From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
Data from various sources may use different units, might use different nomenclatures, or may be corrupt. Automatically standardize metadata, verify data quality, and convert to TDMS to ensure data is consistent regardless of origin with SystemLink TDM Data Preparation Add-on. This whitepaper discusses the benefits of using this SystemLink software add-onto standardize and enrich your raw measurement data files.
If we start with a raw data set that includes data from multiple sources we typically run into 4 problems:
Figure 1: The Inconsistent Data Problem.
If these issues exist in the raw data, they ultimately result in inconsistent analysis for the following reasons.
Multiple file formats and sources are used in a test setup for a variety of reasons, but is most often attributed to different groups within the company testing subsystems or components. These different groups could use different hardware vendors or different processes. Unless an automated process is used, consolidating data from multiple file formats is a tedious and manual process that leaves room for possible human error and wasted time.
Data querying tools, like SystemLink TDM DataFinder Module, can reduce the time and effort it takes to find the data you need to analyze. Creating a query requires metadata names and values to be used. If these metadata names and values don't match and extra queries aren't used to expand the search results, the data won't be found and analyzed.
Incorrect engineering units and erroneous raw data can lead to drastic changes in the results of analysis procedures resulting in invalid results. Different engineering units can be a serious issue for teams located in different sites where a standardized unit hasn't been agreed upon. The problem also tends to happen when testing is completed by other groups outside of the company. Sensor failures, data corruption, or human error can also have the same effect. These problems are typically only realized after a critical error occurs.
The Data Preprocessor, included with the SystemLink Data Preparation Add-on, automatically standardizes, enriches, and validates data before using it for other purposes. By using the Data Preprocessor, you eliminate time wasted upfront in preparing your data files and save yourself from making costlier mistakes further downstream.
The Data Preprocessor has six configurable steps:
Figure 2: The Data Preprocessor has six configurable steps.
The 64-bit versions of DIAdem Advanced and Professional provide the interface to configure the above Data Preprocessor steps. At the end of the configuration, DIAdem saves a configuration file (*.DPP), which you upload to the DataFinder Server using the Server Manager web client. Afterward, the Server Manager becomes your interface for starting and stopping the preprocessor, as well as pointing it to the location of raw data to process.
The 64-bit versions of DIAdem Advanced and Professional provide the interface to configure the above Data Preprocessor steps. At the end of the configuration, DIAdem saves a configuration file (*.DPP), which you upload to the SystemLink Server using the SystemLink web client. Afterward, the web client becomes your interface for starting and stopping the preprocessor, as well as pointing it to the location of raw data to process.
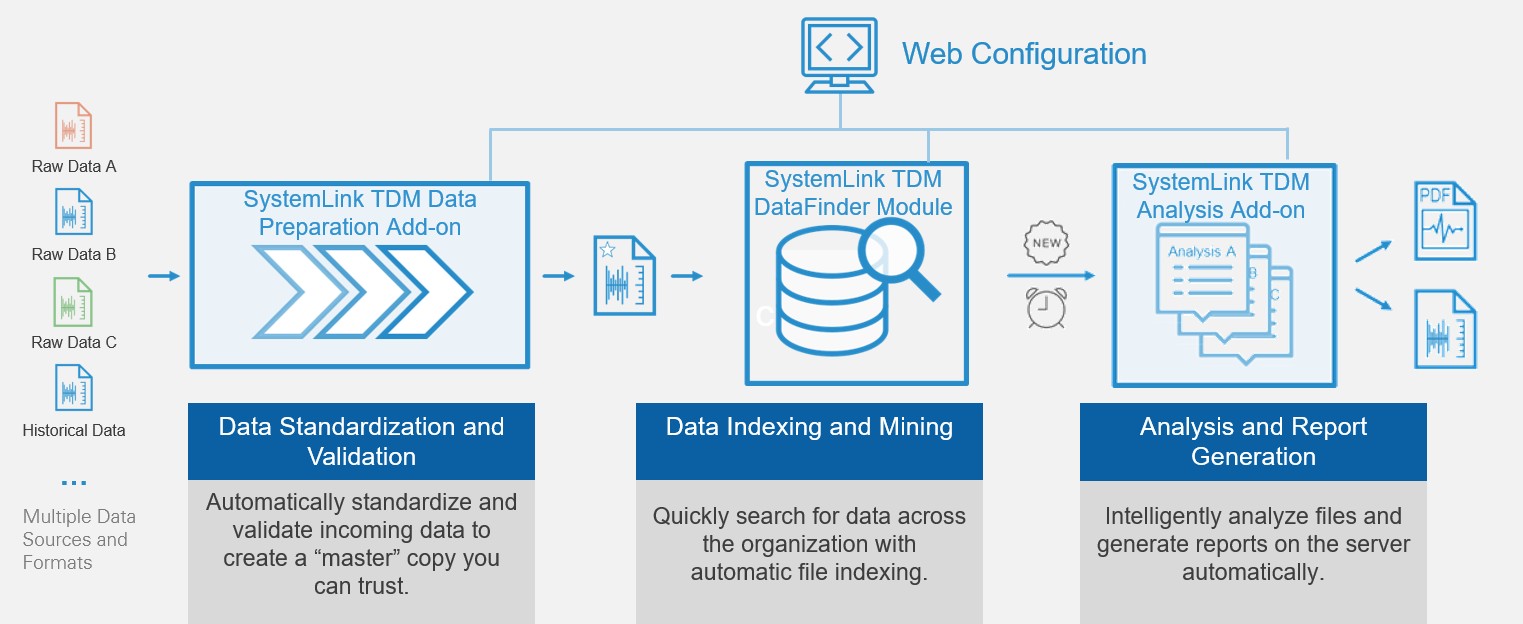
The SystemLink Analysis add-on makes it possible for you to extract the maximum value from large amounts of data in minimal time by harnessing the power of server technology to analyze large amounts of data and generate reports. When used together, SystemLink Data Preparation Add-on ensures data is standardized and verified with a Data Preprocessor before analysis. The SystemLink TDM DataFinder Module, the core of the SystemLink measurement data management solution, builds and maintains an automated index of your data that enables the SystemLink Analysis Add-on to perform complex search queries on data distributed throughout the organization for automatically triggered analysis routines.
Figure 3: SystemLink TDM DataFinder Module and Add-ons work together to create a fully automated data management workflow.
SystemLink delivers measurable improvements in operational efficiency and productivity by providing you with a centralized web-based management interface for connected devices, software, and data. Although aligned with NI products such as LabVIEW, TestStand, and hardware systems, SystemLink also offers an open architecture for incorporating a wide range of third-party software and hardware technologies. SystemLink TDM DataFinder Module and Add-ons are components of the SystemLink product family. To learn more about the other capabilities of SystemLink, visit ni.com/systemlink.