Understanding the Benefits of LabVIEW FPGA and Software-Designed RF Instrumentation
Overview
One way to minimize hardware costs and reduce test time is to use virtual (software) instruments along with modular I/O; however, a new approach—software-designed instrumentation—gives RF test engineers the ability to achieve test time reductions that are orders of magnitude beyond what was previously possible without custom or standard-specific instrumentation.
Read on to learn how you can use NI LabVIEW FPGA to design and customize your RF instrumentation, and discover the advantages software-designed instrumentation can provide in your test systems.
Contents
- Introduction to Software-Designed Instrumentation
- Extend Your LabVIEW Knowledge to Hardware Customization With LabVIEW FPGA
- Contrast Software-Designed Instrumentation With Traditional Approaches
- Leverage Your Software Investment Throughout the Design Cycle
- Future-Proof Through Software-Designed Instrumentation
- Next Steps
Introduction to Software-Designed Instrumentation
For years, test engineers have taken advantage of software packages such as LabVIEW to customize RF measurement systems and reduce cost as opposed to traditional boxed instruments. Not only does this approach provide flexibility, it also gives test engineers the ability to take advantage of the performance provided by the latest PC, CPU, and bus technology.
Still, for many demanding RF test applications the CPU can be a bottleneck; CPUs inherently feature limited parallelism and typical software stacks result in latencies that can reduce test system performance in cases where test stimulus needs to be adjusted dynamically based on measurement values or the state of the device under test (DUT). For optimal RF test system performance, custom instrumentation hardware is desirable in combination with multi-core CPU technology, which gives test system designers the ability to achieve a balance of low latency and high throughput that can dramatically reduce test times.
While off-the-shelf instrumentation hardware has traditionally been fixed in capability, National Instruments is leading the way in providing more open and flexible measurement devices based on field-programmable gate array (FPGA) technology. In short, FPGAs are high-density digital chips that the user can customize, giving test engineers the ability to directly incorporate their custom signal processing and control algorithms into measurement hardware. The result is off-the-shelf RF hardware that incorporates the best of both worlds: fixed high-quality measurement technology with guaranteed, traceable measurements in the latest form factors, along with user-customizable logic that is highly parallel, provides low latency, and is tied directly to I/O for inline processing and tight control loops.
The NI vector signal transceiver (NI VST) is an example of this hardware. This device combines the functionality of a vector signal generator with a vector signal analyzer, and also contains a user-programmable FPGA for real-time signal processing and control. With the added flexibility of an FPGA, the VST is ideal for custom triggering, DUT control, parallel measurements, and real-time digital signal processing (DSP).
Extend Your LabVIEW Knowledge to Hardware Customization With LabVIEW FPGA
Although FPGAs are widely available both for custom board designs and as part of off-the-shelf devices, user-customizable FPGAs have not been widely adopted in off-the-shelf RF instrumentation equipment to date. This is largely because of the specialized knowledge required to program these devices; hardware description languages, or HDLs, generally require a steep learning curve and are restricted to digital design experts.
The LabVIEW FPGA Module makes the latest FPGA technology accessible to a wide set of engineers and scientists. Using graphical programming, you can implement logic that defines the behavior of an RF instrument in hardware, as shown in Figure 1. In fact, the graphical dataflow nature of LabVIEW is well suited for implementing and visualizing the type of parallel operations that can be implemented in FPGAs. Although there are differences in programming FPGAs with LabVIEW that require additional knowledge, the learning curve is substantially lower than with HDLs.

Figure 1: With the NI LabVIEW FPGA Module, you can use familiar LabVIEW code to customize instrumentation hardware. For RF applications, you can start from pre-created sample projects and add modifications for custom triggering, DUT control, signal processing, and more.
Several LabVIEW FPGA sample projects are available as a starting point for your RF applications and can be used with devices such as the NI VST devices. Specifically, you can customize the FPGA according to an instrumentation data movement paradigm (with customizable start, stop, and reference triggers presented through an interface similar to a vector signal analyzer or a vector signal generator), or according to a streaming paradigm (ideal for inline signal processing or record and playback applications).
Contrast Software-Designed Instrumentation With Traditional Approaches
Taking advantage of FPGA-based hardware in your RF measurement systems can provide a number of benefits ranging from low-latency DUT control to CPU load reduction. The following sections describe various usage scenarios in more detail.
Improve Test System Orchestration With Interactive DUT Control
In many RF test systems, the device or chip under control must be controlled via digital signals and custom protocols. Traditional automated test systems have the ability to sequence through DUT modes, taking the needed measurements in each stage. In some cases, automated test equipment (ATE) systems incorporate intelligence to progress between DUT settings according to the measurement values received.
In either scenario, software-designed instruments that incorporate an FPGA can result in cost and time savings. Consolidating both measurement processing and digital control into a single instrument reduces the need for additional digital I/O in the system, and avoids the necessity to configure triggering between instruments. In cases where the DUT must be controlled in response to measurement data received, software-designed instrumentation can close the loop in hardware, reducing the need for decisions to be made in software at a significantly higher latency.
Decrease Test Time and Increase Confidence With In-Hardware Measurements
Although today’s software-based test systems can perform a limited number of measurements in parallel, software-designed instrumentation is limited only by the available FPGA logic. Dozens of measurements or data channels can be processed with true hardware parallelism, removing the need to choose between measurements of interest. Computations such as fast Fourier transforms (FFTs), filtering, and modulation/demodulation can be implemented in hardware, reducing the amount of data that must be passed to and processed by the CPU. With software-designed instruments, functionality such as real-time spectral masking can be achieved at a significantly higher rate than with traditional boxed instruments.
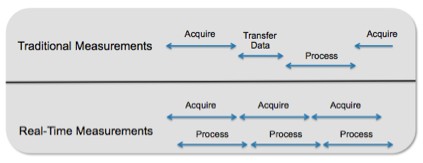
In addition, the low latency associated with performing measurements in hardware means that in the same time a standard test system may have required to perform a single measurement, tens or hundreds of live measurements can be taken and averaged together, as shown in Figure 2. This translates to improved quality of test results and increased confidence in your RF measurements. Furthermore, since measurements can be taken continuously in hardware and sampled periodically from a host test application, you can be confident that you will never miss important data.
Figure 2: With software-designed instruments, you can continually acquire data and perform measurements (sampling results periodically) rather than stopping the acquisition process to transfer information.
Reach Optimal Test Conditions Quickly With Closed-Loop Feedback
Certain classes of RF test require that DUT settings or environmental and manufacturing process quantities are varied according to the measurements received; this requires a closed-loop system that is often limited by the latency of the software stack. In many cases, the loop can be closed directly in hardware, eliminating the need for subsequent setpoints to be computed using the CPU. This can reduce closed-loop test times from ten of seconds to fractions of a second.
Focus on Data of Interest With Custom-Defined Triggers
Options for low-latency trigger behavior are traditionally fixed according to the instrumentation hardware being used. However, with software-designed instrumentation, you can incorporate custom triggering functionality into your device to quickly zero in on situations of interest. Flexible hardware-based triggering means that you can implement custom spectral masks or other complex conditions as criteria for either capturing important measurement data or activating additional instrumentation equipment. And, by selecting data of interest in hardware you can free up the CPU for other important tasks.
Leverage Your Software Investment Throughout the Design Cycle
While this paper focuses primarily on RF test, engineers are increasingly reusing IP between the design and test stages, which can reduce both time to market and the overall expense of test considerably. With LabVIEW FPGA, digital signal processing algorithms can be defined and then reused as part of device or component verification—eliminating the need to generate test code from scratch. This ensures accelerated test development, which provides the ability to test earlier in the design cycle, as well as more complete test coverage, as shown in Figure 3.
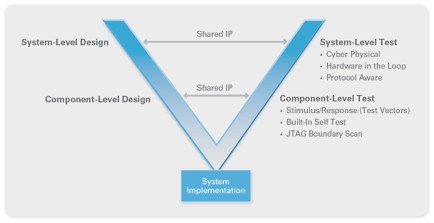
Figure 3: IP can be reused between the design and test stages, reducing test development time and providing more complete test coverage.
Future-Proof Through Software-Designed Instrumentation
There is no doubt that vendor-defined instruments and fixed capability off-the-shelf instruments will remain available for years to come. However, just as increasingly complex RF devices and pressure on time to market has lead to the rise of software-based instrumentation systems, the continuation of these trends means that software-designed instruments will play an increasingly important role in RF test, and test instrumentation in general, in the near future.
Software-designed instrumentation provides the highest level of flexibility, performance, and future-proofing possible to date with off-the-shelf hardware. As your system requirements change, software-designed instruments mean that not only will your software investment be preserved across different pieces of modular I/O, but also that your existing I/O can be modified according to the application at hand.