From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
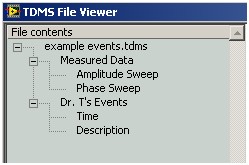
Les fichiers TDMS organisent les données dans une hiérarchie d’objets à trois niveaux. Le niveau supérieur est composé d’un seul objet qui contient des informations spécifiques au fichier comme l’auteur ou le titre. Chaque fichier peut contenir un nombre illimité de groupes et chaque groupe, un nombre illimité de voies. Dans l’illustration suivante, l’exemple de fichier events.tdms contient deux groupes, chacun contenant deux voies.
Chaque objet TDMS est identifié de manière unique par un chemin. Chaque chemin est une chaîne comprenant le nom de l’objet et le nom de son propriétaire dans la hiérarchie TDMS, séparés par une barre oblique. Chaque nom est entouré de guillemets. Tout guillemet simple dans un nom d’objet est remplacé par des guillemets doubles. Le tableau suivant illustre des exemples de formatage de chemin pour chaque type d’objet TDMS :
| Nom de l’objet | Objet | Chemin |
| -- | Fichier | / |
| Données mesurées | Groupe | /'Measured Data' |
| Balayage d’amplitude | Voie | /'Measured Data'/'Amplitude Sweep' |
| Dr. Événements T | Groupe | /'Dr. T’’s Events' |
| Temps | Voie | /'Dr. T’’s Events'/'Time' |
Pour que toutes les applications clientes TDMS fonctionnent correctement, chaque fichier TDMS doit contenir un objet fichier. Un objet fichier doit contenir un objet groupe pour chaque nom de groupe utilisé dans un chemin de voie. De plus, un objet fichier peut contenir un nombre arbitraire d’objets de groupe sans voies.
Chaque objet TDMS peut avoir un nombre de propriétés illimité. Chaque propriété TDMS est constituée d’une combinaison d’un nom (toujours une chaîne), d’un identificateur de type et d’une valeur. Les types numériques, comme les nombres entiers ou à virgule flottante, les horodatages ou les chaînes font partie des types de données typiques pour les propriétés. Les propriétés TDMS ne supportent pas les tableaux. Si un fichier TDMS se trouve dans une zone de recherche de NI DataFinder, toutes les propriétés sont automatiquement disponibles pour la recherche.
Seuls les objets de voies dans les fichiers TDMS peuvent contenir des tableaux de données brutes. Dans les versions TDMS actuelles, seuls les tableaux unidimensionnels sont pris en charge.
Chaque fichier TDMS contient deux types de données : les métadonnées et les données brutes. Les métadonnées sont des données descriptives stockées dans des objets ou des propriétés. Les tableaux de données attachés aux objets de voies sont appelés données brutes. Les fichiers TDMS contiennent des données brutes pour plusieurs voies dans un bloc contigu. Afin de pouvoir extraire des données brutes de ce bloc, les fichiers TDMS utilisent un index de données brutes, qui comprend des informations sur la composition du bloc de données, y compris la voie qui correspond aux données, la quantité de valeurs que le bloc contient pour cette voie, et l’ordre dans lequel les données ont été stockées.
Les données sont écrites dans des fichiers TDMS en segments. Chaque fois que des données sont ajoutées à un fichier TDMS, un nouveau segment est créé. Reportez-vous aux sections Métadonnées et Données brutes de cet article pour connaître les exceptions à cette règle. Un segment comporte les trois éléments suivants :
Toutes les chaînes des fichiers TDMS, telles que les chemins d’objet, les noms de propriété, les valeurs de propriété et les valeurs de données brutes, sont codées en Unicode UTF-8. Toutes, à l’exception des valeurs de données brutes, sont précédées d’un entier non signé 32 bits qui contient la longueur de la chaîne en octets, sans inclure la valeur de longueur elle-même. Les chaînes dans les fichiers TDMS peuvent être à terminaison nulle, mais comme les informations de longueur sont stockées, la terminaison null sera ignoré lorsque vous lirez le fichier.
Les horodatages dans les fichiers TDMS sont stockés sous la forme d’une structure de deux composants :
Les valeurs booléennes sont stockées dans 1 octet chacune, où 1 représente TRUE (VRAI) et 0 représente FALSE (FAUX).
Les attributs contiennent des informations utilisées pour valider un segment. Les attributs contiennent également des informations utilisées pour l’accès aléatoire à un fichier TDMS. L’exemple suivant montre l’encombrement binaire de l’attribut dans une partie d’un fichier TDMS :
| Structure binaire (hexadécimale) | Description |
| 54 44 53 6D | Tag "TDSm" |
| 0E 00 00 00 | Masque ToC 0x1110 (le segment contient la liste d’objets, les métadonnées, les données brutes) |
| 69 12 00 00 | Numéro de version (4713) |
| E6 00 00 00 00 00 00 00 | Offset du segment suivant (valeur : 230) |
| DE 00 00 00 00 00 00 00 | Offset des données brutes (valeur : 222) |
La partie des attributs dans le tableau précédent contient les informations suivantes :
| Option | Description |
| #define kTocMetaData (1L<<1) | Le segment contient des métadonnées |
| #define kTocRawData (1L<<3) | Le segment contient des données brutes |
| #define kTocDAQmxRawData (1L<<7) | Le segment contient des données brutes DAQmx |
| #define kTocInterleavedData (1L<<5) | Les données brutes du segment sont entrelacées (si le marqueur n’est pas défini, les données sont contiguës) |
| #define kTocBigEndian (1L<<6) | Toutes les valeurs numériques du segment, y compris l’attribut, les données brutes et les métadonnées, sont formatées en Big-endian (si le marqueur n’est pas défini, les données sont au format Little-endian). ToC n’est pas affecté par le format endian. Il est toujours au format Little-endian. |
| #define kTocNewObjList (1L<<2) | Le segment contient une nouvelle liste d’objets (par exemple, les voies de ce segment ne sont pas les mêmes voies que le segment précédent) |
Les métadonnées TDMS se composent d’une hiérarchie à trois niveaux d’objets de données, notamment un fichier, des groupes et des voies. Chacun de ces types d’objets peut inclure un nombre quelconque de propriétés. La section des métadonnées a la structure binaire suivante sur le disque :
La disposition binaire d’un seul objet TDMS sur disque se compose de composants dans l’ordre suivant. Selon les informations stockées dans un segment particulier, l’objet peut contenir uniquement un sous-ensemble de ces composants.
Le tableau suivant montre un exemple de méta-informations pour un groupe et une voie. Le groupe contient deux propriétés, une chaîne et un entier. La voie contient un indice de données brutes et aucune propriété.
| Empreinte binaire (hexadécimale) | Description |
| 02 00 00 00 | Nombre d’objets |
| 08 00 00 00 | Longueur du premier chemin d’objet |
| 2F 27 47 72 6F 75 70 27 | Chemin d’objet (/'Group') |
| FF FF FF FF | Indice des données brutes (« FF FF FF FF » signifie qu’aucune donnée brute n’est affectée à l’objet) |
| 02 00 00 00 | Nombre de propriétés pour /'Group' |
| 04 00 00 00 | Longueur du premier nom de propriété |
| 70 72 6F 70 | Nom de propriété (prop) |
| 20 00 00 00 | Type de données de la valeur de propriété (tdsTypeString) |
| 05 00 00 00 | Longueur de la valeur de la propriété (uniquement pour les chaînes) |
| 76 61 6C 75 65 | Valeur de la propriété prop (valeur) |
| 03 00 00 00 | Longueur du deuxième nom de propriété |
| 6E 75 6D | Nom de la propriété (num) |
| 03 00 00 00 | Type de données de la valeur de propriété (tdsTypeI32) |
| 0A 00 00 00 | Valeur de la propriété num (10) |
| 13 00 00 00 | Longueur du deuxième chemin d’objet |
| 2F 27 47 72 6F 75 70 27 2F 27 43 68 61 6E 6E 65 6C 31 27 | Chemin du deuxième objet (/'Group'/'Channel1') |
| 14 00 00 00 | Longueur des informations d’indice |
| 03 00 00 00 | Type de données des données brutes affectées à cet objet |
| 01 00 00 00 | Dimension du tableau de données brutes (doit être 1) |
| 02 00 00 00 00 00 00 00 | Nombre de valeurs de données brutes |
| 00 00 00 00 | Nombre de propriétés pour /'Group'/'Channel1' (n’a pas de propriétés) |
Le tableau suivant est un exemple de l’indice de données brutes DAQmx.
| Empreinte binaire (hexadécimale) | Description |
| 03 00 00 00 | Nombre d’objets |
| 23 00 00 00 | Longueur du chemin d’objet du groupe |
| 2F 27 4D 65 61 73 75 72 65 64 20 54 68 72 6F 75 67 68 70 75 74 20 44 61 74 61 20 28 56 6F 6C 74 73 29 27 | Chemin d’objet (/'Measured Throughput Data (Volts)') |
| FF FF FF FF | Indice des données brutes (« FF FF FF FF » signifie qu’aucune donnée brute n’est affectée à l’objet) |
| 00 00 00 00 | Nombre de propriétés pour /'Measured Throughput Data (Volts)' |
| 34 00 00 00 | Longueur du chemin d’objet de la voie |
| 2F 27 4D 65 61 73 75 72 65 64 20 54 68 72 6F 75 67 68 70 75 74 20 44 61 74 61 20 28 56 6F 6C 74 73 29 27 2F 27 50 58 49 31 53 6C 6F 74 30 33 2d 61 69 30 27 69 12 00 00 | /'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0' |
| 69 12 00 00 | Indice de données brutes DAQmx et contient une échelle à changement de format |
| FF FF FF FF | Type de données, données brutes DAQmx |
| 01 00 00 00 | Dimension des données |
| 00 00 00 00 00 00 00 00 | Nombre de valeurs, aucune valeur dans ce segment |
| 01 00 00 00 | Taille du vecteur des échelles à changement de format |
| 05 00 00 00 | Type de données DAQmx de la première échelle à changement de format |
| 00 00 00 00 | Indice de buffer brut de la première échelle à changement de format |
| 00 00 00 00 | Offset d’octets bruts dans la longueur |
| 00 00 00 00 | Exemple de format bitmap |
| 00 00 00 00 | ID d’échelle |
| 01 00 00 00 | La taille du vecteur de la largeur des données brutes |
| 08 00 00 00 | Premier élément du vecteur de la largeur des données brutes |
| 06 00 00 00 | Nombre de propriétés pour /'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0' |
| 11 00 00 00 | Longueur du premier nom de propriété |
| 4E 49 5F 53 63 61 6C 69 6E 67 5F 53 74 61 74 75 73 | Nom de la propriété ("NI_Scaling_Status") |
| 20 00 00 00 | Type de données de la valeur de propriété (tdsTypeString) |
| 08 00 00 00 | Longueur de la valeur de la propriété (uniquement pour les chaînes) |
| 75 6E 73 63 61 6C 65 64 | Valeur de la propriété prop ("unscaled") |
| 13 00 00 00 | Longueur du deuxième nom de propriété |
| 4E 49 5F 4E 75 6D 62 65 72 5F 4F 66 5F 53 63 61 6C 65 73 | Nom de la propriété ("NI_Number_Of_Scales") |
| 07 00 00 00 | Type de données de la valeur de propriété (tdsTypeU32) |
| 02 00 00 00 | Valeur de la propriété (2) |
| 16 00 00 00 | Longueur du troisième nom de propriété |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 53 63 61 6C 65 5F 54 79 70 65 | Nom de la propriété ("NI_Scale[1]_Scale_Type") |
| 20 00 00 00 | Type de données de la propriété (tdsTypeString) |
| 06 00 00 00 | Longueur de la valeur de la propriété |
| 4C 69 6E 65 61 72/span> | Valeur de propriété ("Linear") |
| 18 00 00 00 | Longueur du quatrième nom de propriété |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 53 6C 6F 70 65 | Nom de la propriété ("NI_Scale[1]_Linear_Slope") |
| 0A 00 00 00 | Type de données de la propriété (tdsTypeDoubleFloat) |
| 04 E9 47 DD CB 17 1D 3E | Valeur de propriété (1.693433E-9) |
| 1E 00 00 00 | Longueur du cinquième nom de propriété |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 59 5F 49 6E 74 65 72 63 65 70 74 | Nom de la propriété ("NI_Scale[1]_Linear_Y_Intercept") |
| 0A 00 00 00 | Type de données de la propriété (tdsTypeDoubleFloat) |
| 00 00 00 00 00 00 00 00 | Valeur de propriété (0) |
| 1F 00 00 00 | Longueur du sixième nom de propriété |
| 4E 49 5F 53 63 61 6C 65 5B 31 5D 5F 4C 69 6E 65 61 72 5F 59 6E 70 75 74 5F 53 6F 75 72 63 65 | Nom de la propriété ("NI_Scale[1]_Linear_Input_Source") |
| 07 00 00 00 | Type de données de la propriété (tdsTypeU32) |
| 00 00 00 00 | Valeur de propriété (0) |
Dans le tableau précédent, la voie "/'Measured Throughput Data (Volts)'/'PXI1Slot03-ai0" contient deux échelles. L’une est une échelle de changement de format. Ses informations sont stockées dans l’indice des données brutes DAQmx. L’autre échelle est une échelle linéaire, où les informations sont stockées en tant que propriétés TDMS. L’échelle de changement de format est identifiable lorsque la pente de l’échelle linéaire est 1.693433E-9, l’ordonnée à l’origine est 0 et l’identifiant de la source d’entrée est 0.
Les méta-informations qui correspondent aux méta-informations des segments précédents peuvent être omises dans les segments suivants. Ceci est facultatif, mais le fait d’omettre des méta-informations redondantes augmente considérablement la vitesse de lecture du fichier. Si vous choisissez d’écrire des informations redondantes, vous pouvez ensuite les supprimer en utilisant le nœud la fonction de défragmentation TDMS dans LabVIEW, LabWindows/CVI, MeasurementStudio, etc.
L’exemple suivant montre l’empreinte binaire pour la section de métadonnées d’un segment suivant directement le segment décrit ci-dessus. La seule méta-information écrite dans le nouveau segment est la nouvelle valeur de propriété.
| Structure binaire (hexadécimale) | Description |
| 01 00 00 00 | Nombre d’objets nouveaux/modifiés |
| 08 00 00 00 | Longueur du chemin de l’objet |
| 2F 27 47 72 6F 75 70 27 | Chemin d’objet (/'Group') |
| FF FF FF FF | Indice de données brutes (aucune donnée brute affectée à l’objet) |
| 01 00 00 00 | Nombre de propriétés nouvelles/modifiées |
| 03 00 00 00 | Longueur du nom de la propriété |
| 6E 75 6D | Nom de la propriété (num) |
| 03 00 00 00 | Type de données de la valeur de propriété (tdsTypeI32) |
| 07 00 00 00 | Nouvelle valeur pour la propriété num (7) |
Le segment contient enfin les données brutes associées à chaque voie. Les tableaux de données pour toutes les voies sont concaténés dans l’ordre exact dans lequel les voies apparaissent dans la partie méta-informations du segment. Les données numériques doivent être formatées en fonction du marqueur Little-endian/Big-endian dans l’attribut. Veuillez noter que les voies ne peuvent pas changer leur format endian ou type de données une fois qu’ils ont été écrits pour la première fois.
Les voies de type chaîne sont prétraitées pour un accès aléatoire rapide. Toutes les chaînes sont concaténées à un morceau de mémoire contigu. L’offset du premier caractère de chaque chaîne dans cette pièce de mémoire contiguë est stocké dans un tableau d’entiers 32 bits non signés. Ce tableau de valeurs offset est stocké en premier, suivi des valeurs de chaîne concaténées. Cette structure permet aux applications clientes d’accéder à n’importe quelle valeur de chaîne de n’importe où dans le fichier en repositionnant le pointeur de fichier au maximum trois fois et sans lire les données dont le client n’a pas besoin.
Si les méta-informations entre les segments ne changent pas, les parties d’attributs et de méta-informations peuvent être complètement omises et les données brutes peuvent simplement être ajoutées à la fin du fichier. Chaque tronçon de données brutes suivant a la même structure binaire, et le nombre de tronçons peut être calculé à partir des informations d’attributs et de métadonnées par les étapes suivantes :
Les données brutes peuvent être organisées en deux types de structure : intercalé et non intercalé. Le masque de bits ToC dans l’attribut du segment déclare si les données du segment sont intercalées ou non. Par exemple : le stockage de valeurs entières 32 bits sur les voies 1 (1,2,3) et 2 (4,5,6) entraîne les dispositions suivantes :
| Structure des données | Empreinte binaire (hexadécimale) |
| Non intercalé | 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 05 00 00 00 06 00 00 00 |
| Intercalé | 01 00 00 00 04 00 00 00 02 00 00 00 05 00 00 00 03 00 00 00 06 00 00 00 |
Le type d’énum suivant décrit le type de données d’une propriété ou d’une voie dans un fichier TDMS. Pour les propriétés, la valeur du type de données sera stockée entre le nom et la valeur binaire. Pour les voies, le type de données fera partie de l’indice de données brutes.
typedef enum {
tdsTypeVoid,
tdsTypeI8,
tdsTypeI16,
tdsTypeI32,
tdsTypeI64,
tdsTypeU8,
tdsTypeU16,
tdsTypeU32,
tdsTypeU64,
tdsTypeSingleFloat,
tdsTypeDoubleFloat,
tdsTypeExtendedFloat,
tdsTypeSingleFloatWithUnit=0x19,
tdsTypeDoubleFloatWithUnit,
tdsTypeExtendedFloatWithUnit,
tdsTypeString=0x20,
tdsTypeBoolean=0x21,
tdsTypeTimeStamp=0x44,
tdsTypeFixedPoint=0x4F,
tdsTypeComplexSingleFloat=0x08000c,
tdsTypeComplexDoubleFloat=0x10000d,
tdsTypeDAQmxRawData=0xFFFFFFFF
} tdsDataType;
Remarques :
Reportez-vous à l’article API basée sur VI pour l’écriture de fichiers TDMS pour plus d’informations sur les capacités d’écriture TDMS.
Les waveforms LabVIEW sont représentées dans les fichiers TDMS sous forme de voies numériques, où les attributs de waveforms sont ajoutés à la voie en tant que propriétés.
L’application de la définition de format décrite dans les sections précédentes crée des fichiers TDMS parfaitement valides. Cependant, TDMS permet une variété d’optimisations couramment utilisées par les logiciels NI tels que LabVIEW, LabWindows/CVI, MeasurementStudio, etc. Les applications qui tentent de lire des données écrites par le logiciel NI doivent prendre en charge les mécanismes d’optimisation décrits dans ce paragraphe.
Les méta-informations telles que les chemins d’objet, les propriétés et les indices bruts sont ajoutées à un segment uniquement si elles changent. Les méta-informations incrémentielles sont expliquées dans l’exemple suivant.
Dans la première itération d’écriture, les voies 1 et 2 sont écrites. Chaque voie a trois valeurs entières de 32 bits (1,2,3 et 4,5,6) et plusieurs propriétés descriptives. La partie méta-informations du premier segment contient des chemins, des propriétés et des indices de données brutes pour les voies 1 et 2. Les marqueurs kTocMetaData, kTocNewObjList et kTocRawData du champ de bits ToC sont définis. La première itération d’écriture crée un segment de données. Le tableau suivant décrit l’empreinte binaire du premier segment.
| Partie | Empreinte binaire (hexadécimale) |
| Attributs | 54 44 53 6D 0E 00 00 00 69 12 00 00 8F 00 00 00 00 00 00 00 77 00 00 00 00 00 00 00 |
| Nombre d’objets | 02 00 00 00 |
| Objet de méta-informations 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 76 61 6C 69 64 |
| Objet de méta-informations 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 |
| Voie de données brutes 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Voie de données brutes 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
Dans la deuxième itération d’écriture, aucune des propriétés n’a changé, les voies 1 et 2 ont toujours trois valeurs chacune et aucune voie supplémentaire n’est écrite. Par conséquent, cette itération n’écrira aucune métadonnée. Les métadonnées du segment précédent sont toujours supposées valides. Cette itération ne créera pas de nouveau segment; à la place, cette itération ajoute uniquement les données brutes au segment existant, puis met à jour l’offset du segment suivant dans la section Attributs. Le tableau suivant décrit l’empreinte binaire du segment mis à jour.
| Partie | Empreinte binaire (hexadécimale) |
| Attributs | 54 44 53 6D 0E 00 00 00 69 12 00 00 A7 00 00 00 00 00 00 00 77 00 00 00 00 00 00 00 |
| Nombre d’objets | 02 00 00 00 |
| Objet de méta-informations 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 76 61 6C 69 64 |
| Objet de méta-informations 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 03 00 00 00 00 00 00 00 00 00 00 00 |
| Voie de données brutes 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Voie de données brutes 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
| Voie de données brutes 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Voie de données brutes 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
Dans le tableau précédent, les deux dernières lignes contiennent des données ajoutées au premier segment lors de la deuxième itération d’écriture.
La troisième itération d’écriture ajoute trois autres valeurs à chaque voie. Dans la voie 1, le statut de la propriété a été défini sur valide dans le premier segment, mais doit maintenant être défini sur erreur. Cette itération créera un nouveau segment et la section de métadonnées de ce segment contient désormais le chemin d’objet pour la voie, le nom, le type et la valeur de cette propriété. Lors de futures lectures de fichiers, la valeur erreur remplacera la valeur valide précédemment écrite. Cependant, la valeur valide précédente reste dans le fichier, sauf si elle est défragmentée. Le tableau suivant décrit l’empreinte binaire du deuxième segment.
| Partie | Empreinte binaire (hexadécimale) |
| Attributs | 54 44 53 6D 0A 00 00 00 69 12 00 00 50 00 00 00 00 00 00 00 38 00 00 00 00 00 00 00 |
| Nombre d’objets | 01 00 00 00 |
| Objet de méta-informations 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 00 00 00 00 01 00 00 00 04 00 00 00 70 72 6F 70 20 00 00 00 05 00 00 00 65 72 72 6F 72 |
| Voie de données brutes 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Voie de données brutes 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
La quatrième itération d’écriture ajoute une voie supplémentaire, la tension, qui contient cinq valeurs (7,8,9,10,11). Cette itération créera un nouveau segment, le troisième segment, dans le fichier TDMS. Étant donné que toutes les autres métadonnées du segment précédent sont toujours valides, la section des métadonnées du quatrième segment inclut le chemin d’objet, les propriétés et les informations d’indice pour la tension de voie uniquement. La section des données brutes contient trois valeurs pour la voie 1, trois valeurs pour la voie 2 et cinq valeurs pour la tension de la voie. Le tableau suivant décrit l’empreinte binaire du troisième segment.
| Partie | Empreinte binaire (hexadécimale) |
| Attributs | 54 44 53 6D 0A 00 00 00 69 12 00 00 5E 00 00 00 00 00 00 00 32 00 00 00 00 00 00 00 |
| Nombre d’objets | 01 00 00 00 |
| Objet de méta-informations 3 | 12 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 76 6F 6C 74 61 67 65 27 14 00 00 00 03 00 00 00 01 00 00 00 05 00 00 00 00 00 00 00 00 00 00 00 |
| Voie de données brutes 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Voie de données brutes 2 | 04 00 00 00 05 00 00 00 06 00 00 00 |
| Voie de données brutes 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
Dans le quatrième segment, la voie 2 a maintenant 27 valeurs. Toutes les autres voies restent inchangées. La section des métadonnées contient maintenant le chemin d’objet pour la voie 2, le nouvel indice de données brutes pour la voie 2 et aucune propriété pour la voie 2. Le tableau suivant décrit l’empreinte binaire du quatrième segment.
| Partie | Empreinte binaire (hexadécimale) |
| Attributs | 54 44 53 6D 0A 00 00 00 69 12 00 00 BF 00 00 00 00 00 00 00 33 00 00 00 00 00 00 00 |
| Nombre d’objets | 01 00 00 00 |
| Objet de méta-informations 2 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 32 27 14 00 00 00 03 00 00 00 01 00 00 00 1B 00 00 00 00 00 00 00 00 00 00 00 |
| Voie de données brutes 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Voie de données brutes 2 | 01 00 00 00 02 00 00 00 03 00 00 00 04 00 00 00 05 00 00 00 06 00 00 00 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 0C 00 00 00 0D 00 00 00 0E 00 00 00 0F 00 00 00 10 00 00 00 11 00 00 00 12 00 00 00 13 00 00 00 14 00 00 00 15 00 00 00 16 00 00 00 17 00 00 00 18 00 00 00 19 00 00 00 1A 00 00 00 1B 00 00 00 |
| Voie de données brutes 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
Dans le cinquième segment, l’application arrête d’écrire sur la voie 2. L’application continue uniquement d’écrire sur la voie 1 et la tension de la voie. Cela constitue un changement dans l’ordre des voies, ce qui vous oblige à écrire une nouvelle liste de chemins de voies. Vous devez définir le bit ToC kTocNewObjList. La section des métadonnées du nouveau segment doit contenir une liste complète de tous les chemins d’objet, mais pas de propriétés ni d’indice de données brutes, à moins qu’ils ne changent également. Le tableau suivant décrit l’empreinte binaire du cinquième segment.
| Partie | Empreinte binaire (hexadécimale) |
| Attributs | 54 44 53 6D 0E 00 00 00 69 12 00 00 61 00 00 00 00 00 00 00 41 00 00 00 00 00 00 00 |
| Nombre d’objets | 02 00 00 00 |
| Objet de méta-informations 1 | 13 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 63 68 61 6E 6E 65 6C 31 27 00 00 00 00 00 00 00 00 |
| Objet de méta-informations 2 | 12 00 00 00 2F 27 67 72 6F 75 70 27 2F 27 76 6F 6C 74 61 67 65 27 00 00 00 00 00 00 00 00 |
| Voie de données brutes 1 | 01 00 00 00 02 00 00 00 03 00 00 00 |
| Voie de données brutes 3 | 07 00 00 00 08 00 00 00 09 00 00 00 0A 00 00 00 0B 00 00 00 |
Toutes les données écrites dans un fichier TDMS sont stockées dans un fichier avec l’extension *.tdms. Les fichiers TDMS peuvent être accompagnés d’un fichier d’indice facultatif *.tdms_index. Le fichier d’indice est utilisé pour accélérer la lecture du fichier *.tdms. Si une application NI ouvre un fichier TDMS sans fichier d’indice, l’application crée automatiquement le fichier d’indice. Si une application NI, telle que LabVIEW ou LabWindows/CVI, écrit un fichier TDMS, l’application crée le fichier d’indice et le fichier principal en même temps.
Le fichier d’indice est une copie exacte du fichier *.tdms, sauf qu’il ne contient aucune donnée brute et que chaque segment commence par un tag TDSh au lieu d’un tag TDSm. Le fichier d’indice contient toutes les informations pour localiser avec précision n’importe quelle valeur de n’importe quelle voie dans le fichier *.tdms.
En bref, le format de fichier TDMS est conçu pour écrire et lire des données mesurées à très grande vitesse, tout en conservant un système hiérarchique d’informations descriptives. Alors que la structure binaire en elle-même est plutôt simple, les optimisations activées en écrivant les métadonnées de manière incrémentielle peuvent conduire à des configurations de fichiers très sophistiquées.