What Is Reliability?
Overview
The acronym “RASM” encompasses four separate but related characteristics of a functioning system: reliability, availability, serviceability, and manageability. IBM is commonly noted [1] as one of the first users of the acronym “RAS” (reliability, availability, and serviceability) in the early data processing machinery industry to describe the robustness of its products. The “M” was recently added to RASM to highlight the key role “manageability” plays in supporting system robustness by facilitating many dimensions of reliability, availability, and serviceability. RASM features can contribute significantly to the mission of systems for test, measurement, control, and experimentation as well as their associated business goals.
Reliability is an essential part of our lives because it is related to trust. Can you trust something to function as expected? If you cannot trust your car, you probably won’t drive it on a cross-country trip for fear of being stranded on the side of the road. You would probably look for another, more reliable car or way to travel. If you cannot trust it (if it is not reliable), then you usually get rid of it and replace it with something that you can trust. This is obvious for more potentially life-threatening items like airplanes, automobile brake systems, and heating and cooling systems, but you also see this response for simple, less critical items as well. How long will you put up with a power drill that runs only half of the time or a cellphone that just randomly stops working? And they always seem to break down when you need to use them the most! Reliability is very important to all of us.
The roots of reliability as an engineering discipline can be traced back to the US military during World War II, when the reliability of complex mechanical systems became essential. A good understanding of the risks to reliability and prudent planning to move to favorable odds is key to a successful mission. In short, reliability is all about risk management.
Reliability engineering uses proven mathematical techniques from probability and statistics to assess and predict the reliability of a product under certain environmental conditions. Industry’s best practices for the continuous-improvement process are incorporated to help drive product reliability higher, and practical, good old common sense techniques are frequently applied to designs and manufacturing to increase reliability.
“Reliability is, after all, engineering in its most practical form.”
James R. Schlesinger - Former US Secretary of State for Defense
Contents
- Definition of Reliability
- Reliability for Each Phase of Life
- Phase 1: Pre-Life
- Phase 2: Early Life
- Phase 3: Useful Life
- Phase 4: Wear Out
- Summary
- Additional Resources
Definition of Reliability
Reliability
The definitions of reliability range from general and layman to exact and scientific. The more scientific definitions contain three basic components: the probability of success for a duration of time or cycles and for a defined environment.
This paper examines the following definition: “Reliability is the probability that a device or a system will function as expected without failure for a given duration in an environment.”
Reliability for Each Phase of Life
Consider the “bathtub curve” in Figure 1. This curve, named for its shape, depicts the failure rate over time of a system or a product. A product’s life can be divided into four phases: Pre-Life, Early Life, Useful Life, and Wear Out. During each phase, you must make different considerations to help avoid a failure at a critical or unexpected time because each phase is dominated by different concerns and failure mechanisms. Some of the failure mechanisms are listed in Figure 1.
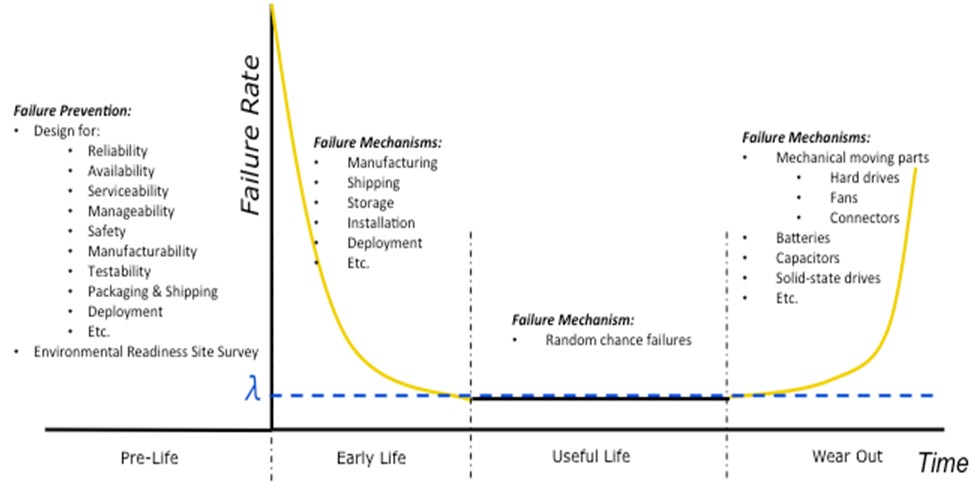
Figure 1. Bathtub Curve
Phase 1: Pre-Life
People don't plan to fail; they fail to plan!
- Benjamin Franklin
The focus during Pre-Life is planning and design. The design of a system has the greatest impact on its reliability. But to design appropriately, you must understand the level of reliability needed for a system.
To determine your reliability needs, consider the following list that is not comprehensive but contains the “big hitters.”
Cost of Failure
This is the most fundamental question that must be considered. It’s surprising how often the cost of failure of a system is not fully understood. This information helps drive how much you spend on the system or, in other words, how much reliability you can afford to have or not have. Consider the following when calculating or estimating the cost of failure:
Cost of Failure = Cost of Repair + Cost of Downtime + Cost of Damages
- Cost of Repair should include the cost to repair or the cost to replace parts and the cost of labor to do so
- Cost of Downtime should include the cost of loss production/sales and the cost of employees/customers not able to do their work
- Cost of Damages should include all cost associated with collateral harm to people, to the environment, to other equipment and products, and so on
Environment
The environment can have a significant effect on system reliability. Consider the following environmental factors:
- Quality of electrical power supplying the system
- Poor grounding
- Floating neutrals
- Voltage surges and spikes
- Brownouts
- Voltage sags
- Power outages
- Temperature levels and cycles
- Shock and vibration patterns
- Dirt and dust
- Humidity
- Cabling
- “Permanently” connected or disconnected and reconnected frequently?
- Bolted down?
- Human factors and usability
- The man-machine interface (MMI) has a significant impact on reliability and safety.
- Will the system be used in a high-traffic area?
- Can the system be easily bumped or kicked by accident?
- How will humans interact with the system—locally, remotely, or both?
- Will the operators be highly skilled and well trained or unskilled and virtually untrained?
- What levels of security and access do the critical areas of the system have? There are pros and cons to different levels, for example, easy access and less security can help lower repair times but they can also encourage untrained people to attempt to adjust/fix something they should not.
- Corrosive chemicals, salt spray, and so on
- Altitude
- High-energy radiation
- Electromagnetic radiation
Conducting an Environmental Readiness Site Survey (ERSS) prior to system installation and deployment is an effective way to evaluate many of these factors, and can help improve overall system reliability.
Usage Profile
This profile assesses the following factors that greatly affect reliability. You must consider it when calculating the reliability and availability.
- Mission time or the window of time the system needs to be in service without downtime
- Workload while in service
- Scheduled maintenance/planned downtime
- Frequency
- Duration
- If humans can access the system, how frequently can they do it? For example, a system on the South Pole or in a highly radioactive environment may not be accessible except for once per year. A system on an unmanned spacecraft heading for Mars cannot be accessed at all, but a test system on the factory floor can be accessed at almost anytime.
Other Considerations
Manufacturability—A system that is easy to build usually generates higher yields, fewer Early Life failures, and better reliability.
Testability—A system that is easy to test usually leads to more thorough testing, which translates into fewer Early Life failures, shorter repair times, and more effective maintenance (higher availability) during Useful Life.
Packaging—This is critical to reducing the damages that occur during shipment and storage. This also helps reduce Early Life failures.
Plan for System Verification and Validation (V&V) - You should implement system verification and validation in the actual target environment (if possible) and under the actual usage profile. The world around us is complex and impossible to completely model and predict. Like forecasting the weather, we are getting better at it, but prediction models still contain errors. Even though the system should work, you really don’t know it will until you try it.
Researching all of these factors helps you determine the risks and reliability design requirements for your system as well as choose the correct components for your system.
Phase 2: Early Life
Early Life is typically characterized by a higher than “normal” failure rate. These failures are referred to as “Infant Mortality,” and can be accelerated and exposed by a process called “Burn In,” which is typically implemented prior to system deployment. The higher failure rate is often attributed to manufacturing flaws, bad components not found during manufacturing test, or damage during shipping, storage or installation, and so on. The failure rate rapidly decreases as these issues are worked out.
Early Life failures can often be frustrating, time consuming, and expensive, leaving a poor first impression of the system quality. Thus, before the completion of deployment and “going live” with a production system, you should first test it in its actual target environment under the intended production usage profile. This Early Life testing basically ensures there are no damaged products. Although vendor manufacturing conducts final verification testing on each product before shipment, it cannot conduct final verification testing on products after shipment or on each complete system in the production environment. In addition to potential manufacturing errors not covered by manufacturing test, products can be damaged during shipment, storage, or installation and deployment.
Phase 3: Useful Life
Useful Life is when the system’s Early Life issues have been worked out and the system is trusted for normal operation. During this phase, failures are considered to be “random chance failures,” which typically yield a constant failure rate. Useful Life continues until the product life cycle reaches the Wear Out phase.
During Useful Life, you apply the concepts of reliability, availability, serviceability, and manageability (RASM) engineering. The failure rate “λ” or mean time between failure (MTBF) is considered to be constant, that:
[2]
Have you ever wondered why a hard drive has a MTBF of 1 million hours (over a 100 years) but wears out after three to four years of use? So what does MTBF really mean?
The short answer is that MTBF does NOT account for Early Life or Wear Out failures but only random chance failures that are present during Useful Life. Thus, its sole purpose is to calculate the probability of success (reliability) and the probability of being ready to do its job (availability) during Useful Life. MTBF should not be used to calculate how long the system should last (when the system will enter Wear Out).
Reliability (R(t)) is defined as the probability that a device or a system will function as expected for a given duration in an environment. Duration is usually measured in time (hours), but it can also be measured in cycles, iterations, distance (miles), and so on. The reliability formula used for Useful Life, when the failure rate is constant, is:
[3]
t = Mission Time, Duration
Note: However, if the failure rate is not constant, then the above equation does not apply.
Once you have calculated the reliability of a system in an environment, you can calculate the unreliability (the probability of failure). Since the system has two states, functioning as expected or not, the two states are complementary [4]. The probability of success “R(t)” and the probability of failure “F(t)” are equal to 1. This topic is addressed in detail in the RASM Series white paper “The Mathematics of Reliability.”
[5]
Thus
Example:
A system has an MTBF of 300,000 hours. What is the predicted reliability for a six-month mission?
6 months = 4380 hours
The reliability (the probability of success) is predicted to be 98.55%.
What is the predicted probability of failure at 4380 hours?
The probability of failure is predicted to be 1.45%.
The probability of failure represents the risk of failure and can be used to help plan for the number of spares needed. Along with this information, you need to understand the usage profile and the mean time to repair (MTTR). Sparing and MTTR are addressed in other RASM Series white papers.
A strong understanding of Useful Life characteristics is key to planning a “sparing strategy” for the system.
Phase 4: Wear Out
The Wear Out phase begins when the system’s failure rate starts to rise above the “norm.” The increasing failure rate is due to expected part wear out. Usually mechanical moving parts like fans, hard drives, switches, and frequently used connectors are the first to fail. However, electrical components such as batteries, capacitors, and solid-state drives can be the first to fail as well. Most integrated circuits (ICs) and electronic components last about 20 years [6] under normal use within their specifications.
During the Wear Out phase of life, the reliability is compromised and difficult to predict. How to predict when will your system wear out is addressed in many reliability books and considered by many to fall under the discipline of Reliability Engineering, some textbooks organize this subject under the discipline of Durability. This information can be valuable for developing preventive maintenance strategies and replacement plans.
Summary
- Reliability predictions are a powerful tool for risk management.
- The four phases of life for a system are Pre-Life, Early Life, Useful Life, and Wear Out.
- Pre-Life is focused on understanding the level of reliability you need and planning for it.
- Understanding the cost of failure is critical.
- An ERSS helps you understand your risks and the level of reliability you need.
- Early Life is focused on testing to ensure the system(s) is ready to be commissioned into service.
- MTBF should not be used for predicting when a product will wear out.
- MTBF and MTTR can be used to predict reliability and availability during Useful Life. They can also be combined with usage profiles to determine the number of spares needed.
Additional Resources
View the entire RASM white paper series
[1] “Design and Evaluation,” 3rd ed., by Daniel P. Siewiorek and Robert S. Swarz, Reliable Computer Systems (A K Peters/CRC Press, 1998).
[2] "Reliability Theory And Practice", by Igor Bazovsky, Prentice-Hall, Inc. 1961, Library of Congress Catalog Card Number: 61-15632, Chapter 5, page 33
[3] "Reliability Theory And Practice", by Igor Bazovsky, Prentice-Hall, Inc. 1961, Library of Congress Catalog Card Number: 61-15632, Chapter 3, page 19
[4] “Certified Reliability Engineer Primer”, Quality Council of Indiana Fourth Edition, October 1, 2009, p. III-13
[5] “Practical Reliability Engineering” Fifth Edition, by Patrick D. O’Conner and Andre Kleyner, Wiley, ISBN 978-0-470-97981-5, Chapter 2, page 32
[6] “Telcordia Technologies Special Report, SR-332”, Issue 1, May 2001, Section 2.4, page 2-3