From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
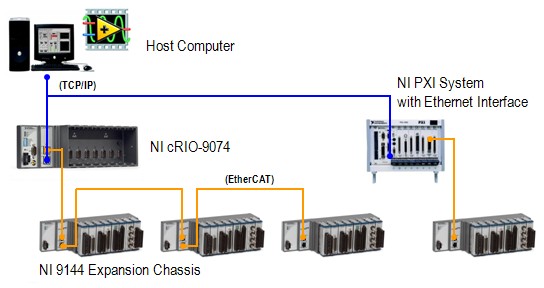
Das rekonfigurierbare NI EtherCAT I/O (RIO) Erweiterungschassis wurde entwickelt, um synchronisierte, verteilte I/O über ein deterministisches Netzwerk bereitzustellen. Das mit dem NI LabVIEW Real-Time Module programmierte Chassis kann mit programmierbaren NI-Echtzeit-Automatisierungscontrollern (Programmable Automation Controller, PACs) mit zwei Ethernet Ports auf den folgenden Plattformen als Daisy Chain verbunden werden: NI CompactRIO-, PXI- und NI-Industrie-Controller. Darüber hinaus verfügt jedes EtherCAT RIO Chassis über ein FPGA (Field-Programmable Gate Array), das Sie mit dem LabVIEW FPGA Module für intelligente, verteilte Geräte programmieren können, die benutzerdefiniertes Timing und Inline-Verarbeitung ermöglichen. In diesem Whitepaper werden die technischen Details und Leistungsdaten der NI 9144 System-Loop-Rate-Benchmarks unter Verwendung der NI Scan Engine in LabVIEW Real-Time genauer beleuchtet.
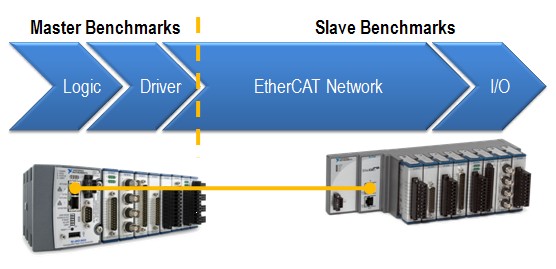
Das Kommunikationsnetzwerk zwischen dem Master-Controller und dem NI 9144 basiert auf einem offenen Echtzeit-Ethernet-Protokoll namens EtherCAT. Grundsätzlich betrachtet bestehen die EtherCAT-Benchmarks aus vier Komponenten: Logik, Treiber, EtherCAT-Netzwerk und I/O.
Abbildung 2: Bestandteile des Master- und Slave-Benchmarks
Für das EtherCAT-Master-Gerät hängen die Master-Benchmarks vom Programmcode des Benutzers und dem EtherCAT-Treiber ab, der Daten zwischen dem Programmcode und dem EtherCAT-Netzwerk überträgt. Generell ist der EtherCAT-Master-Controller meist der begrenzende Faktor bei den System-Loop-Raten, da seine Verarbeitungsleistung einen großen Einfluss darauf hat, wie schnell die Daten in der Benutzerlogik und im Treiber verarbeitet werden. Je leistungsfähiger der Controller ist, desto mehr I/O-Daten kann er in kürzerer Zeit verarbeiten.
Die Benchmarks für die Slave-Geräte hingegen hängen davon ab, wie lange das Paket im EtherCAT-Netzwerk unterwegs ist und wie schnell die Slave-I/O aktualisiert werden können. Die Paketgeschwindigkeit des EtherCAT-Netzwerks wird durch viele Faktoren beeinflusst, z. B. durch die Anzahl der Slave-Geräteknoten, die Länge des Ethernet-Kabels und vor allem durch die Menge der I/O-Daten, die über die Verbindung übertragen werden. Da es sich um ein deterministisches Protokoll handelt, wird das Timing des EtherCAT-Netzwerks genau berechnet, so dass der Master genau weiß, wann die Slave-Geräte Daten aktualisieren und übertragen. Wenig überraschend ist die Geschwindigkeit des EtherCAT-Netzwerks die schnellste Komponente der gesamten Systemschleifenrate.
Wenn Sie das NI 9144 EtherCAT RIO Chassis mit NI PACs verwenden, entsprechen diese Benchmark-Komponenten den folgenden Komponenten:
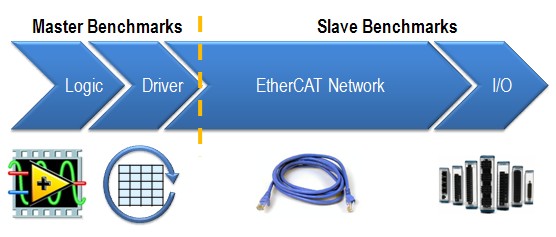
Die Logik besteht aus dem vom Benutzer erstellten Programmcode in LabVIEW, und der Treiber bezieht sich auf die NI Scan Engine in der Software LabVIEW und NI-Industrial Communications for EtherCAT. Das EtherCAT-Netzwerk dient der Kommunikation über das physikalische Ethernet-Kabel, und I/O bezieht sich auf die I/O-Module der C-Serie. Die Gesamtheit dieser Software- und Hardwarekomponenten macht die gesamte Systemschleifenrate Ihres NI-Systems aus.
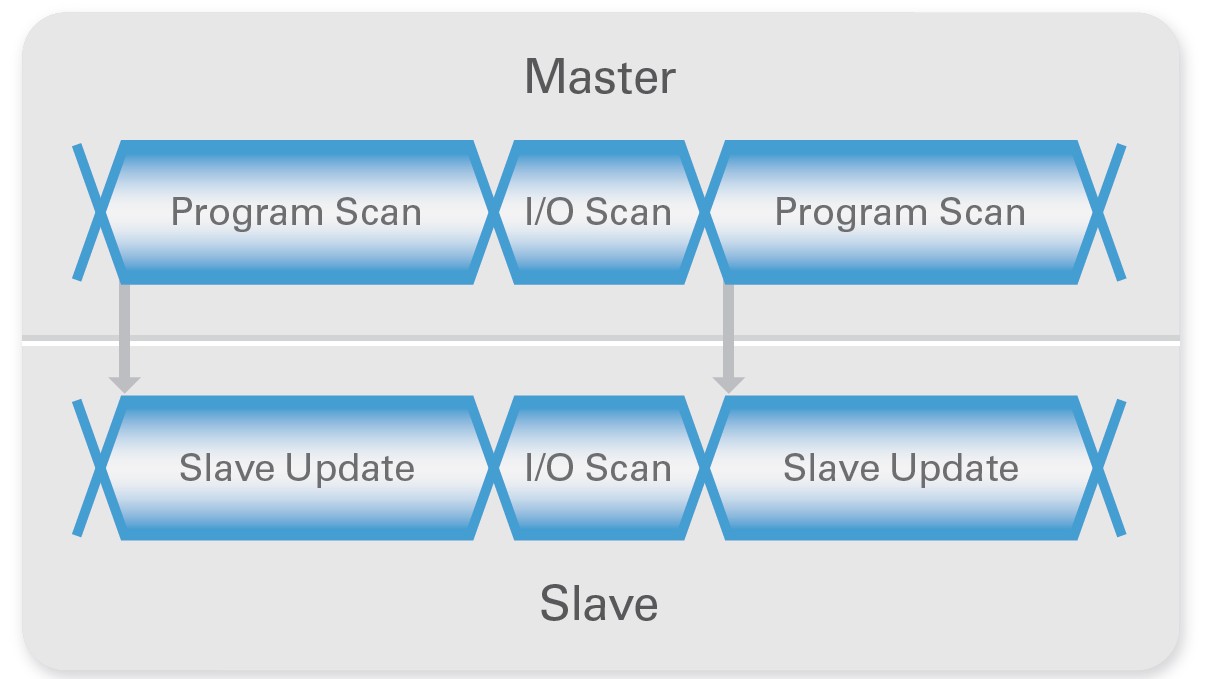
Während einer einzelnen Scan-Schleife oder eines Zyklus muss die Übertragung des EtherCAT-Pakets oder der I/O-Scan zwischen dem Master-Controller und dem NI 9144 Slave-Chassis synchronisiert werden. Während des I/O-Scans sendet der Master ein Paket mit neuen Ausgängen und Anweisungen für die Slaves aus, und die Slaves senden das Paket mit neuen Eingangswerten für den Master zurück. Mit den aktualisierten Daten aus dem EtherCAT-Paket startet der Master den Programmscan und die NI 9144 Chassis beginnen mit der Aktualisierung der Slaves. Der Programmscan beschreibt die Zeit, die der Master benötigt, um Daten zu verarbeiten und das LabVIEW-Programm auszuführen. Die Slave-Aktualisierung ist die Zeit, die der Slave für DMA-Übertragungen, Datenverarbeitung und I/O-Aktualisierung verwendet. Daher wird die minimale Schleifenrate entweder durch den Programm-Scan oder die Slave-Aktualisierung begrenzt, je nach dem welche von beiden mehr Zeit benötigt.
Abbildung 4: Scan-Timing-Diagramm
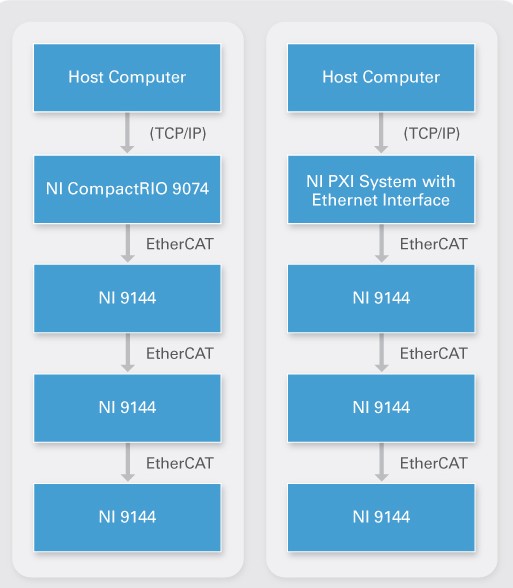
Die Programmabfragezeit steigt mit der Anzahl der Slaves und I/O im Netzwerk, da der Master-Controller mehr Daten zu verarbeiten hat. Die Aktualisierungszeit der Slaves erhöht sich jedoch nicht, da die Slaves ihre I/Os gleichzeitig und parallel aktualisieren. Je mehr Slave I/O im Netzwerk vorhanden sind, desto wahrscheinlicher ist es, dass die Programmabfrage des Masters zum Nadelöhr wird. Wenn Ihre Anwendung eine hohe Anzahl von I/O-Kanälen erfordert, sollten Sie einen Hochleistungscontroller wie PXI für den Master verwenden.
Abbildung 5: CompactRIO- und PXI-Systeme mit NI 9144-Chassis
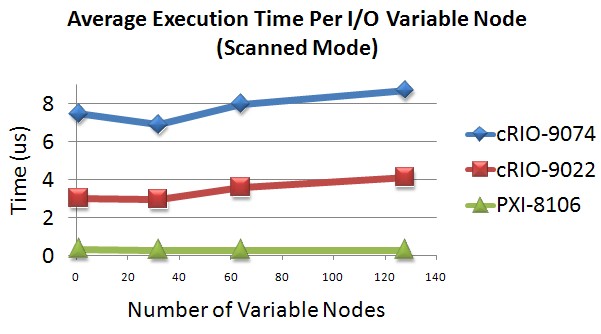
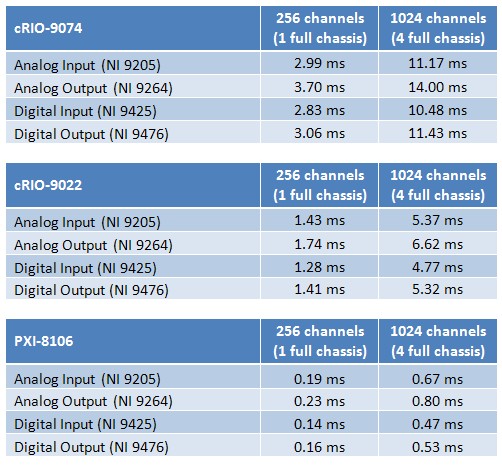
Der standardmäßige LabVIEW-Programmiermodus für den Master-Controller besteht darin, die NI Scan Engine auszuführen. Dabei handelt es sich um eine Komponente von LabVIEW Real-Time, die Einzelpunkt-I/O-Werte mit einer vom Benutzer festgelegten Rate in den Speicher scannt. Für die Zwecke der Master-Controller-Benchmarks wird die für das Ausführen des Programmcodes des Benutzers benötigte Zeit nicht berechnet. Die verbleibende Master-Benchmark-Komponente ist daher die Treibergeschwindigkeit, welche die Zeit beinhaltet, die der Controller benötigt, um Daten zwischen der NI Scan Engine Memory Map und der I/O-Variablen zu übertragen. I/O-Variablen werden verwendet, um auf Daten aus der NI Scan Engine Memory Map zuzugreifen. Jede Instanz eines I/O-Variablenknotens in einem LabVIEW VI benötigt Zeit für die Ausführung. Die durchschnittliche Ausführungszeit jedes I/O-Variablenknotens bleibt in der Regel konstant, auch wenn die Knotenanzahl im Blockdiagramm steigt. Das Diagramm in Abbildung 6 zeigt diese Ausführungszeit für bestimmte Master-Controller. Basierend auf diesen Daten beträgt die durchschnittliche Ausführungszeit pro I/O-Variablenknoten ca. 8 µs für das integrierte System NI cRIO-9074, 3,5 µs für den Embedded-Real-Time-Controller NI cRIO-9022 und 0,3 µs für den Dual-Core-Embedded-Controller NI PXI-8106.
Abbildung 6: Durchschnittliche Ausführungszeit je I/O-Variablenknoten
Hinweis: Dies ist keine umfassende Liste aller kompatiblen NI-Controller. Weitere Informationen erhalten Sie in der Auswahlhilfe für deterministische Ethernet-Produkte. Im Allgemeinen gilt: Je leistungsfähiger der Prozessor, desto schneller die Ausführung der I/O-Variablen.
Kunden fragen oft nach der maximalen Anzahl von NI 9144 Chassis, die sie vom Master-Controller aus in einer Daisy Chain aneinanderreihen können. Theoretisch sieht das EtherCAT-Protokoll vor, dass die maximale Anzahl von Slaves in einem Netzwerk 65.535 Geräte beträgt. Wenn jedoch so viele Geräte von einem Master-Controller gesteuert werden, verlangsamt sich die Scan-Rate beträchtlich, und es ist wahrscheinlich am besten, stattdessen mehrere Master zu verwenden. In Wirklichkeit hat die Anzahl der I/O-Kanäle, nicht die Anzahl der Slave-Geräte, mehr Einfluss auf die Systemabtastrate von Seiten des Masters. Wie in Abbildung 4 zu sehen ist, erhöht sich die Programmabfrage des Masters, wenn mehr Daten über das EtherCAT-Netzwerk übertragen werden, und überlagert in der Regel die Aktualisierungszeit des Slaves. Daher haben 300 I/O-Kanäle, die auf zwei oder 20 NI 9144 Chassis verteilt sind, trotz des zusätzlichen Aufwands für jedes Slave-Gerät ungefähr die gleiche Systemschleifenrate.
In Tabelle 1 sind die Benchmarks für den Master-Controller und den NI 9144 zusammengefasst, um die minimale Zykluszeit bzw. die Systemschleifenrate zu ermitteln.
Mindestzykluszeit = Treiber + EtherCAT-Netzwerk + I/O-Updates
Beachten Sie, dass diese Benchmarks nicht die Zeit berücksichtigen, die der Programmcode des Benutzers zum Ausführen benötigt. Fügen Sie also die entsprechende Zeit für den Programmcode hinzu und lesen Sie die zugehörigen Links unten um weitere Informationen zu erhalten.
Tabelle 1: Systemschleifenraten
Auf der Grundlage der Tests für diese beiden Controller und vier verschiedene I/O-Module ist am Ende dieses Whitepapers eine Tabelle zum Benchmarking mit der Bezeichnung system_loop_rate_chart2.xls angehängt, mit deren Hilfe Sie die Systemschleifenrate für Ihre Konfiguration näherungsweise bestimmen können. Geben Sie einfach die Anzahl der von Ihnen verwendeten analogen und digitalen I/O-Kanäle sowie die ungefähre Zeit für das Ausführen des LabVIEW Programmcodes zur Berechnung der Systemschleifenrate ein. Beachten Sie, dass diese Formeln auf einer bestimmten Hardwarekonfiguration beruhen und die Ergebnisse bei Verwendung anderer I/O-Module abweichen können.
Sie können das Erweiterungschassis NI 9144 auch mit anderen EtherCAT-Mastern von anderen Herstellern verwenden, allerdings ohne die benutzerfreundliche Programmiererfahrung von LabVIEW. In derartigen Fällen werden Benchmarks nur für den NI 9144 und das EtherCAT-Netzwerk ohne Master-Benchmark-Komponenten bereitgestellt. Bedenken Sie, dass dies die minimale erreichbare Zykluszeit ist. Um die tatsächliche Systemschleifenrate zu berechnen, müssen Sie die Scan- und Ausführungszeiten des Master-Programms ermitteln und vergleichen. Die Formel besteht aus zwei Teilen:
Minimale Slave-Zykluszeit = Paketübertragungszeit + Slave-Aktualisierungszeit
Sobald das EtherCAT-Paket den Master verlässt, entspricht die Paketübertragungszeit der Summe aus Frame-Übertragung, Kommunikationsverzögerung und eventuellem Jitter auf dem Weg dorthin.
Paketübertragungszeit = Frame-Übertragungszeit + Kommunikationsverzögerung + Jitter
Die Frame-Übertragung verursacht 80 ns pro Byte der EtherCAT-Daten sowie 5 µs für jeden EtherCAT-Frame, der die Daten trägt. (Diese gesamten EtherCAT-Daten stehen in direktem Zusammenhang mit der Anzahl und dem Typ der I/O-Kanäle im NI 9144 Chassis). Die Kommunikationsverzögerung beträgt 600 ns für jedes NI 9144 Chassis und 5 ns je Meter Ethernetkabel.
Nachdem das EtherCAT-Paket ohne Unterbrechung durch alle Slaves und zurück zum Master gestreamt wurde, lesen alle Slaves parallel Eingänge und schreiben Ausgänge. Daher ist das Slave-Gerät mit der ungünstigsten Slave-Aktualisierungszeit für die minimale Slave-Zykluszeit für Ihr System ausschlaggebend.
Slave-Aktualisierungszeit = DMA-Übertragungszeit + Modul-Timing im schlimmsten Fall
Um diese zu ermitteln, müssen Sie die individuellen Modulkonfigurationen für alle NI 9144 Chassis berücksichtigen. Basierend auf den Modulen im Chassis können Sie die DMA-Übertragungszeit für Eingangs- und Ausgangsdaten berechnen. Sie können auch das Modul mit dem ungünstigsten Timing für die Initiierung, Konvertierung und Brechung bestimmen. Ermitteln Sie die Slave-Aktualisierungszeit im schlimmsten Fall, indem Sie diese Werte addieren.
Hinweis: Seit der Veröffentlichung von LabVIEW 2009 können Sie die Module im NI 9144 auf der Hardwareebene mit dem LabVIEW FPGA Module programmieren. Daher können Sie die Vorteile von Modulen nutzen, die schnellere Aktualisierungsraten besitzen als die Systemschleifenrate. Indem Sie die I/O mit der maximalen Geschwindigkeit des Moduls erfassen, nutzen Sie den Programmcode des FPGA, um benutzerdefinierte Signalmanipulationen und Inline-Verarbeitungen vorzunehmen und das Endergebnis dann an den Master-Controller zurückzugeben.
Da Sie viele verschiedene Kombinationen von Modulen mit dem NI 9144 verwenden können, finden Sie unten eine weitere Tabelle mit Benchmarks (ni_9144_only_benchmarks.xls), in der Sie alle diese Formeln anwenden und die minimale Slave-Zykluszeit genau berechnen können. Sobald Sie die korrekten Werte eingegeben haben, addieren Sie die Benchmarks des Masters von anderen Herstellern zu den berechneten Slave-Benchmarks, um die gesamte Systemaktualisierungsrate für die Anwendung zu ermitteln. Für eine zusätzliche Steigerung der Hochgeschwindigkeitsleistung nutzen Sie die LabVIEW FPGA-Funktionen, um benutzerdefinierte Informationen auf den NI 9144 zu laden.