Artificial Intelligence in Software-Defined SIGINT Systems
Overview
The combination of wideband front ends and powerful processors makes software defined radios an ideal platform for signals intelligence applications. Artificial intelligence and deep learning techniques can train a system to detect signals faster than hand-coded algorithms. Learn how DeepSig applies artificial intelligence and deep learning (DL) with COTS SDR.
Contents
- Artificial Intelligence and Deep Learning with COTS SDR
- SDR Hardware Architectures
- AI and Radio
- AI in Deployed Systems
- Why SDR for SIGINT?
Artificial Intelligence and Deep Learning with COTS SDR
The hostile environment represents an optimization problem that quickly becomes unmanageable. Fully optimizing RF systems with this level of complexity has never been practical. Designers have relied on simplified closed-form models that don’t accurately capture real-world effects and have fallen back on piecemeal optimization, wherein individual components are optimized, but full end-to-end optimization is limited.
In the last few years, there have been significant advances in AI, especially in the DL class of machine-learning techniques. Where human designers have toiled at great effort to hand-engineer solutions to difficult problems, DL directly targets large sets of complex, problem-specific data.
SDR Hardware Architectures
There are typically two types of COTS cognitive radio (CR) systems for defense:
- Compact, deployed systems in the field that use AI to determine actionable intelligence in real time. These systems utilize FPGAs and general-purpose processors (GPPs), sometimes with the addition of a compact graphics-processing unit (GPU) module.
- Modular, scalable, more compute-intensive systems typically consisting of CRs coupled to high-end servers with powerful GPUs for offline processing. These systems frequently require larger-form-factor RF instruments, and increased data volumes often require higher throughput buses, such as PCIe.
For low size, weight, and power systems (low-SWaP), FPGA hardware-processing efficiency and low-latency performance, coupled with GPP programmability, makes a lot of sense. While the FPGA may be more complicated to program, it is key to achieving low SWaP in real-time systems. In this situation, Universal Software Radio Peripherals (USRPs) from National Instruments and Ettus Research provide an off-the-shelf platform in a compact form factor. User-programmable FPGAs are an inherent aspect of USRP devices, and direct integration with either LabVIEW or open-source software, such as RF Network on Chip (RFNoC), alleviates the challenge of programming the FPGA in a hardware description language.
For larger compute-intensive systems, it is important to have a hardware architecture that scales and can heterogeneously utilize best-in-class processors. These architectures typically comprise FPGAs for baseband processing, GPPs for control, and GPUs for AI processing. GPUs offer a nice blend of being able to process massive amounts of data while being relatively easy to program. A downside of GPUs is their long data pipelines, which lead to higher transfer times, although this is only an issue in systems that require ultra-low latency. Of course, there are ranges of devices within each category that trade power at the expense of performance, which you should weigh up in design analysis.
| Processor Type | SWaP | Real-Time | Ease of Use |
|---|---|---|---|
| GPP | Typically large and power hungry | Nonoptimal latency and determinism; improved by using a real-time OS (though that adds development complexity) | Easiest to program with LabVIEW, C/C++, or Python |
| FPGA | Generally SWaP-friendly | Low latency | Typically difficult to program with hardware description languages; simplified through tools in C/C++, OpenCL, LabVIEW, or RFNoC |
| GPU | Typically large and power hungry | Typically higher latency | Easy to program with TensorFlow or OpenCL/CUDA |
Table 1. Processor Options for Cognitive Radio
An example of a larger compute-intensive system is the DARPA Colosseum testbed used in the Spectrum Collaboration Challenge. This system includes 128 two-channel USRPs (Ettus X310) with onboard FPGAs, ATCA-3671 blades with multiple FPGAs for data aggregation, and high-end servers with powerful GPUs for AI processing.

Figure 1. The DARPA Colosseum testbed features 128 Ettus X310 USRPs and NI ATCA-3671 processing units.
AI and Radio
To understand how AI can address RF system design complexity, it’s helpful to have a high-level knowledge of recent advances that have driven the AI-based system explosion. The term “AI” has been used for decades, and broadly encompasses problem solving where a machine is making decisions to find a solution. Machine learning (ML) refers to a type of AI where a machine is trained with data to solve a specific problem. DL is a class of ML capable of “feature learning,” a process whereby the machine determines what aspects of data to use in decision making, as opposed to a human designer specifying salient characteristics.
For example, designers historically hand-coded facial recognition algorithms based on years of feature-recognition technique research. The DL approach combines a data set of images containing human faces with operator training to point out where the faces are. The machine learns to recognize what constitutes a face, without a designer defining the algorithm.
Similarly, RF signal classification and spectrum-sensing algorithms can benefit hugely from DL methods. Whereas previous automatic modulation classification (AMC) and spectrum-monitoring approaches required labor-intensive efforts to hand-engineer feature extraction (often taking teams of engineers months to design and deploy), a DL-based system can train for new signal types in hours.
DL also permits end-to-end learning, whereby a model jointly learns an encoder and decoder for a complete transmit-and-receive system. Instead of needing to attempt to optimize a system in piecemeal fashion by individually tuning each component (such as digital-to-analog converters [DACs], analog-to-digital converters [ADCs], RF converters, wireless channel, and receiver network) and stitching them together, the model treats the system as an end-to-end function and learns to optimize the system holistically.
AI in Deployed Systems
Performing signal detection and classification using a trained deep neural network takes a few milliseconds. Compared to iterative and algorithmic signal search, detection, and classification using traditional methodologies, this can represent several orders of magnitude in performance improvement. These gains also translate to reduced power consumption and computational requirements, and the trained models typically provide at least twice the sensitivity of existing approaches.
DeepSig, a US-based startup focused on signal processing and radio systems, has commercialized DL-based RF sensing technology in its OmniSIG Sensor software product, which is compatible with NI and Ettus Research USRPs. Using DL’s automated feature learning, the OmniSIG sensor recognizes new signal types after being trained on just a few seconds' worth of signal capture.
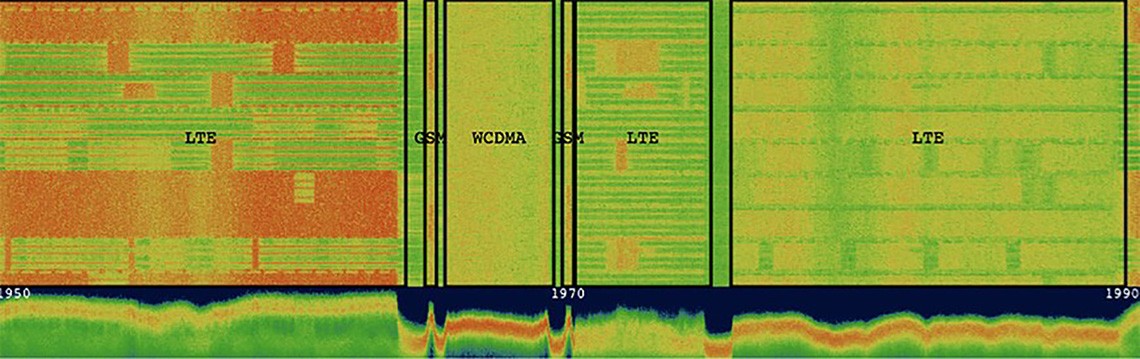
Figure 2. The OmniSIG sensor performs detection and classification of signals within the cellular band, using a general-purpose SDR.
For learned communications systems, including end-to-end learning that facilitates training directly over the physical layer, you can use DeepSig’s OmniPHY software to learn communications systems optimized for difficult channel conditions, hostile spectrum environments, and limited hardware performance. These include non-line-of-sight communications; antijam capabilities; multiuser systems in contested environments; and hardware-distortion-effect mitigation.
One of the advantages of learned communications systems is easy optimization for different missions. While many users care most about throughput and latency, some might prioritize operational link distance, power consumption, or even signature and probability of detection or interception. Moreover, with machine learning, the more you know about the operational environment, the more effective your trained solution can be.
Combining DL-based sensing and active radio waveforms makes possible entirely new classes of adaptive waveforms and EW capable of coping with today’s contested spectrum environments. For DL-based system training, processor performance is key, but once trained, the model can readily be deployed into low-SWaP embedded systems, such as edge sensors and tactical radios.
Why SDR for SIGINT?
SDR’s core elements—RF front ends and processing units—make it ideal for prototyping and deploying AI-based signals intelligence systems. USRP’s low SWaP makes it well suited to communications intelligence deployment, for detecting signals at sub-6 GHz frequency.
For higher frequencies and computationally intensive applications, PXI platform instrumentation extends to mmWave frequencies to address up to Ka band, greater data throughput across x8 PCIe links, and massive processing with ATCA modules employing multiple Xilinx Virtex-7 FPGAs.
Detecting adverse signals at unknown frequencies—which could include using spread-spectrum or frequency-hopping techniques—requires wideband receivers. COTS SDRs integrate the latest wideband ADCs and DACs to address this. Additionally, you can form multichannel systems to either extend the effective bandwidth by tuning receiver channels to adjacent bands or share local oscillators to affect phase coherence across channels. This provides not only signal detection and identification but also direction finding and localization.
National Instruments and Ettus Research USRPs utilize heterogeneous architectures to process signals both onboard the SDR and on a host PC. Inline processing onboard the SDR is important in cognitive systems, where the output signal is generated in response to spectrum sensing or a received signal. Processing onboard FPGAs can offer multiple benefits, including lower latency (compared to shuttling the data to and from a host computer) and data reduction across the data link or bus, by channelizing or storing only signals of interest.
Hostile electromagnetic environments require SIGINT systems that can detect unknown signals and rapidly adapt to emerging threats. Algorithms with DL capability can be trained to recognize new signals with reduced development time, and, with low SWaP, real-time processing, wideband front ends, and flexible programming, SDR is the optimal architecture for deploying AI-based SIGINT systems.