From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.

When programming multicore applications, special considerations must be made to harness the power of today's processors. This paper discusses pipelining, which is a technique that can be used to gain a performance increase (on a multicore CPU) when running an inherently serial task.
In today’s world of multicore processors and multithreaded applications, programmers need to think constantly about how to best harness the power of cutting-edge CPUs when developing their applications. Although structuring parallel code in traditional text-based languages can be difficult both to program and visualize, graphical development environments such as NI LabVIEW are increasingly allowing engineers and scientists to cut their development times and quickly implement their ideas.
Because NI LabVIEW is inherently parallel (based on dataflow), programming multithreaded applications is typically a very simple task. Independent tasks on the block diagram automatically execute in parallel with no extra work required from the programmer. But what about pieces of code that are not independent? When implementing inherently serial applications, what can be done to harness the power of multicore CPUs?
One widely accepted technique for improving the performance of serial software tasks is pipelining. Simply put, pipelining is the process of dividing a serial task into concrete stages that can be executed in assembly-line fashion.
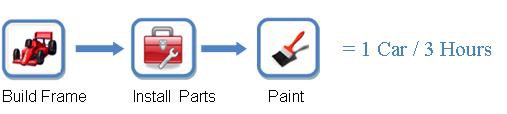
Consider the following example: suppose you are manufacturing cars on an automated assembly line. Your end task is building a complete car, but you can separate this into three concrete stages: building the frame, putting the parts inside (such as the engine), and painting the car when finished.
Assume that the building the frame, installing parts, and painting take one hour each. Therefore, if you built just one car at a time each car would take three hours to complete (see Figure 1 below).
Figure 1. In this example (non-pipelined), building a car takes 3 hours to complete.
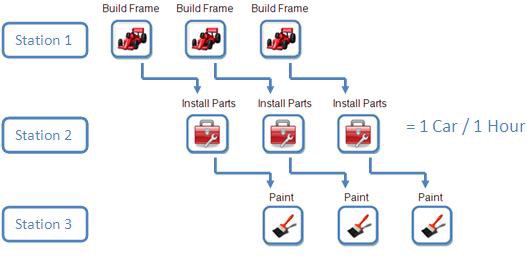
How can this process be improved? What if we set up one station for frame building, another for part installation, and a third for painting. Now, while one car is being painted, a second car can have parts installed, and a third car can be under frame construction.
Although each car still takes three hours to finish using our new process, we can now produce one car each hour rather than one every three hours – a 3x improvement in throughput of the car manufacturing process. Note that this example has been simplified for demonstration purposes; see the Important Concerns section below for additional details on pipelining.
Figure 2. Pipelining can greatly increase the throughput of your application.
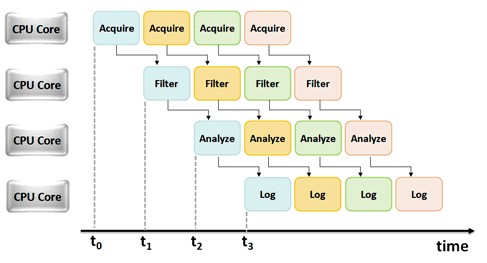
The same pipelining concept as visualized in the car example can be applied to any LabVIEW application in which you are executing a serial task. Essentially, you can use LabVIEW shift registers and feedback nodes to make an “assembly line” out of any given program. The following conceptual illustration shows how a sample pipelined application might run on several CPU cores:
Figure 3. Timing diagram for a pipelined application running on several CPU cores.
When creating real world multicore applications using pipelining, a programmer must take several important concerns into account. In specific, balancing pipeline stages and minimizing memory transfer between cores are critical to realizing performance gains with pipelining.
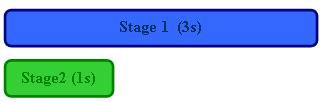
In both the car manufacturing and LabVIEW examples above, each pipeline stage was assumed to take an equal amount of time to execute; we can say that these example pipeline stages were balanced. However, in real-world applications this is rarely the case. Consider the diagram below; if Stage 1 takes three times as long to execute as Stage 2, then pipelining the two stages produces only a minimal performance increase.
Non-Pipelined (total time = 4s):
Pipelined (total time = 3s):
Note: Performance increase = 1.33X (not an ideal case for pipelining)
To remedy this situation, the programmer must move tasks from Stage 1 to Stage 2 until both stages take approximately equal times to execute. With a large number of pipeline stages, this can be a difficult task.
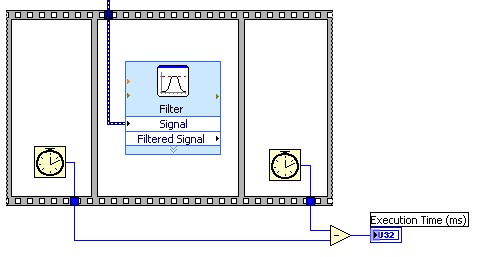
In LabVIEW, it is helpful to benchmark each of your pipeline stages to ensure that the pipeline is well balanced. This can most easily be done using a flat sequence structure in conjunction with the Tick Count (ms) function as shown in Figure 4.
Figure 4. Benchmark your pipeline stages to ensure a well balanced pipeline.
It is best to avoid transferring large amounts of data between pipeline stages whenever possible. Since the stages of a given pipeline could be running on separate processor cores, any data transfer between individual stages could actually result in a memory transfer between physical processor cores. In the case that two processor cores do not share a cache (or the memory transfer size exceeds the cache size), the end application user may see a decrease in pipelining effectiveness.
To summarize, pipelining is a technique that programmers can use to gain a performance increase in inherently serial applications (on multicore machines). The CPU industry trend of increasing cores per chip means that strategies such as pipelining will become essential to application development in the near future.
In order to gain the most performance increase possible from pipelining, individual stages must be carefully balanced so that no single stage takes a much longer time to complete than other stages. In addition, any data transfer between pipeline stages should be minimized to avoid decreased performance due to memory access from multiple cores.