objet de session à partir de Session Manager, qui contient le pointeur d’instrument correspondant.
Lorsque vous utilisez Session Manager, stockez l’objet de session dans une variable de référence d’objet TestStand. Étant donné que la durée de vie de la session est liée à la durée de vie de la variable de référence d’objet, le pointeur de l’instrument sera initialisé et fermé une fois par exécution, quel que soit le nombre de modules de code de séquence et de sous-séquences accédant à la même session.
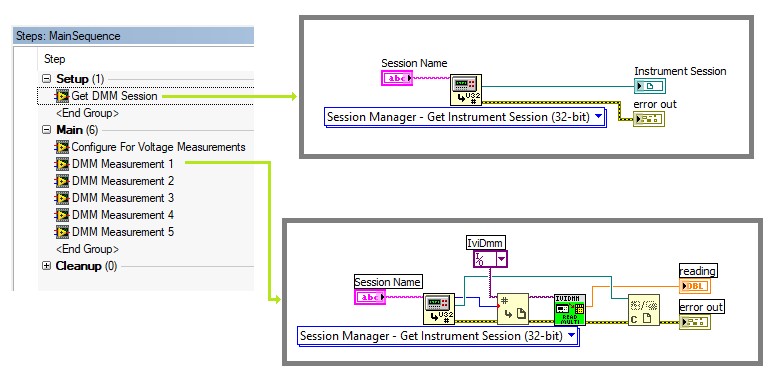
Dans l’exemple ci-dessous, le pas Obtenir une session DMM (Get DMM Session) obtient une référence à l’objet de session d’instrument pour le DMM pour le nom logique. Le pas stocke la référence de session dans une variable locale afin que la session reste initialisée pendant la durée de l’exécution de la séquence.
Utilisez Session Manager pour vous permettre de référencer des instruments à l’aide d’un nom logique. Le VI de Session Manager obtient la référence DMM IO en utilisant le nom logique.
Reportez-vous à l’aide de Session Manager NI, située dans <Program Files>\National Instruments\Shared\Session Manager, pour plus d’informations sur l’utilisation de Session Manager.
L’exemple de séquence précédent obtient la session à partir d’un module de code LabVIEW qui appelle Session Manager au lieu d’appeler Session Manager directement, car cet exemple a configuré l’adaptateur LabVIEW pour exécuter des VIs dans un processus distinct. Reportez-vous à l’aide de Session Manager NI, située dans <Program Files>\National Instruments\Shared\Session Manager, pour plus d’informations sur l’utilisation de Session Manager.
Pour communiquer avec tout type de matériel, vous utilisez des bibliothèques de drivers, qui fournissent un ensemble de fonctionnalités conçues pour vous permettre d’effectuer un ensemble de tâches à l’aide d’un langage de programmation. Lorsque vous utilisez des bibliothèques de drivers, vous appelez souvent plusieurs VIs ou fonctions pour effectuer une seule opération logique, comme prendre une mesure ou configurer un déclencheur. La création d’un module de code pour implémenter cette fonctionnalité, plutôt que d’appeler les fonctions de bibliothèque directement à partir d’un pas TestStand, présente plusieurs avantages :