Kinect LabVIEW Interface Using Microsoft Kinect API
- Subscribe to RSS Feed
- Mark as New
- Mark as Read
- Bookmark
- Subscribe
- Printer Friendly Page
- Report to a Moderator
Code and Documents
Attachment
Overview
The following is a description of a Kinect API built in LabVIEW. The library was designed using the typical Initialize, Read, Dispose application design and includes a Demo VI which can be used as a starting point for understanding the connection between the various subVIs. An explanation of the design and implementation of the API will be be given in this document as well as troubleshooting steps and future potential expansions to the interface.
The Microsoft Kinect API Overview
Microsoft released a .NET Kinect interface in early 2011 to much celebration from the hacker community. It's release presented an opportunity to use the existing LabVIEW infrastructure to design a simple interface in LabVIEW using the built in .NET functionality which would allow LabVIEW users to experiment with the Microsoft Kinect. This interface was rapidly developed and demonstrated at NI Week both in the Hack the Kinect and Other Cool Sensors segment and on the Clearpath Husky in the Robotics Pavilion.
API Architecture
The Microsoft Kinect has both audio and video interfaces. This API only features access to the Depth and Video images (with the capability to easily include the Skeletal Tracking component in a future release). Not a full-features API, the release is intended as a starting point for developers interested in using the Kinect in applications. The library has been tested in both LabVIEW 2010 and 2011 and requires the NI Vision library to operate.
The Runtime and ImageStream Objects
There are two primary objects of concern in the API. One is the Runtime, and the other is the ImageStream. The Runtime object provides a simple method of initializing the Kinect to output whatever streams are desired. It contains both an Initialize and Uninitialize method which must be called before and after execution respectively. You can also access the various ImageStream objects as properties of the Runtime. This, of course, limits the number of Kinects you can currently operate with the API to one.

The ImageStream objects can then be Opened with whatever settings are desired from the user. For the sake of this API, only the configuration with 320x240 Depth and 640x480 Video were tested. Other implementations are, of course, possible but have not been tested in this implementation. The framework is in place for those configurations to operate with only minor modifications.

The DepthFrameReady and VideoFrameReady Callback Events
Once the appropriate ImageStream objects are Opened, the application can register event callbacks which will be executed whenever a frame is ready. The SubVIs (which are not used in the main application) Handle Depth Image.vi and Handle Video Image.vi are used as callbacks for the DepthFrameReady and VideoFrameReady event respectively. Each time the Kinect signals that there is a new frame ready, that event is executed.
The actual processes within these .NET event callbacks are very simple. The event arguments are processed from the ImageFrame object and PlanarImage object and converted into an IMAQ image. The image is then available to the user. The current design uses a Queue as a structure to store images as they arrive. These Queues can then be managed as desired (as will be demonstrated in a later section) to keep memory usage to a minimum and allow for the smoothest camera operation.
A new Event Callback could be registered for the Skeletal information which would follow the same architecture as the other two events and would allow the user to interface with that part of the Microsoft Kinect API. The Skeletal Frame is not included in this release.
Object Disposal and the Dangers of Unclosed .NET References
Many LabVIEW users often find it convenient to use the Abort button when operating their applications for testing purposes. It is VERY important that all .NET references are appropriately closed when accessing the Kinect. If the references aren't closed, unrecoverable errors (which would require a restart of LabVIEW) as well as crashes can happen. Please always save your applications while working with .NET references which may be leaked due to premature application termination.
The Get Functions
Two Get functions are included with the API which allow the user to access the image frames as they become available. These frames are, as mentioned previously, being loaded into a queue which is accessible to the user. The Get Video Image.vi and Get Depth Image.vi functions allow for the simple management of those queues.
Because the availability of an image is asynchronous to the Get calls the user is making on the front end, there is a possibility of both buffer overflow and underflow problems when operating the front-end VIs. This is handled by providing the user with the Wait For Next Image? boolean input. The following is a simple explanation of the values obtained given the state of the buffer and the value of that boolean variable:
- Wait For Next Image? is False AND the Buffer Has Images -> The next image in the queue is returned.
- Wait For Next Image? is False AND the Buffer is Empty - > The previous image is returned (or an empty image if first call).
- Wait For Next Image? is True AND the Buffer Has Image -> The next image in the queue is returned.
- Wait For Next Image? is True AND the Buffer is Empty -> The program waits for the next image and returns it when ready.
This design applies to both the Depth and Video Get functions and should be followed if the Skeletal Frame is added to avoid incongruous architectures.
The Image Is New? output provides the user with a simple boolean value which tells them if the image they have been returned is a new image. The user is also provided with a simple Flip Image? input which will flip the image to the camera normal reflection (the Kinect is naturally flipped so you view yourself as if in a mirror). This option should minimally effect performance and both of the options can be tuned (as well as the buffer size for each queue) to give the best output for an individual system.
The Demo

The Demo provides a basic overview of the proper implementations of the various functions in the library as well as a performance monitor. The two images (Depth and Video) are provided to the user via IMAQ Picture Controls and the basic Flip and Wait options are presented as buttons. The New Image? displays for each queue are also given to the user as a reference (notice that when the application is set to wait for next images the New Image? indicators will always be true).
The performance measurements show iteration delay, mean delay over 100 iterations and approximate FPS. The iteration time is displayed on the graph at the bottom. The mean delay is calculated as a standard moving average.
Notice that the code is fairly well defined into three sections. The top most section is the performance measurements:

The next section down is the 3D Conversions (described in the next section):
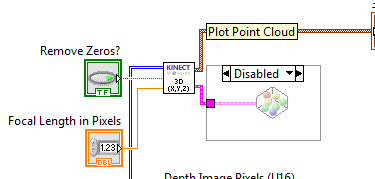
The final (and most important) section demonstrates the program flow for using the API:

The 3D Conversion Easter Egg
Used as part of the Clearpath Robotics Husky Robot demoed in the Robotics Pavilion at NI Week, a conversion from the Depth Image to a 3D representation of that image was devised and included as an easter egg inside the library and demo. It is disabled by default, but if the Diagram Disable Structure is removed you can access the 3D representation of the depth image.

This 3D conversion is particularly convenient for robotics applications where obstacle avoidance is desired.
A single optimization parameter is included in this function which allows for the removal of 0 values (values which are too close or too far from the Kinect to appear in the Depth Image) from the processing. This often substantially improves the performance of the 3D conversion.
A single configuration parameter is included in this function which allows for the custom application of the camera Focal Length. This value depends on the resolution of the camera and is configured correctly for the current depth image settings. If the resolution of the depth image is changed, the focal length parameter will need to be reset.
Troubleshooting Steps and Known Issues
Although the API works very well, initial setup can sometimes cause issues. The following is a list of suggestions for steps to address problems with initially running the demo as well as some known issues:
- If you receive errors indicating there is a problem with linking to the DLL, go into the Initialize VI and reconfigure the Runtime constructor node to point to the appropriate DLL on your system.
- Make sure you have .NET 4.0 installed and place the attached .config file next to your LabVIEW.exe executable in your National Instruments directory. Upon the development and release of this API, LabVIEW does not currently support .NET 4.0 . This configuration file will allow LabVIEW to support the features required to make the API function.
- DO NOT prematurely abort the application before the Dispose function is called. This can cause .NET reference leaks and will almost certainly prevent the application from running again without restarting LabVIEW. It is also possible for unclosed references to crash LabVIEW under certain circumstances.
- DO NOT premature abort the application before the IMAQ Dispose function is called. Although this will not cause any crashes or errors, it can cause severe memory leaks which can reduce system performance until LabVIEW is restarted or IMAQ Dispose (with the All Images? value set to true) is called.
- Try reinstalling the Microsoft Kinect API if problems persist.
Future Work
There are significant expansions necessary in order to make this a fully implemented Kinect API. The following is a short list of known improvements and feature additions which could be added at a later date by any interested parties:
- Optimize the memory control of the Get Depth Image.vi and Get Video Image.vi functions (particularly the Video image could use IMAQ functions which take multidimensional array inputs and automatically write the various color planes to memory instead of building them individually).
- Add Skeletal Frame to the API. The output of the skeletal function is an array of points. The structure of these points into an actual skeletal frame would have to be programmed explicitly as it is not explicitly defined in the structure of the points.
- Full resolution support and optimization could be added to have a well tested API for all supported resolutions.
- Audio could be added as well as interfaces to all supported audio features inside the Microsoft Kinect API.
References and Special Thanks
- Microsoft Kinect SDK Documentation
- NUI API and Programming - Kinect for Windows SDK
- Microsoft Kienct SDK Download
- Special Thanks to Clearpath Robotics and Peter Gayler for their contributions.
Example code from the Example Code Exchange in the NI Community is licensed with the MIT license.
