From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
From Friday, April 19th (11:00 PM CDT) through Saturday, April 20th (2:00 PM CDT), 2024, ni.com will undergo system upgrades that may result in temporary service interruption.
We appreciate your patience as we improve our online experience.
Today’s complex products require data acquisition throughout the complete design, development, and verification process. Test engineers continue to face the challenge of testing increasingly complicated designs with ever-shrinking timelines and budgets to meet consumer demand for higher-quality products at lower prices. From the cost of simulation systems, data acquisition hardware, and automation systems to the associated personnel required to perform and analyze the tests, companies make a significant investment in the data they collect. However, when planning a complete test system, companies often fail to design an all-encompassing solution; they do not fully consider and invest in ways to manage their data once they collect it. Increasing microprocessor speed and storage capacity and decreasing hardware and software costs have resulted in an explosion of collected data being stored in files and databases. While technology is enabling faster and richer data retention, managing and making good use of this data remains the real challenge. More than ever in today’s fiercely competitive business environment, companies need to rapidly turn test and simulation data into usable information to efficiently drive product development and reduce time to market.
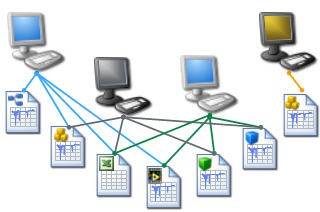
The challenges involved in building and maintaining scalable data management systems have caused many companies to continue managing their critical data assets by using simple file- and folder-naming conventions. Though the file and folder approach requires no up-front cost, you realize this cost many times over in the long run when you must manually search through deep directory structures to find the data you need. Often this data is stored on different machines and in different file formats, adding even more complexity to your situation. Correlation of data and test results across multiple machines and formats under these circumstances can be challenging and time consuming. File- and folder-naming data management systems are highly ineffective, resulting in lost productivity, and are easily corrupted when files are inadvertently moved out of their designated folders or renamed.
Figure 1. File and Folder Approach across Multiple Test Machines
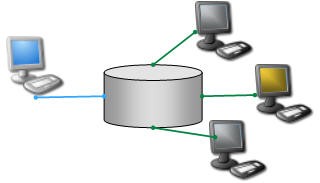
At the opposite end of the spectrum is the approach of using dedicated databases for managing technical data. Because of their reputation for organizing data for easy search and retrieval, databases have garnered the attention of many test engineers as one way to manage their test data. However, there are several drawbacks to the implementation of a standard database such as Oracle or Access for your data management system. These databases are not set up to work out of the box with your test data; first you need to complete a significant amount of data model and database design work that can take months of preparation and planning. For larger solutions, the initial cost of setting up a database solution can easily reach six-digit dollar figures; more important is the often overlooked ongoing maintenance required to keep databases up and running. Extra time and effort is required to expand the database design and custom client software every time your test needs change. This maintenance and scaling over time not only costs more and more money but usually requires you to engage IT experts who know how to keep these systems running. Often, the IT group does not have the bandwidth to help test groups.
Figure 2. Database Approach of Storing Data in a Central Location
In the end, neither the file and folder approach nor the database approach meets the needs of most test groups. While they may seem like viable solutions at design time, you are still left with maintenance headaches and inefficiencies as your test needs change over time and you continue to store more data.
National Instruments recognizes that engineers and scientists face these data management challenges every day when designing and improving their test systems. Whether your current solution involves spending hours a week tediously searching through directories and files to find just one specific test or redesigning an expensive database and client application to accommodate additional information, both approaches lack the same thing – engineering intelligence from test data. You must spend a lot of time designing and performing tests that allow you to move quickly from test data to test results. All too often today, you are expected to make the crucial transition from test data to test results without proper data management tools; therefore, NI has developed a data management solution to meet these challenges and make it easier and faster for to move from data collection to usable results.
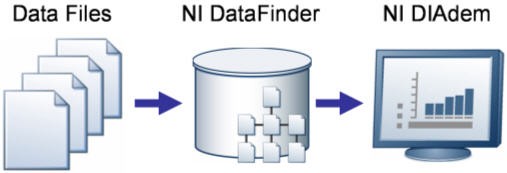
Figure 3. The NI TDM Solution Consists of Three Components
NI has identified three key pieces that complete the data management puzzle: flexible and organized file storage, self-scaling hybrid data index, and an interactive post-processing environment. As a result, the NI technical data management (TDM) solution consists of three components: the TDM data model for storing descriptive information with your test files, NI DataFinder for organizing and managing your test data regardless of file format, and DIAdem and the LabVIEW DataFinder Connectivity VIs for searching, analyzing, and reporting. Though many engineers already have components in place for raw data file writing as well as analysis and reporting, with the lowest common denominator being saving ASCII files and performing analysis in Excel, most engineers are lacking the middle component, NI DataFinder, to complete their data management approaches.
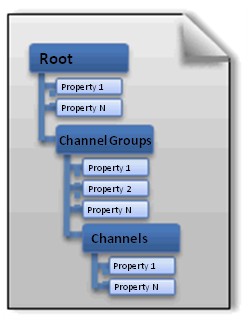
The foundation of the NI data management solution involves storing rich meta information with your data, which is then searchable using NI DataFinder. With the NI TDM data model, you can easily store properties and organize your data hierarchically within your test file. TDM and TDM Streaming files, written natively using DIAdem, LabVIEW, LabVIEW NXG, or LabWindows™/CVI, or Measurement Studio provide three levels of hierarchy to structure your test data – file, group, and channel levels. The TDM data model removes the burden of designing and maintaining your own custom file format. Designed to scale with your needs, the TDM data model provides the most efficient way to properly document your test and simulation data on the NI platform. A rich and comprehensive set of properties associated with your files, groups, and channels dramatically increases the range of possible search conditions.
Figure 4. The TDM Data Model for Saving Well-Documented Test Data
Once you have properly documented your data with properties, NI DataFinder gives you the out-of-the-box ability to search and mine your test data without the headache and expense of setting up and maintaining a large database. With NI DataFinder, you can perform Internet-like searches across all your data files, regardless of format and location within your company intranet. Simply install NI DataFinder with DIAdem, point it to the location of your data files, and within seconds you can search for your files just as you would search for information on the Internet.
NI DataFinder does this by automatically building and maintaining an index of all files that meet the file type and location criteria in the NI DataFinder configuration. You can use properties that are automatically stored in the NI DataFinder index in query conditions. When a valid data file is created, deleted, or edited, NI DataFinder automatically notices and reindexes the hierarchy and properties of the file. When you save properties not yet in NI DataFinder in a newly created file, these properties are automatically added to the index. NI DataFinder dynamically manages its own data tables and updates them based on file events and the contents of each file. Therefore, unlike many expensive database solutions, you can change and add information as your needs change without redesigning your data management solution.
The final component of the NI TDM solution for moving quickly between raw data and engineering results is DIAdem for posttest analysis and reporting and the LabVIEW DataFinder Connectivity VIs for creating custom applications with the NI DataFinder technology. Using DIAdem, you can take advantage of hundreds of built-in engineering analysis functions to extract meaningful results from your raw data, and then share these results with easy-to-build, reusable report templates. DIAdem also provides a built-in interface to both DIAdem DataFinder and SystemLink TDM DataFinder Module. Therefore, you can run interactive searches within DIAdem as well as save and automate your queries. Within one environment, you can mine your data for trends, analyze these trends, and then save these results to reports. Also, using the LabVIEW DataFinder Connectivity VIs, you can create custom applications based on your needs and deploy them out to clients. Based on the size of your test group and the amount of data you are collecting, there is an NI DataFinder solution to meet your needs.
With this pivotal middle component of the NI TDM solution, you can customize your data management and mining solution. Once you have installed NI DataFinder, configure it to search through particular folders and directories for specific file types. NI DataFinder then automatically builds a fully searchable index of the metadata of these files. You can add and remove search areas with one click as well as configure NI DataFinder to index your own custom file formats.
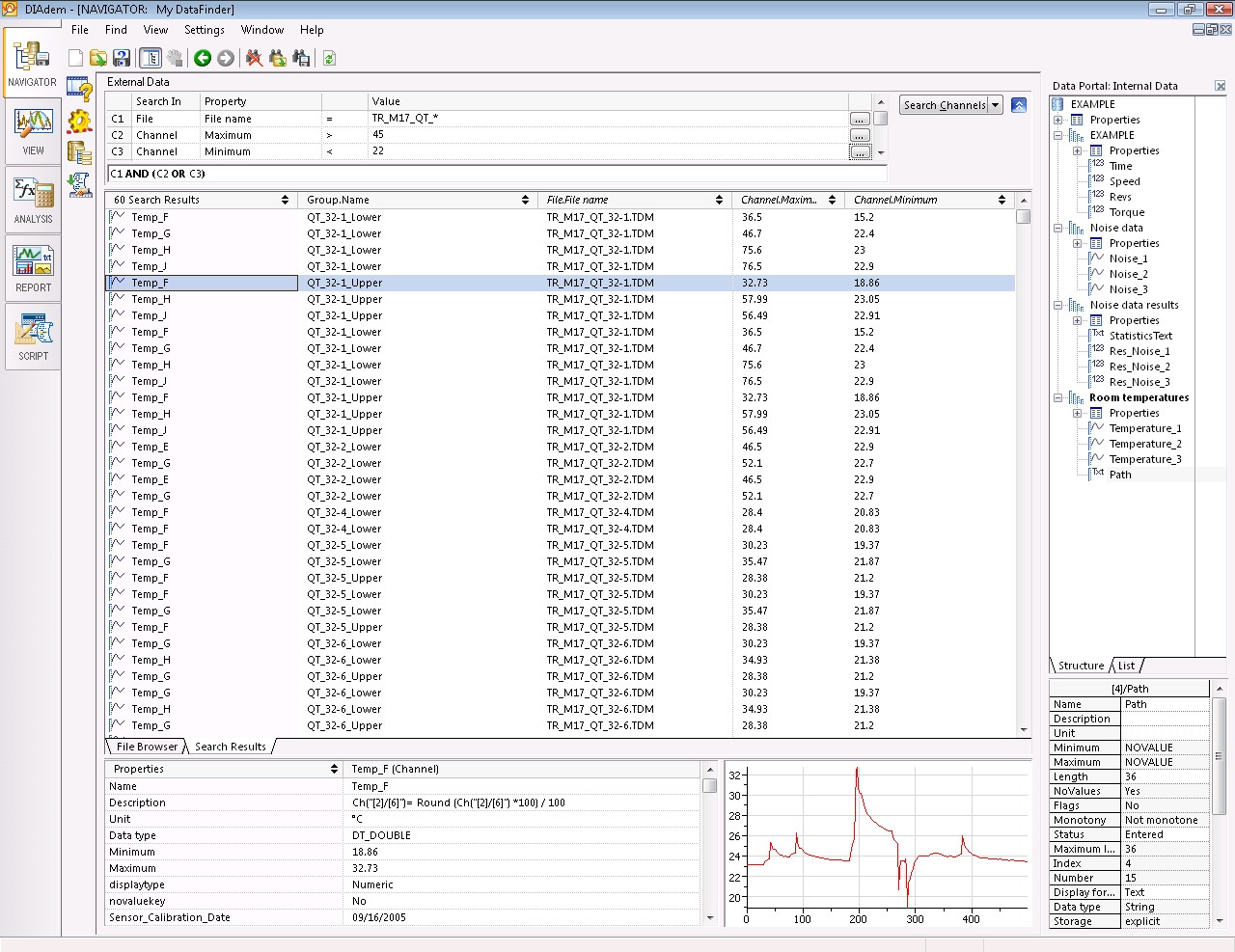
Once you have set up your search areas, you can query your data from two interfaces – the simple and advanced search. In the simple search, you type in words or values to run a quick search and return files that contain all of these values somewhere within the file. Using the advanced search, you can search for properties on specific hierarchy levels (file, group, and channel) and return your results as channel, group, or file listings. For example, you could search on “Group.Test_Status = fail” and return all the groups that contain this property and failed. In this case, you can search for all channels across multiple files and formats that meet your search criteria and then load just the returned channels from each of the files. You now have more control of your data because you only load the channels or properties of interest from each file.
Figure 5. Using the Advanced Search, you can quickly find trends and correlations within your test data.
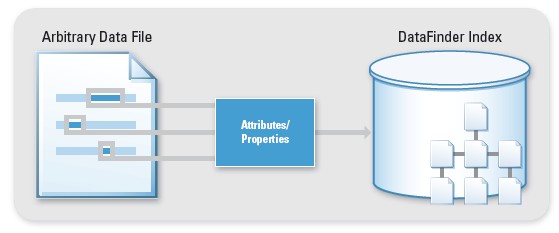
Out of the box, NI DataFinder automatically indexes TDM and TDM Streaming files within the search areas you specify. However, you may have a number of existing files in different formats that you also want to search using NI DataFinder. For these, you can use a DataPlugin to load your files in DIAdem or LabVIEW. Once you have a DataPlugin for an arbitrary data file, you can index, search, and load it just like a TDM file. There are more than 75 free DataPlugins available for download at ni.com/dataplugins. You also can use the DataPlugin API, which includes examples, to help you write your own DataPlugin for your custom formats.
Figure 6. The index stores all the descriptive information included with a file, so you can mine and search on these values.
As mentioned previously, the NI DataFinder index is completely self-configurable and self-maintainable. Once you point NI DataFinder to the folders and directories you want to index, it builds the index of all the metadata stored within the files. As you collect more test data and store the files within the search areas, NI DataFinder receives a Windows File Event notification and automatically indexes the new data files. NI DataFinder also monitors file events that are triggered when a file is changed or deleted, so you always have the most up-to-date index of your data. NI DataFinder has a number of native properties, such as name and description, which are stored with all files. However, in many tests that you perform, you may want to store your own custom properties such as Test Status or Test Procedure that are also indexed and searchable. Because NI DataFinder is a completely self-scaling index of all your metadata, the index automatically adapts to these new properties and indexes them along with the native properties. With a traditional database solution, adding new properties can be a costly undertaking if the database is not designed properly from the beginning.
NI offers two data management options to meet your needs: My DataFinder and SystemLink TDM DataFinder Module, formerly known as NI DataFinder Server Edition. My DataFinder, included in all packages of DIAdem, helps you search data stored locally on your machine or on a network. Larger groups accessing data across multiple machines with limited network bandwidth and numerous file formats require a more unified and robust approach.
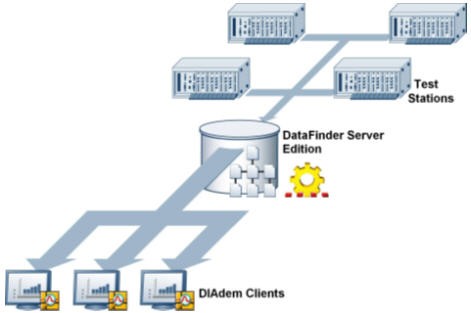
SystemLink TDM DataFinder Module is software installed on a server machine, but it is designed for easy installation and configuration without the need for IT involvement. Just like the local My DataFinder, you configure particular search areas and file formats for indexing. Once you have configured these search areas, multiple client computers can have simultaneous visibility to collected test data using the one central shared index on the server machine. Your entire group or department can find and analyze data without the hassle of searching through files across several machines. Just select to connect to SystemLink TDM DataFinder Module, and you are immediately connected to the server index just as if you were connected to your local My DataFinder index.
Figure 7. SystemLink TDM DataFinder Module centralizes the metadata from multiple test stations so you can easily access and mine it with multiple clients simultaneously.
SystemLink TDM DataFinder Module offers faster and easier access to data stored not only on your local machine but also on all your network machines. Expedited access to more data helps you focus on the important tasks of design and analysis instead of wasting valuable time and resources searching for data. Besides being able to find the data you are looking for, you can inspect multiple files at once to find important trends or anomalies.
From the ability to support multiple concurrent connections to built-in user management and archiving capabilities, SystemLink TDM DataFinder Module provides numerous advantages over NI DataFinder for large groups. For more information on how SystemLink TDM DataFinder Module can further streamline your simulation and test data management solution, read the SystemLink TDM DataFinder Module technical white paper.
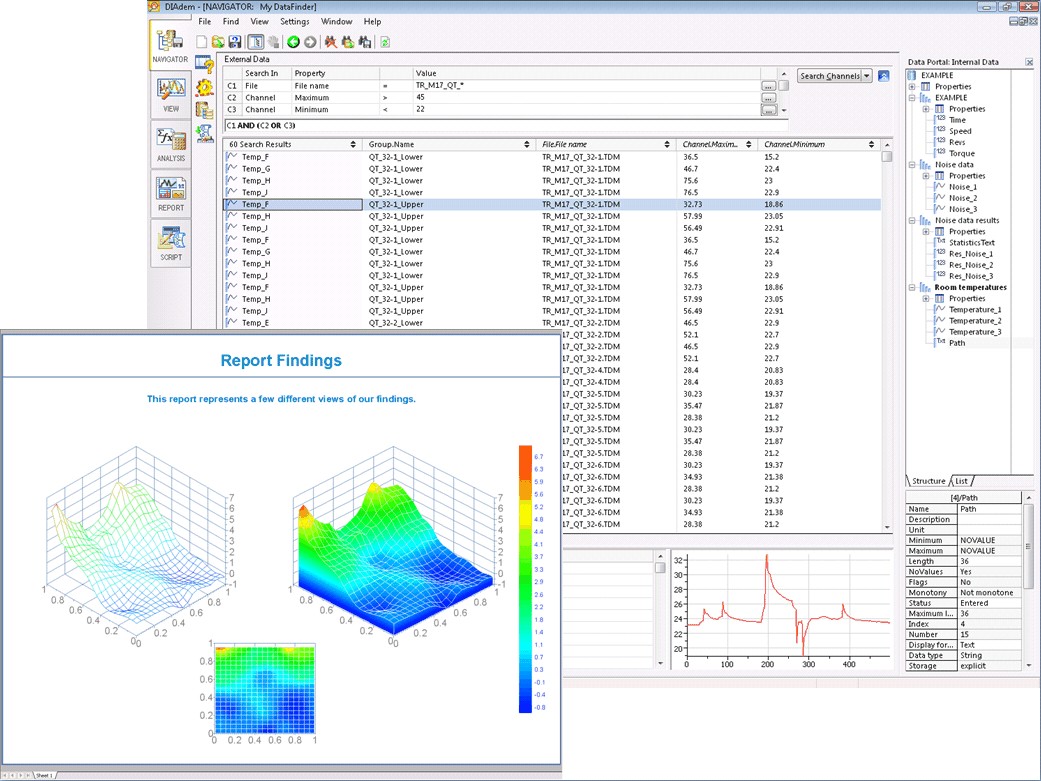
The last element in the NI TDM solution is the query and reporting client, either DIAdem or applications built with the LabVIEW DataFinder Connectivity VIs. DIAdem provides a built-in user interface to NI DataFinder to help you search through all indexed data files with a simple Internet-like keyword search or a powerful advanced search. DIAdem combines this data-searching functionality with general-purpose data visualization, analysis, and reporting environments. Once you have found the data you need – either through DIAdem DataFinder or SystemLink TDM DataFinder Module – you can analyze the data using hundreds of built-in engineering analysis functions and create consistent reports to share your results. DIAdem provides a customizable postprocessing solution due to its ability to export reusable templates from your most commonly used queries, reports, and interactive views. In addition to using DIAdem and NI DataFinder as a data-handling environment, you can fully automate them with VBScript and custom dialogs. Engineers often use this solution as the basis for fully customized data management and evaluation applications.
Figure 8. DIAdem for Data Postanalysis, Reporting, and Automation
The LabVIEW DataFinder Connectivity VIs give you the ability to create your own custom applications for accessing the NI DataFinder. The API allows you to programmatically perform keyword and parametric searches of your test data as well as configure the DataFinder on the fly. Using the LabVIEW DataFinder Connectivity VIs, you can create your custom data management applications and then deploy them to multiple clients in your organization.
The NI data management solution covers all the bases of a scalable, cost-effective, search-ready data management system. You no longer need to worry about the details of file parsing, data model and data table structure, database management, search GUI design, or support from outside groups such as the IT department. All you have to do is use the easy-to-configure My DataFinder or SystemLink TDM DataFinder Module to automatically create and maintain a data index. Finally, you can take advantage of the DIAdem built-in search GUIs and easy-to-use interactive data analysis and reporting environment to quickly turn your saved data into the reports and result information you need. Or, create your own applications for searching using the LabVIEW DataFinder Connectivity VIs.
The mark LabWindows is used under a license from Microsoft Corporation. Windows is a registered trademark of Microsoft Corporation in the United States and other countries.